Wie Wirtschaftsprüfer mit auditbee die Nadel im Heuhaufen finden – Teil 2/2
Dies ist Teil 2/2 des Artikels, lesen Sie hier Wie Wirtschaftsprüfer mit auditbee die Nadel im Heuhaufen finden – Teil 1/2.
Auditbee – Datenanalyse mit Qlik Sense in der Wirtschaftsprüfung
Wir sind es mittlerweile gewohnt, vieles einfach per Knopfdruck mit unserer App zu erledigen. Warum sollte etwas anderes für die Datenanalyse gelten?
Das Ziel von auditbee ist, die Datenanalyse durchgängig in die Prüfung zu integrieren. Jeder Prüfer hat mit dem auditbee Dashboard die Möglichkeit, Daten schnell und einfach selbst zu analysieren. Nicht nur für Journal Entry Tests, sondern auch zur Prüfungsplanung, Verständnisgewinnung, Risikobeurteilung und Dokumentation.
Hierzu werden die aus der Finanzbuchhaltung extrahierten GDPdU-Daten vom auditbee Team als Service verarbeitet und dem Prüfer als abgestimmtes Modell zu Verfügung gestellt.
auditbee basiert auf der Business Intelligence Software Qlik Sense, eine in vielen Unternehmen weltweit eingesetzte Reporting Lösung. Mit Qlik Sense werden die Daten über grafische Objekte dargestellt, damit Sie für den Anwender leicht zu erfassen sind.
Mit auditbee auf Basis von Qlik Sense entsteht aus den Daten des Geschäftsjahres, dem Vorjahr und dem Folgejahr ein Modell mit verschiedenen Analysen zur Beurteilung von Geschäftsentwicklungen, für analytische Prüfungshandlungen und Journal Entry Tests. Darüber hinaus werden die Going Concern Annahme (Fortführungsprognose), Performance- und Risikoindikatoren automatisiert anhand von Erwartungswerten oder eines Risiko-Scores beurteilt.
In auditbee sind eine Vielzahl an Dashboards mit unterschiedlichen Themen eingerichtet. Jedes enthält vordefinierte Journal Entry Tests, um prüferische Fragen zu ergründen. Zudem ermöglichen die verschiedenen grafischen Objekte Ad-hoc Analysen – Zeitreihenentwicklung, Kennzahlen, Rangfolgen, etc. – um Auffälligkeiten auf den Grund zu gehen.
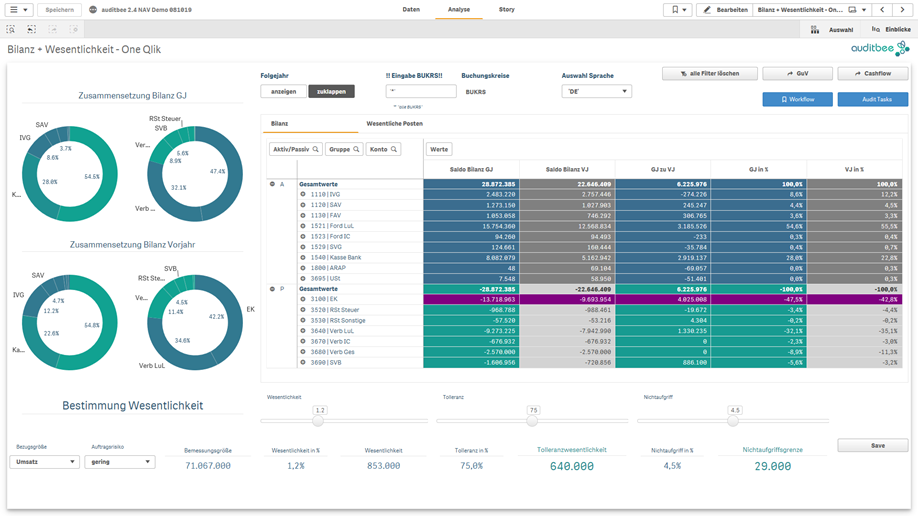
Abb1: Bilanzanalyse und Bestimmung der Wesentlichkeit
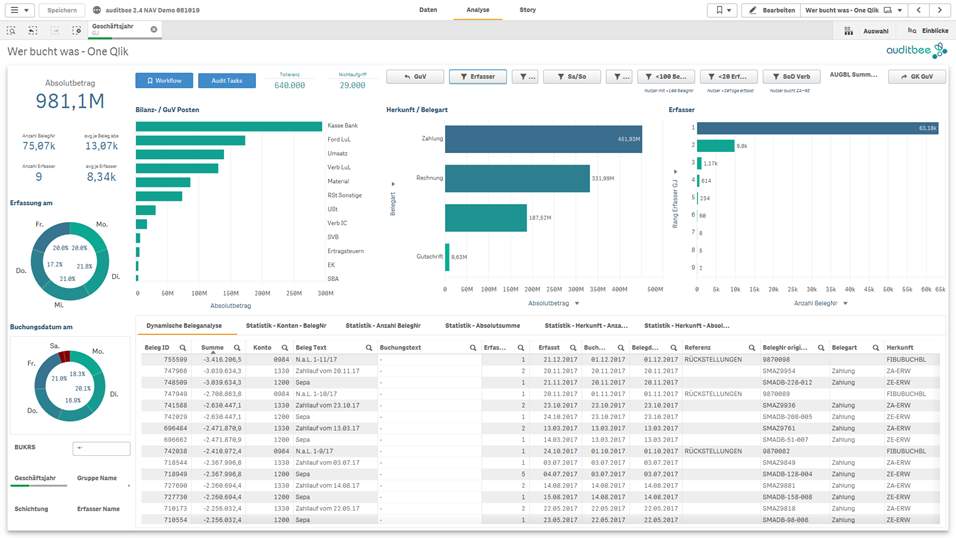
Abb2: Analyse des Buchungsverhaltens nach Nutzer, Erfassungsdatum und Posten
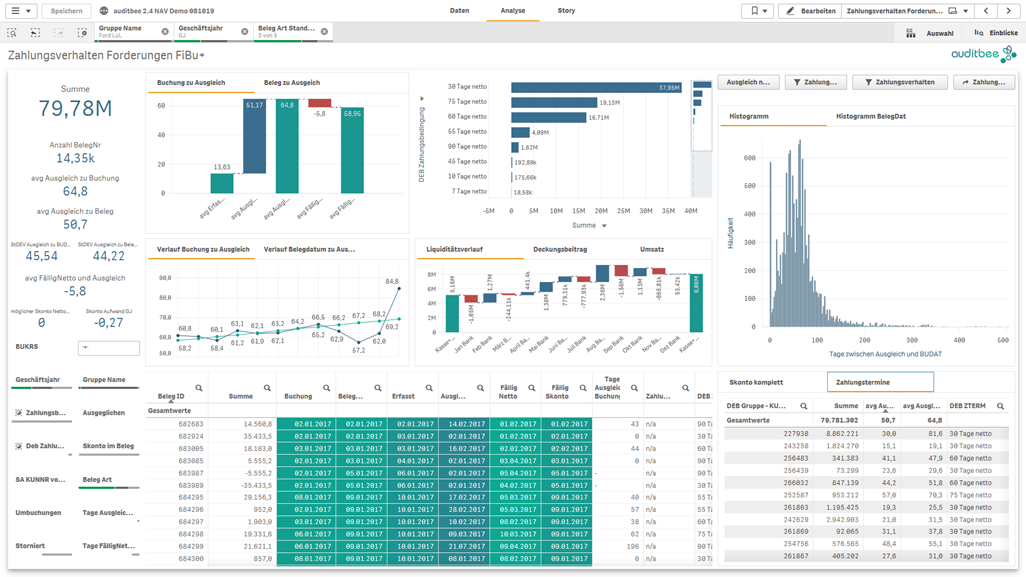
Abb3: Analyse des Zahlungsverhaltens nach Kunde und Zahlungsbedingung
Der Audit Workflow führt den Prüfer durch die verschiedenen Prüfungsgebiete – von der Bilanzanalyse, über die Beurteilung von Performance- und Risikoindikatoren bis hin zu einer Vielzahl an themenbezogener Journal Entry Tests.

Abb4: Teilausschnitt des Audit Workflows in auditbee
Prüfung mit auditbee – Beispiel: Beurteilung der zeitnahen Erfassung von Umsatzerlösen
Die Prüfung erfolgt immer nach einem ähnlichen Schema. Der Prüfer hat eine Frage, mit der er ein Fehlerrisiko einschätzen und Prüfungsaussagen treffen möchte. Mit der Frage, welche Umsatzbuchungen nicht zeitnah erfasst wurden, wird z.B. der periodengerechte Ausweis überprüft. Ein Kontoblatt kann diese Frage in der Regel nicht beantworten, weil das Erfassungsdatum nicht vorhanden ist. In auditbee sind jedoch alle extrahierten Felder aus der Finanzbuchhaltung miteinander als Modell verbunden. Deswegen können auch alle Datensätze daraufhin überprüft werden, wie groß die Zeitspanne zwischen dem Buchungs- und dem Erfassungsdatum ist. Das Erfassungsdatum ist das mit Eingabe im System protokolierte Datum. Das Buchungsdatum ist dagegen frei wählbar, sollte aber auf den Tag der Lieferung-/Leistungserbringung datiert sein.
Leistungen sind innerhalb weniger Tage abzurechnen und in der Buchhaltung zu erfassen (§ 239 Abs. 2 HGB). Wenn die Zeitspanne z.B. mehr als 30 Tage beträgt, gelten diese Buchungen als auffällig. Es besteht ein Risiko, dass entweder organisatorische Mängel bestehen (Freigaben bzw. Abrechnungen dauern zu lange) oder Umsätze abgesprochen und damit Fehlerhaft sein können. Buchungen am Jahresende tragen ein höheres Risiko. Rechnungen können z.B. nur deshalb gestellt worden sein, weil der Einkaufsverantwortliche des Kunden noch Budget hatte und dieses ausschöpfen wollte. Anders herum hat möglicherweise das Unternehmen vorzeitig Leistungen zum Jahresende abgerechnet, obwohl diese noch nicht vollständig erbracht sind. In beiden Fällen besteht das Risiko der Periodenverschiebung von Umsätzen.

Abb5: Übersicht Umsatzerlöse im Geschäftsjahr
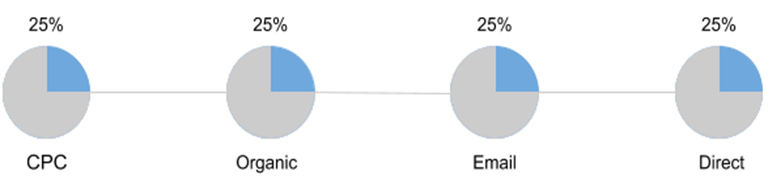
Über die vordefinierte Journal Entry Test Abfrage – zeitnah BUDAT – werden dem Prüfer per Knopfdruck alle Buchungszeilen angezeigt, die das Merkmal – Erfassung zu Buchung > 30 Tage – aufweisen.
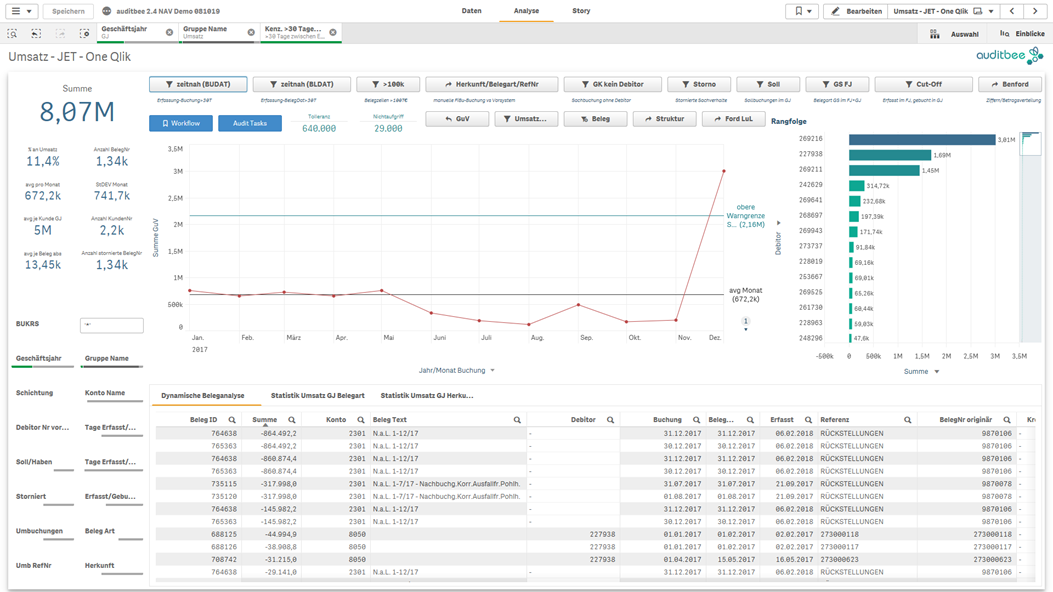
Abb6: JET-Abfrage – Alle Buchungen mit einer Zeitspanne > 30 Tagen
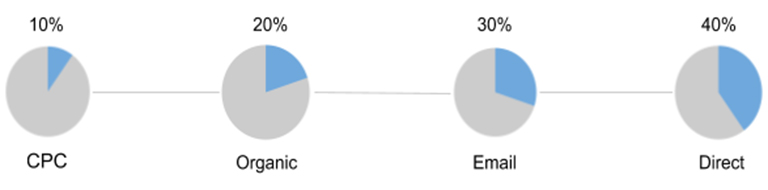
Von den Belegen wählt der Prüfer alle Buchungen per Dezember aus, um die richtige Periodenabgrenzung zu überprüfen.
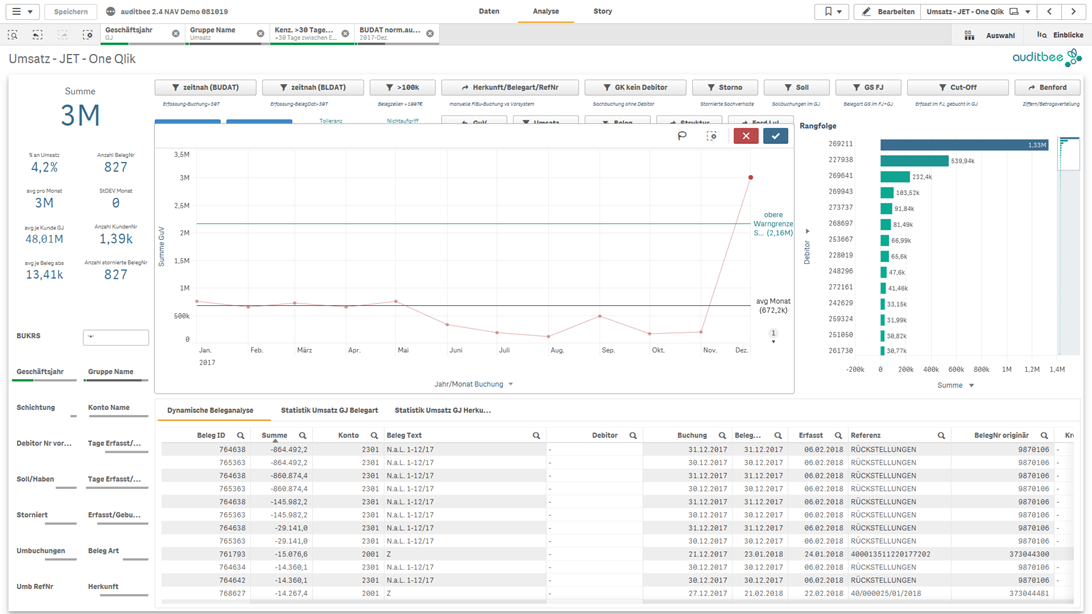
Abb7: Dezemberbuchungen innerhalb der JET Analyse
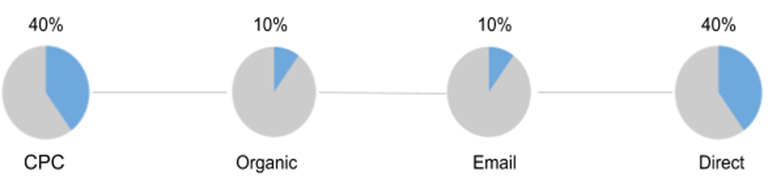
Innerhalb der Umsatzbuchungen sind für den Prüfer solche Buchungen relevant, die an bestimmte Kunden gestellt wurden (wegen des Risikos auf dolose Handlungen).
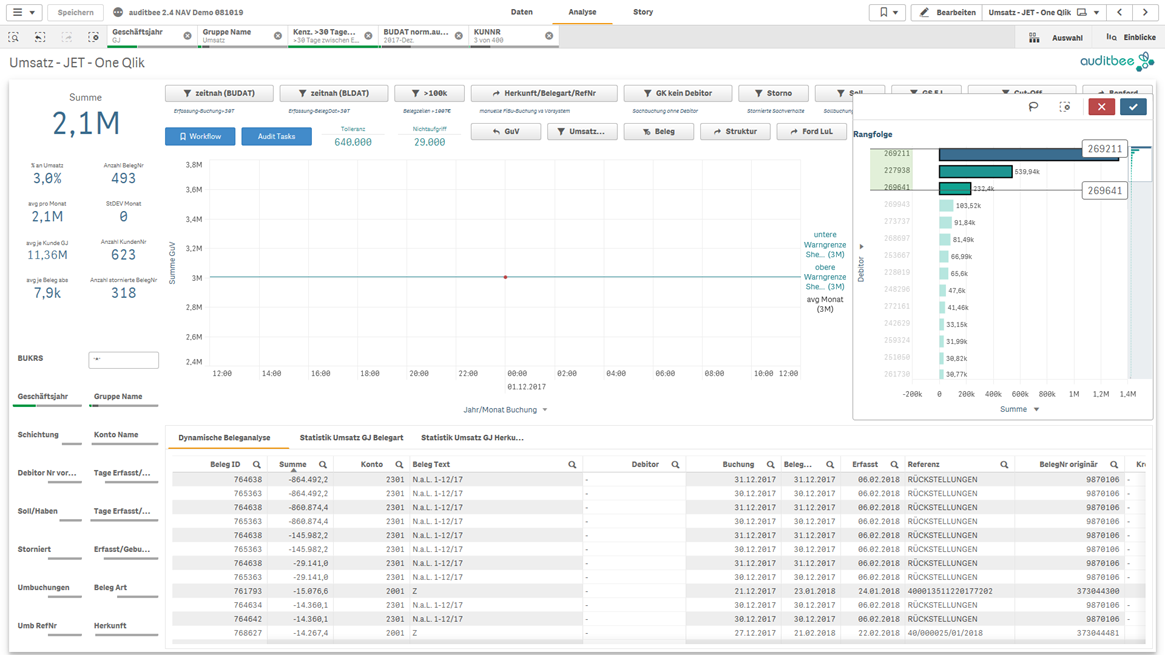
Abb8: Filterung auffälliger Kunden
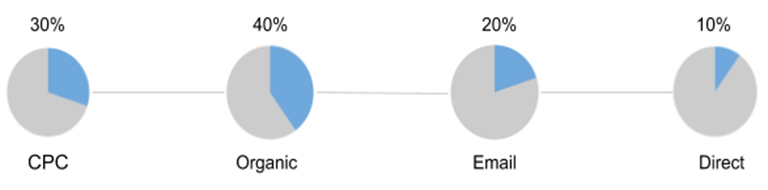
Als letzten Filter wählt der Prüfer alle Beträge oberhalb der Nichtaufgriffsgrenze aus
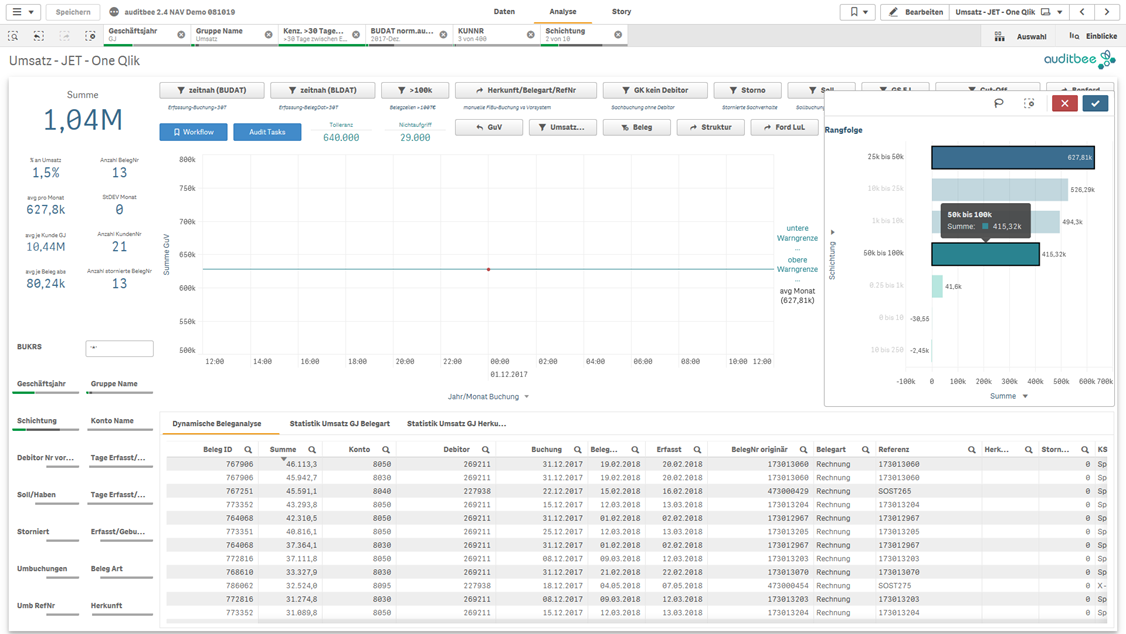
Abb9: Schichtungen nach Beträgen > 25k
Aus den verbleibenden Belegen wählt der Prüfer eine Stichprobe bewusst aus, um anhand von Nachweisen (Rechnungen, Lieferscheine, etc.) zu überprüfen, ob die Buchungen berechtigt, richtig und periodengerecht erfolgt sind. Hierzu kann er die Belegliste aus auditbee in Excel exportieren, um Sie dem Buchhalter als Belegauswahl zuzusenden. Außerdem dokumentiert der Prüfer seine Ergebnisse in der Qlik Sense Story.
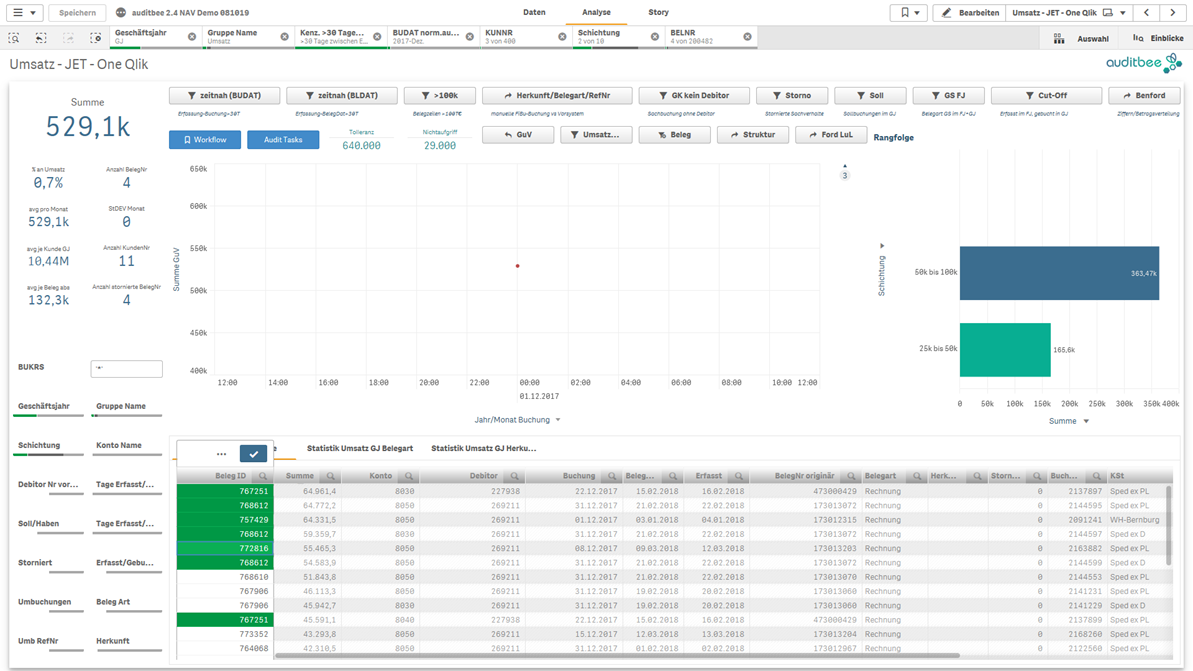
Abb10: Strukturierte bewusste Belegauswahl – 4 von 13 Belege nach
Zusammenfassung und Ausblick
Datenanalysen ermöglichen dem Prüfer sehr tiefe Einblicke in die Geschäftsentwicklung des Mandanten. So kann er nicht nur sein Verständnis vom Unternehmen stetig weiterentwickeln, die Datenanalyse hilft ihm auch, Massendaten angemessen zu überprüfen.
Damit der Prüfer mit der Datenanalyse die Nadel im Heuhaufen finden, relevante Entwicklungen erkennen und Zusammenhänge besser verstehen kann, muss sie jedoch in die Prüfung integriert sein. Das bedeutet, dass sie nicht nur für Journal Entry Tests durch Spezialisten, genutzt wird, sondern jedes einzelne Teammitglied selbst anhand der Daten Auffälligkeiten leicht erkennen und überprüfen kann. Außerdem wird die Analyse zur Risikobeurteilung verwendet. Dadurch können unkritische Bereiche von weitergehenden Prüfungshandlungen ausgenommen werden. Durch die Fokussierung und das Filtern auffälliger Datensätze kann schließlich der Umfang von Einzelbelegprüfungen deutlich verringert werden.
auditbee übernimmt als Service die Datenaufbereitung und stellt dem Prüfer ein fertig abgestimmtes Dashboard-Modell zur Verfügung, dass der Prüfer mit der BI Software Qlik Sense nutzen kann. Damit baut die Kanzlei Risiken ab, weil Sie weniger von Spezialisten abhängig ist. Zum anderen enthält das auditbee Modell jede Menge menschlichen Sachverstand und Logik in Form von Journal Entry Test Abfragen, Kennzahlen bis hin zu dynamischen Beurteilungen. Dadurch spart sich der Prüfer die Zeit, die entsprechenden Fragen und Analysen selbst mit Excel oder einem anderen Softwarelösungen zu modellieren.
Wirtschaftsprüfung ist Teamarbeitet. Jeder bringt seine individuellen Stärken und Fachwissen ein. Deshalb braucht das Team immer auch jemanden, dessen Stärke in der Analyse liegt, um schnell und effizient Auffälligkeiten zu erkennen und diese durch richtige Fragen und Nachweise angemessen zu würdigen. Jedoch ist der Spezialist Dank auditbee nicht mehr alleine. Das ganze Team hat nun Zugriff auf alle GDPdU Daten aus der Finanzbuchhaltung und auch die Dokumentation erfolgt innerhalb einer Lösung – und das ist auditbee!







 Read this article in German:
Read this article in German: