Article series: 5 Clean Coding Tips – 5.Put yourself in somebody else’s shoes
This is the fifth of the article series “5 tips for clean coding” to follow as soon as you’ve made the first steps into your coding career, in this article series. Read the introduction here, to find out why it is important to write clean code if you missed it.
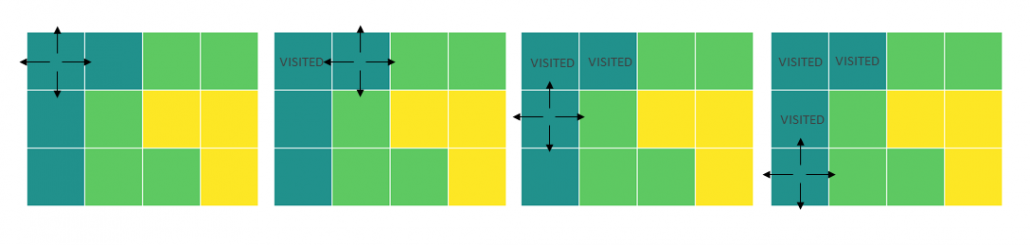
It might be a bit repetitive to bring up how important the readability of the code is, let’s do it anyway. In the majority of the cases you are writing for others, therefore you need to put yourself in their shoes to be able to assess how good the readability of your code is. For you, it all might be obvious because you wrote it. But it doesn’t have to be easy to read for someone else. If you have a colleague or a friend that has a bit of time for you and is willing to give you feedback, that is great. If, however, you don’t have such a person, having a few imaginary friends might be helpful in this case. It might sound crazy, but don’t close this page just yet. Having a set of imaginary personas at your disposal, to review your work with their eyes, can help you a lot. Imagine that your code met one of those guys. What would they say about it? If you work in a team or collaborate with people, you probably don’t have to imagine them. You’ve met them.
The_PEP8_guy – He has years of experience. He is used to seeing the code in a very particular way. He quotes the style guide during lunch. His fingers make the perfect line splitting and indentation without even his thoughts reaching the conscious state. He knows that lowercase_with_underscore is for variables, UPPER_CASE_NAMES are for constants and the CapitalizedWords are for classes. He will be lost if you do it in any different way. His expectations will not meet what you wrote, and he will not understand anything, because he will be too distracted by the messed up visual. Depending on the character he might start either crying or shouting. Read the style guide and follow it. You might be able to please this guy at least a little bit with the automatic tools like pylint.
The_ grieving _widow – Imagine that something happens to you. Let’s say, that you get hit by a bus[i]. You leave behind sadness and the_ grieving_widow to manage your code, your legacy. Will the future generations be able to make use of it or were you the only one who can understand anything you wrote? That is a bit of an extreme situation, ok. Alternatively, imagine, that you go for a 5-week vacation to a silent retreat with a strict no-phone policy (or that is what you tell your colleagues). Will they be able to carry on if they cannot ask you anything about the code? Review your code and the documentation from the perspective of the poor grieving_widow.
The_not_your_domain_guy – He is from the outside of the world you are currently in and he just does not understand your jargon. He doesn’t have to know that in data science a feature, a predictor and an x probably mean the same thing. SNR might shout signal-to-noise ratio at you, it will only snort at him. You might use abbreviations that are obvious to you but not to everyone. If you think that the majority of people can understand, and it helps with the code readability keep the abbreviations but just in case, document/comment them. There might be abbreviations specific to your company and, someone from the outside, a new guy, a consultant will not get them. Put yourself in the shoes of that guy and maybe make your code a bit more democratic wherever possible.
The_foreigner– You might be working in an environment, where every single person speaks the same language you speak, and it happens not to be English. So, you and your colleagues name variables and write the comments in your language. However, unless you work in a team with rules a strict as Athletic Bilbao, there might be a foreigner joining your team in the future. It is hard to argue that English is the lingua franca in programming (and in the world), these days. So, it might be worth putting yourself in the_foreigner’s shoes, while writing your code, to avoid a huge amount of work in the future, that the translation and explanation will require. And even if you are working on your own, you might want to make your code public one day and want as many people as possible to read it.
The_hurry_up_guy – we all know this guy. Sometimes he doesn’t have a body or a face, but we can feel his presence. You might want to write a perfect solution, comment it in the best possible way and maybe add a bit of glitter on top but sometimes you just need to give in and do it his way. And that’s ok too.
References:
[i] https://en.wikipedia.org/wiki/Bus_factor

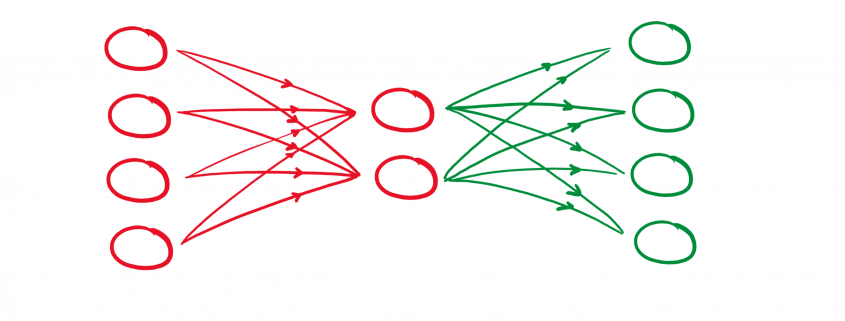
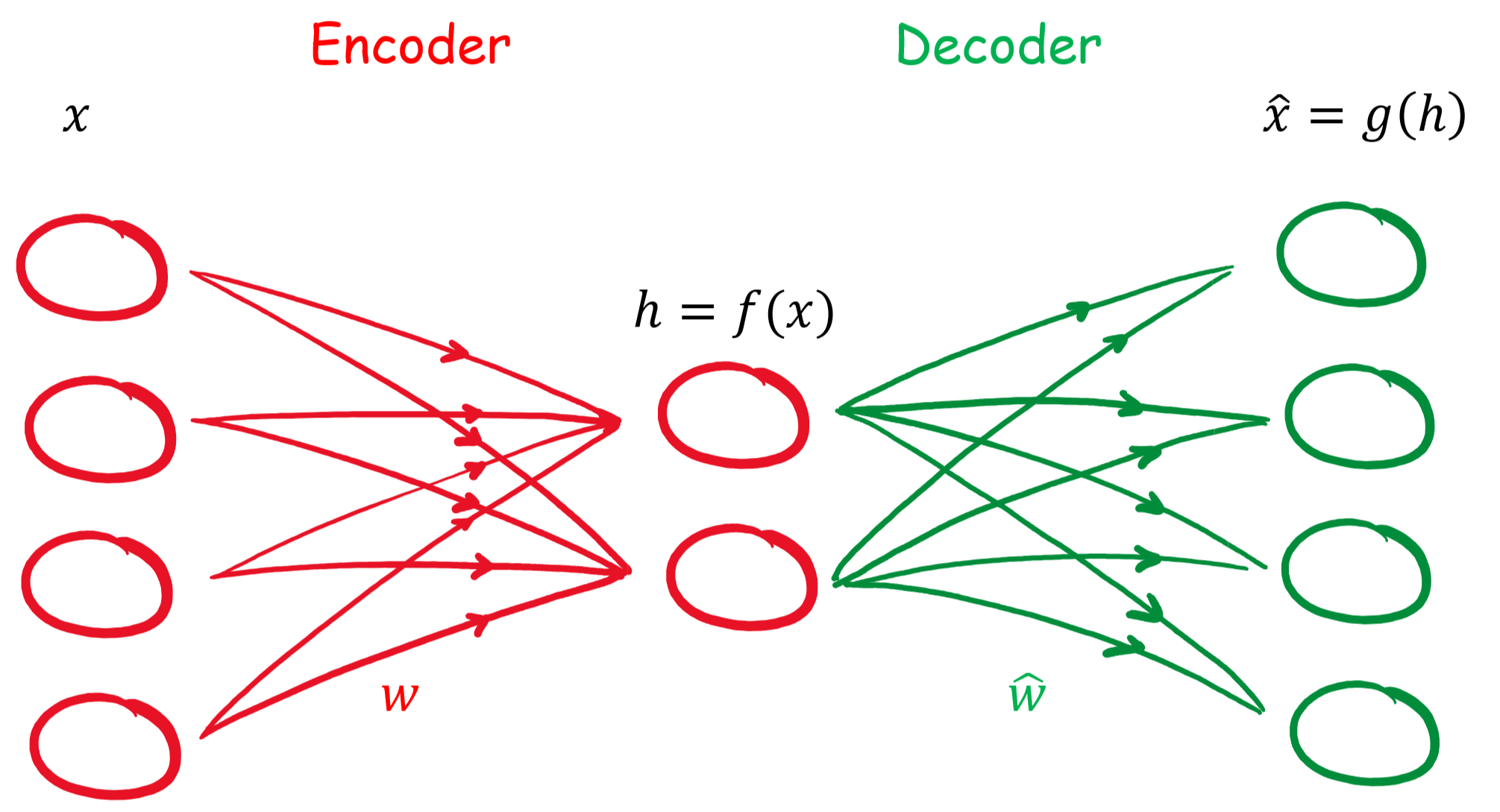






 gekennzeichnet werden. Damit besteht der Zusammenhang:
gekennzeichnet werden. Damit besteht der Zusammenhang:![\begin{align*} \mathbf{h} &= f(\mathbf{x}) = \sigma(\mathbf{W}\mathbf{x} + \mathbf{B}) \\ \hat{\mathbf{x}} &= g(\mathbf{h}) = \hat{\sigma}(\hat{\mathbf{W}} \mathbf{h} + \hat{\mathbf{B}}) \\ \hat{\mathbf{x}} &= \hat{\sigma} \{ \hat{\mathbf{W}} \left[\sigma ( \mathbf{W}\mathbf{x} + \mathbf{B} )\right] + \hat{\mathbf{B}} \}\\ \end{align*}](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-96b9128bd26ff4d2975a372d338e15c4_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} L(\mathbf{x}, \hat{\mathbf{x}}) &= \mathbf{MSE}(\mathbf{x}, \hat{\mathbf{x}}) = \| \mathbf{x} - \hat{\mathbf{x}} \| ^2 &= \| \mathbf{x} - \hat{\sigma} \{ \hat{\mathbf{W}} \left[\sigma ( \mathbf{W}\mathbf{x} + \mathbf{B} )\right] + \hat{\mathbf{B}} \} \| ^2 \end{align*}](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-2afadab2e44942274d566bd163b513cf_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} [1, 0, 0, 0] \ \widehat{=} \ 0 \\ [0, 1, 0, 0] \ \widehat{=} \ 1 \\ [0, 0, 1, 0] \ \widehat{=} \ 2 \\ [0, 0, 0, 1] \ \widehat{=} \ 3\\ \end{align*}](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-072135e2e36d72e0e3bf860c5308e03a_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} [1, 0, 0, 0] \ \widehat{=} \ 0 \ \widehat{=} \ [0, 0] \\ [0, 1, 0, 0] \ \widehat{=} \ 1 \ \widehat{=} \ [0, 1] \\ [0, 0, 1, 0] \ \widehat{=} \ 2 \ \widehat{=} \ [1, 0] \\ [0, 0, 0, 1] \ \widehat{=} \ 3 \ \widehat{=} \ [1, 1] \\ \end{align*}](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-17422530a780bd436a53fc45b2a523aa_l3.png "Rendered by QuickLaTeX.com")