Illustrative introductions on dimension reduction
"What is your image on dimensions?"
....That might be a cheesy question to ask to reader of Data Science Blog, but most…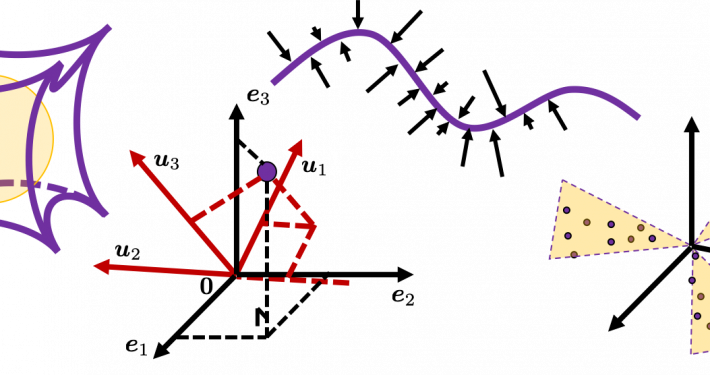
Spiky cubes, Pac-Man walking, empty M&M's chocolate: curse of dimensionality
"Curse of dimensionality" means the difficulties of machine learning which arise when the dimension of data is higher. In…
Back propagation of LSTM: just get ready for the most tiresome part
First of all, the summary of this article is "please just download my Power Point slides and be patient, following the equations."…
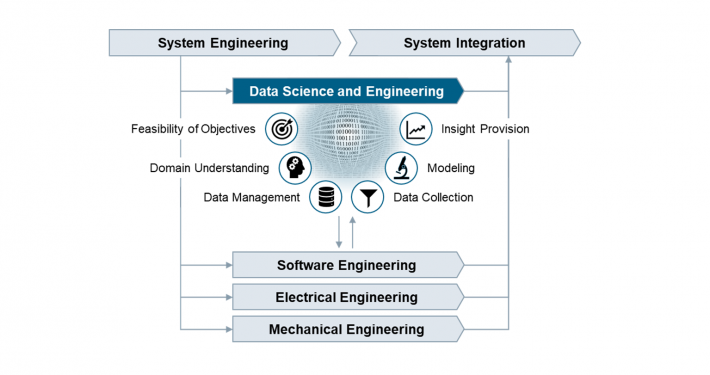
How to develop digital products and solutions for industrial environments?
In this article, we substantiate why Data Science and Engineering should be introduced as new engineering discipline in the Product Lifecycle Management process.
Understanding LSTM forward propagation in two ways
*This article is only for the sake of understanding the equations in the second page of the paper named "LSTM: A Search Space…
Hypothesis Test for real problems
A statistical hypothesis is a belief made about a population parameter. This belief may or might not be right. In other words, hypothesis testing is a proper technique utilized by scientist to support or reject statistical hypotheses. The foremost ideal approach to decide if a statistical hypothesis is correct is examine the whole population.

Must-have Skills to Master Data Science
The need to process a massive amount of data sets is making Data Science the most-demanded job across diverse industry verticals.…

Process Mining mit Celonis - Artikelserie
Insgesamt stellt Celonis ein unabhängiges und leistungsstarkes Process Mining Tool bereit, wobei der Anwender die Wahl zwischen einer on-Premise-Lösung sowie einer Cloud-Lösung hat. Die „prebuild Process-Connectors“ und die vordefinierten Analysen können ein Process Mining Projekt signifikant beschleunigen und somit die Time-to-Value lukrativ verkürzen. Die Analyse Tools sind leicht bedienbar und schaffen dank integrierter Machine Learning Algorithmen Optimierungspotentiale.

AI Voice Assistants are the Next Revolution: How Prepared are You?
According to Jeff Bezos, Amazon CEO, he says we’re already living in the golden era of artificial intelligence as such where the voice assistant flagship already exists, i.e. Alexa.




























Team Up für Cloud-Daten-Lösungen
/0 Comments/in Cloud, Insights, Sponsoring Partner Posts /by Arjan van StaverenHeute bestimmen Daten die Welt. Snowflake ermöglicht Unternehmen, ihre Daten über mehrere Clouds hinweg zu speichern und zu analysieren. In einer Zusammenarbeit mit dem Energiegiganten Uniper ermöglicht das Data Warehouse erstklassige Leistung, Benutzerfreundlichkeit und Parallelität für die Daten: Uniper hat sich, mit einer Leistung von ca. 36 Gigawatt, eine Stellung in der ersten Reihe der […]
MeetUp: Classifying Text Data with Embeddings // How to become a data scientist
/0 Comments/in Uncategorized /by eventsWelcome to our 3rd DATANOMIQ Data Science MeetUp, in Berlin! April 3rd: 6 pm until 8 pm. Click the link to participate: https://www.meetup.com/de-DE/DATANOMIQ-Data-Science-Berlin/events/257098910/ Today’s topic is all about Classifying Text Data with Embeddings, presented by Artur Zeitler. Artur is a data scientist at DATANOMIQ. Make sure to come early to grab a voucher for a […]
NetApp Technologie Forum Nord/Ost
/1 Comment/in Data Science News, Events, Sponsoring Partner Posts /by netappSehr geehrter Kunden und Technik-Enthusiasten, mehr wissen ist immer gut und ein hervorragender Grund das NetApp Technologie Forum Nordost zu besuchen. Unter dem Motto „aus der Region für die Region“ und bei unserem Kunden und Gastgeber der Medizinische Hochschule Hannover erfahren Sie, wie NetApp mit der Data Fabric die Konstitution Ihrer Dateninfrastruktur in Zeiten der […]
A Gentle Introduction to Precision and Recall.
/0 Comments/in Data Science, Main Category /by rohitmishraThe idea of this blog is to give an intuitive understanding of Precision and Recall for a binary classification problem. I will shy away from explaining it in a textbook way but rather will try to give an intuition. Nevertheless, let me write the textbook formula first: The problem with this nomenclature is that despite […]
How is automation changing data science and machine learning?
/0 Comments/in Artificial Intelligence, Data Science, Main Category /by Danish WadhwaWe have come a long way since the introduction of data science and machine learning. The recent study has found that the volume of business data doubles in less than 14 months. Today, the collection of data is no longer a problem, but the filtration, analysis, and maintenance of relevant information is a bigger issue. […]
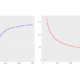
A common trap when it comes to sampling from a population that intrinsically includes outliers
/0 Comments/in Business Analytics, Business Intelligence, Data Mining, Data Science, Data Science Hack, Main Category, R Statistics, Statistics /by Moussa El-ZaarahI will discuss a common fallacy concerning the conclusions drawn from calculating a sample mean and a sample standard deviation and more importantly how to avoid it. Suppose you draw a random sample , , … of size and compute the ordinary (arithmetic) sample mean and a sample standard deviation from it. Now if (and […]
OLAP-Würfel
/2 Comments/in Business Analytics, Business Intelligence, Data Warehousing, InMemory, Main Category /by Jurek DörnerDer OLAP-Würfel Alles ist relativ! So auch die Anforderungen an Datenbanksysteme. Je nachdem welche Arbeitskollegen/innen dazu gefragt werden, können unterschiedliche Wünschen und Anforderungen an Datenbanksysteme dabei zu Tage kommen. Die optimale Ausrichtung des Datenbanksystems auf seine spezielle Anwendung hin, setzt den Grundstein für eine performante und effizientes Informationssystem und sollte daher wohl überlegt sein. Eine […]
Business Intelligence Organizations
/2 Comments/in Carrier, Gerneral, Insights, Projectmanagement /by Benjamin AunkoferI am often asked how the Business Intelligence department should be set up and how it should interact and collaborate with other departments. First and foremost: There is no magic recipe here, but every company must find the right organization for itself. Before we can talk about organization of BI, we need to have a […]
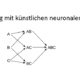
Fehler-Rückführung mit der Backpropagation
/1 Comment/in Artificial Intelligence, Deep Learning, Machine Learning, Main Category, Mathematics, Predictive Analytics /by Benjamin AunkoferDies ist Artikel 4 von 6 der Artikelserie –Einstieg in Deep Learning. Das Gradienten(abstiegs)verfahren ist der Schlüssel zum Training einzelner Neuronen bzw. deren Gewichtungen zu den Neuronen der vorherigen Schicht. Wer dieses Prinzip verstanden hat, hat bereits die halbe Miete zum Verständnis des Trainings von künstlichen neuronalen Netzen. Der Gradientenabstieg wird häufig fälschlicherweise mit der Backpropagation […]
Cross-industry standard process for data mining
/0 Comments/in Data Engineering, Data Mining, Data Science, Data Science Hack, Data Science News, Machine Learning, Python, R Statistics /by Aakash ChughIntroduced in 1996, the cross-industry standard process for data mining (CRISP-DM) became the most common procedure for all data mining projects. This method consists of six phases: Business understanding, Data understanding, Data preparation, Modeling, Evaluation and Deployment (see Figure 1). It is being used not just as a reference manual but as a user guide […]