Interview: Data Science in der Finanzbranche
Interview mit Torsten Nahm von der DKB (Deutsche Kreditbank AG) über Data Science in der Finanzbranche
 Torsten Nahm ist Head of Data Science bei der DKB (Deutsche Kreditbank AG) in Berlin. Er hat Mathematik in Bonn mit einem Schwerpunkt auf Statistik und numerischen Methoden studiert. Er war zuvor u.a. als Berater bei KPMG und OliverWyman tätig sowie bei dem FinTech Funding Circle, wo er das Risikomanagement für die kontinentaleuropäischen Märkte geleitet hat.
Torsten Nahm ist Head of Data Science bei der DKB (Deutsche Kreditbank AG) in Berlin. Er hat Mathematik in Bonn mit einem Schwerpunkt auf Statistik und numerischen Methoden studiert. Er war zuvor u.a. als Berater bei KPMG und OliverWyman tätig sowie bei dem FinTech Funding Circle, wo er das Risikomanagement für die kontinentaleuropäischen Märkte geleitet hat.
Hallo Torsten, wie bist du zu deinem aktuellen Job bei der DKB gekommen?
Die Themen Künstliche Intelligenz und maschinelles Lernen haben mich schon immer fasziniert. Den Begriff „Data Science“ gibt es ja noch gar nicht so lange. In meinem Studium hieß das „statistisches Lernen“, aber im Grunde ging es um das gleiche Thema: dass ein Algorithmus Muster in den Daten erkennt und dann selbstständig Entscheidungen treffen kann.
Im Rahmen meiner Tätigkeit als Berater für verschiedene Unternehmen und Banken ist mir klargeworden, an wie vielen Stellen man mit smarten Algorithmen ansetzen kann, um Prozesse und Produkte zu verbessern, Risiken zu reduzieren und das Kundenerlebnis zu verbessern. Als die DKB jemanden gesucht hat, um dort den Bereich Data Science weiterzuentwickeln, fand ich das eine äußerst spannende Gelegenheit. Die DKB bietet mit über 4 Millionen Kunden und einem auf Nachhaltigkeit fokussierten Geschäftsmodell m.E. ideale Möglichkeiten für anspruchsvolle aber auch verantwortungsvolle Data Science.
Du hast viel Erfahrung in Data Science und im Risk Management sowohl in der Banken- als auch in der Versicherungsbranche. Welche Rolle siehst du für Big Data Analytics in der Finanz- und Versicherungsbranche?
Banken und Versicherungen waren mit die ersten Branchen, die im großen Stil Computer eingesetzt haben. Das ist einfach ein unglaublich datengetriebenes Geschäft. Entsprechend haben komplexe Analysemethoden und auch Big Data von Anfang an eine große Rolle gespielt – und die Bedeutung nimmt immer weiter zu. Technologie hilft aber vor allem dabei Prozesse und Produkte für die Kundinnen und Kunden zu vereinfachen und Banking als ein intuitives, smartes Erlebnis zu gestalten – Stichwort „Die Bank in der Hosentasche“. Hier setzen wir auf einen starken Kundenfokus und wollen die kommenden Jahre als Bank deutlich wachsen.
Kommen die Bestrebungen hin zur Digitalisierung und Nutzung von Big Data gerade eher von oben aus dem Vorstand oder aus der Unternehmensmitte, also aus den Fachbereichen, heraus?
Das ergänzt sich idealerweise. Unser Vorstand hat sich einer starken Wachstumsstrategie verschrieben, die auf Automatisierung und datengetriebenen Prozessen beruht. Gleichzeitig sind wir in Dialog mit vielen Bereichen der Bank, die uns fragen, wie sie ihre Produkte und Prozesse intelligenter und persönlicher gestalten können.
Was ist organisatorische Best Practice? Finden die Analysen nur in deiner Abteilung statt oder auch in den Fachbereichen?
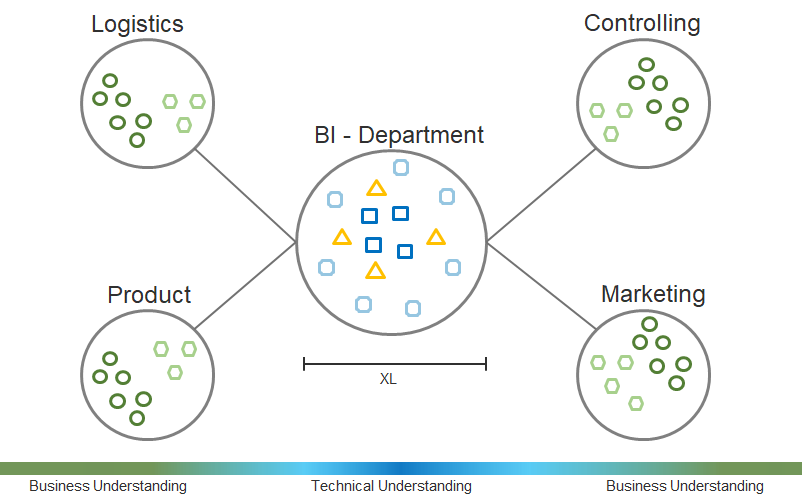
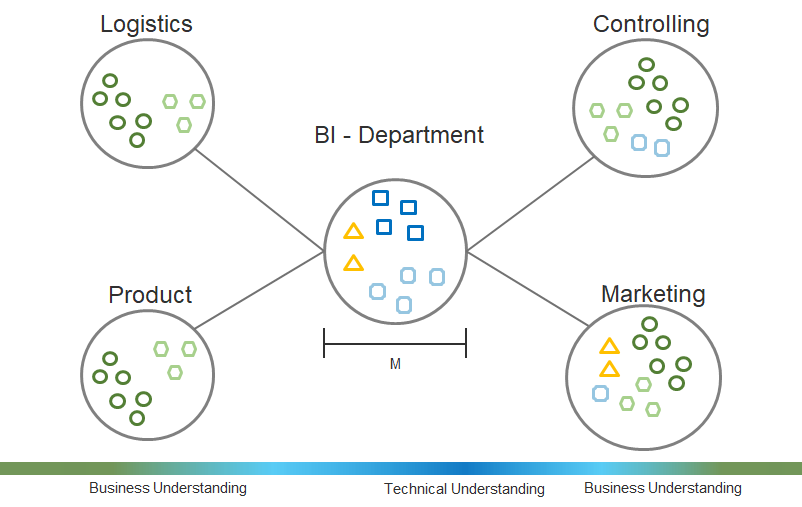
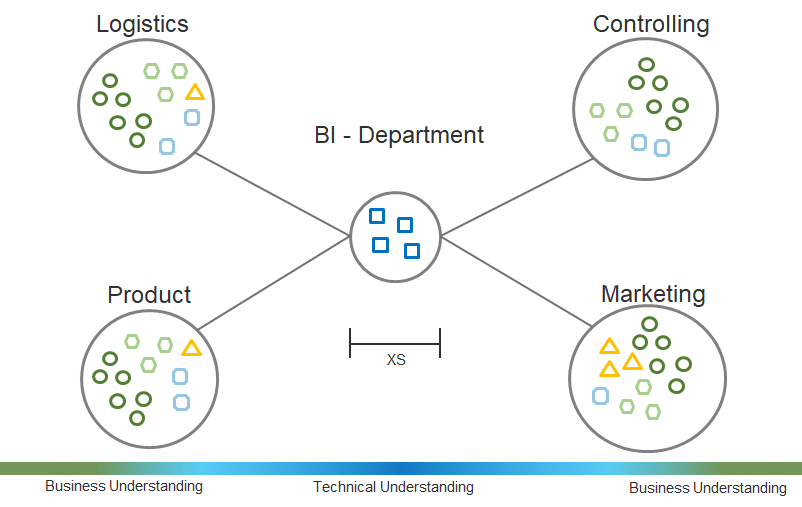
Ich bin ein starker Verfechter eines „Hub-and-Spoke“-Modells, d.h. eines starken zentralen Bereichs zusammen mit dezentralen Data-Science-Teams in den einzelnen Fachbereichen. Wir als zentraler Bereich erschließen dabei neue Technologien (wie z.B. die Cloud-Nutzung oder NLP-Modelle) und arbeiten dabei eng mit den dezentralen Teams zusammen. Diese wiederum haben den Vorteil, dass sie direkt an den jeweiligen Kollegen, Daten und Anwendern dran sind.
Wie kann man sich die Arbeit bei euch in den Projekten vorstellen? Was für Profile – neben dem Data Scientist – sind beteiligt?
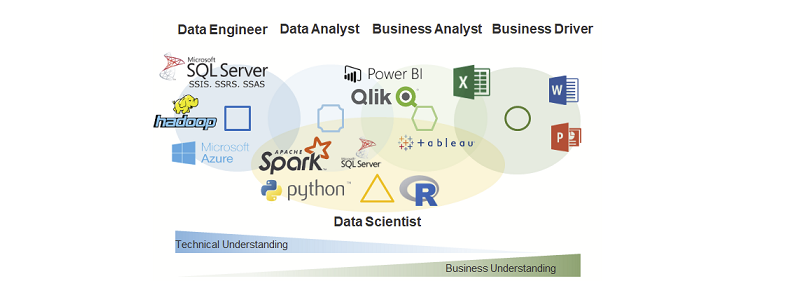
Inzwischen hat im Bereich der Data Science eine deutliche Spezialisierung stattgefunden. Wir unterscheiden grob zwischen Machine Learning Scientists, Data Engineers und Data Analysts. Die ML Scientists bauen die eigentlichen Modelle, die Date Engineers führen die Daten zusammen und bereiten diese auf und die Data Analysts untersuchen z.B. Trends, Auffälligkeiten oder gehen Fehlern in den Modellen auf den Grund. Dazu kommen noch unsere DevOps Engineers, die die Modelle in die Produktion überführen und dort betreuen. Und natürlich haben wir in jedem Projekt noch die fachlichen Stakeholder, die mit uns die Projektziele festlegen und von fachlicher Seite unterstützen.
Und zur technischen Organisation, setzt ihr auf On-Premise oder auf Cloud-Lösungen?
Unsere komplette Data-Science-Arbeitsumgebung liegt in der Cloud. Das vereinfacht die gemeinsame Arbeit enorm, da wir auch sehr große Datenmengen z.B. direkt über S3 gemeinsam bearbeiten können. Und natürlich profitieren wir auch von der großen Flexibilität der Cloud. Wir müssen also z.B. kein Spark-Cluster oder leistungsfähige Multi-GPU-Instanzen on premise vorhalten, sondern nutzen und zahlen sie nur, wenn wir sie brauchen.
Gibt es Stand heute bereits Big Data Projekte, die die Prototypenphase hinter sich gelassen haben und nun produktiv umgesetzt werden?
Ja, wir haben bereits mehrere Produkte, die die Proof-of-Concept-Phase erfolgreich hinter sich gelassen haben und nun in die Produktion umgesetzt werden. U.a. geht es dabei um die Automatisierung von Backend-Prozessen auf Basis einer automatischen Dokumentenerfassung und -interpretation, die Erkennung von Kundenanliegen und die Vorhersage von Prozesszeiten.
In wie weit werden unstrukturierte Daten in die Analysen einbezogen?
Das hängt ganz vom jeweiligen Produkt ab. Tatsächlich spielen in den meisten unserer Projekte unstrukturierte Daten eine große Rolle. Das macht die Themen natürlich anspruchsvoll aber auch besonders spannend. Hier ist dann oft Deep Learning die Methode der Wahl.
Wie stark setzt ihr auf externe Vendors? Und wie viel baut ihr selbst?
Wenn wir ein neues Projekt starten, schauen wir uns immer an, was für Lösungen dafür schon existieren. Bei vielen Themen gibt es gute etablierte Lösungen und Standardtechnologien – man muss nur an OCR denken. Kommerzielle Tools haben wir aber im Ergebnis noch fast gar nicht eingesetzt. In vielen Bereichen ist das Open-Source-Ökosystem am weitesten fortgeschritten. Gerade bei NLP zum Beispiel entwickelt sich der Forschungsstand rasend. Die besten Modelle werden dann von Facebook, Google etc. kostenlos veröffentlicht (z.B. BERT und Konsorten), und die Vendors von kommerziellen Lösungen sind da Jahre hinter dem Stand der Technik.
Letzte Frage: Wie hat sich die Coronakrise auf deine Tätigkeit ausgewirkt?
In der täglichen Arbeit eigentlich fast gar nicht. Alle unsere Daten sind ja per Voraussetzung digital verfügbar und unsere Cloudumgebung genauso gut aus dem Home-Office nutzbar. Aber das Brainstorming, gerade bei komplexen Fragestellungen des Feature Engineering und Modellarchitekturen, finde ich per Videocall dann doch deutlich zäher als vor Ort am Whiteboard. Insofern sind wir froh, dass wir uns inzwischen auch wieder selektiv in unseren Büros treffen können. Insgesamt hat die DKB aber schon vor Corona auf unternehmensweites Flexwork gesetzt und bietet dadurch per se flexible Arbeitsumgebungen über die IT-Bereiche hinaus.