Illustrative introductions on dimension reduction
“What is your image on dimensions?”
….That might be a cheesy question to ask to reader of Data Science Blog, but most people, with no scientific background, would answer “One dimension is a line, and two dimension is a plain, and we live in three-dimensional world.” After that if you ask “How about the fourth dimension?” many people would answer “Time?”
Terms like “multi dimensional something” is often used in science fictions because it’s a convenient black box when you make a fantasy story, and I’m sure many authors would not have thought that much about what those dimensions are.
In Japanese, if you say “He likes two dimension.” that means he prefers anime characters to real women, as is often the case with Japanese computer science students.
The meanings of “dimensions” depend on the context, but in data science dimension is in short the number of rows of your Excel data.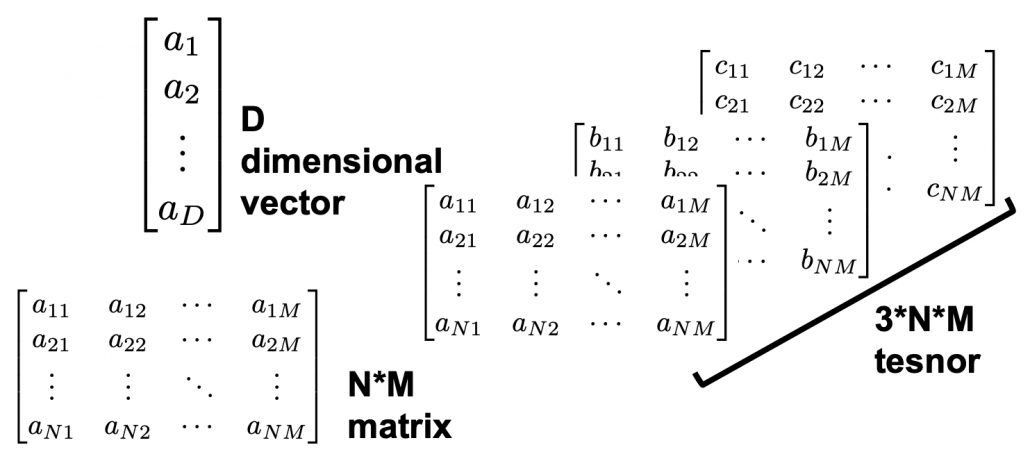
When you study data science or machine learning, usually you should start with understanding the algorithms with 2 or 3 dimensional data, and you can apply those ideas to any D dimensional data.
But of course you cannot visualize D dimensional data anymore, and that is almost an imaginary world on blackboards.
In this blog series I am going to explain algorithms for dimension reductions, such as PCA, LDA, and t-SNE, with 2 or 3 dimensional visible data. Along with that, I am going to delve into the meaning of calculations so that you can understand them in more like everyday-life sense.
This article series is going to be roughly divided into the contents below.
- Curse of Dimensionality (to be published soon)
- PCA, LDA (to be published soon)
- Rethinking eigen vectors (to be published soon)
- KL expansion and subspace method (to be published soon)
- Autoencoder as dimension reduction (to be published soon)
- t-SNE (to be published soon)
I hope you could see that reducing dimension is one of the fundamental approaches in data science or machine learning.
Yasuto Tamura
Data Science Intern at DATANOMIQ. Majoring in computer science. Currently studying mathematical sides of deep learning, such as densely connected layers, CNN, RNN, autoencoders, and making study materials on them. Also started aiming at Bayesian deep learning algorithms.

Leave a Reply
Want to join the discussion?Feel free to contribute!