Einführung und Vertiefung in R Statistics mit den Dortmunder R-Kursen!
Im Rahmen der Dortmunder R Kurse bieten wir unsere Expertise in Schulungen für die Programmiersprache R an. Zielgruppe unserer Fortbildungen sind nicht nur Statistiker, sondern auch Anwender jeder Fachrichtung aus Industrie und Forschungseinrichtungen, die mit R ihre Daten analysieren wollen. Die Dortmunder R-Kurse werden ausschließlich von Statistikern mit langjähriger Erfahrung angeboten. Die Referenten gehören zum engsten Kreis der internationalen R-Gemeinschaft. Die angebotenen Kurse haben sich vielfach national und international bewährt.
Unsere Termine für die Online-Durchführung in diesem Jahr:
8., 9. und 10. Juni: R-Basiskurs (jeweils 9:00 – 14:00 Uhr)
22., 23., 24. und 25. Juni: R-Vertiefungskurs (jeweils 9:00 – 13:00 Uhr)
Kosten jeweils 750.00€, bei Buchung beider Kurse im Juni erhalten Sie einen Preisnachlass von 200€.
Zur Anmeldung gelangen Sie über den nachfolgenden Link:
https://www.zhb.tu-dortmund.de/zhb/wb/de/home/Seminare/Andere_Veranst/index.html
R Basiskurs
Das Seminar R Basiskurs für Anfänger findet am 8., 9. und 10. Juni 2020 statt. Den Teilnehmern wird der praxisrelevante Part der Programmiersprache näher gebracht, um so die Grundlagen zur ersten Datenanalyse — von Datensatz zu statistischen Kennzahlen und ersten Visualisierungen — zu schaffen. Anmeldeschluss ist der 25. Mai 2020.
Programm:
- Installation von R und zugehöriger Entwicklungsumgebung
- Grundlagen von R: Syntax, Datentypen, Operatoren, Funktionen, Indizierung
- R-Hilfe effektiv nutzen
- Ein- und Ausgabe von Daten
- Behandlung fehlender Werte
- Statistische Kennzahlen
- Visualisierung
R Vertiefungskurs
Das Seminar R-Vertiefungskurs für Fortgeschrittene findet am 22., 23., 24. und 25. Juni (jeweils von 9:00 – 13:00 Uhr) statt. Die Veranstaltung ist ideal für Teilnehmende mit ersten Vorkenntnissen, die ihre Analysen effizient mit R durchführen möchten. Anmeldeschluss ist der 11. Juni 2020.
Der Vertiefungskurs baut inhaltlich auf dem Basiskurs auf. Es besteht aber keine Verpflichtung, bei Besuch des Vertiefungskurses zuvor den Basiskurs zu absolvieren, wenn bereits entsprechende Vorkenntnisse in R vorhanden sind.
Programm:
- Eigene Funktionen, Schleifen vermeiden durch *apply
- Einführung in ggplot2 und dplyr
- Statistische Tests und Lineare Regression
- Dynamische Berichterstellung
- Angewandte Datenanalyse anhand von Fallbeispielen
Links zur Veranstaltung direkt:
R-Basiskurs: https://dortmunder-r-kurse.de/kurse/r-basiskurs/
R-Vertiefungskurs: https://dortmunder-r-kurse.de/kurse/r-vertiefungskurs/




 ,
,  , …
, …  of size
of size  and compute the ordinary (arithmetic) sample mean
and compute the ordinary (arithmetic) sample mean  and a sample standard deviation
and a sample standard deviation  from it. Now if (and only if) the (true) population mean µ (first moment) and population variance (second moment) obtained from the actual underlying PDF are finite, the numbers
from it. Now if (and only if) the (true) population mean µ (first moment) and population variance (second moment) obtained from the actual underlying PDF are finite, the numbers  , thus neither the first nor the second moment exist whereby the first exists and vanishes at least in the sense of a principal value due to symmetry.
, thus neither the first nor the second moment exist whereby the first exists and vanishes at least in the sense of a principal value due to symmetry. (pseudo) standard Cauchy random numbers in R* to analyze the behavior of their sample mean and standard deviation
(pseudo) standard Cauchy random numbers in R* to analyze the behavior of their sample mean and standard deviation  .
.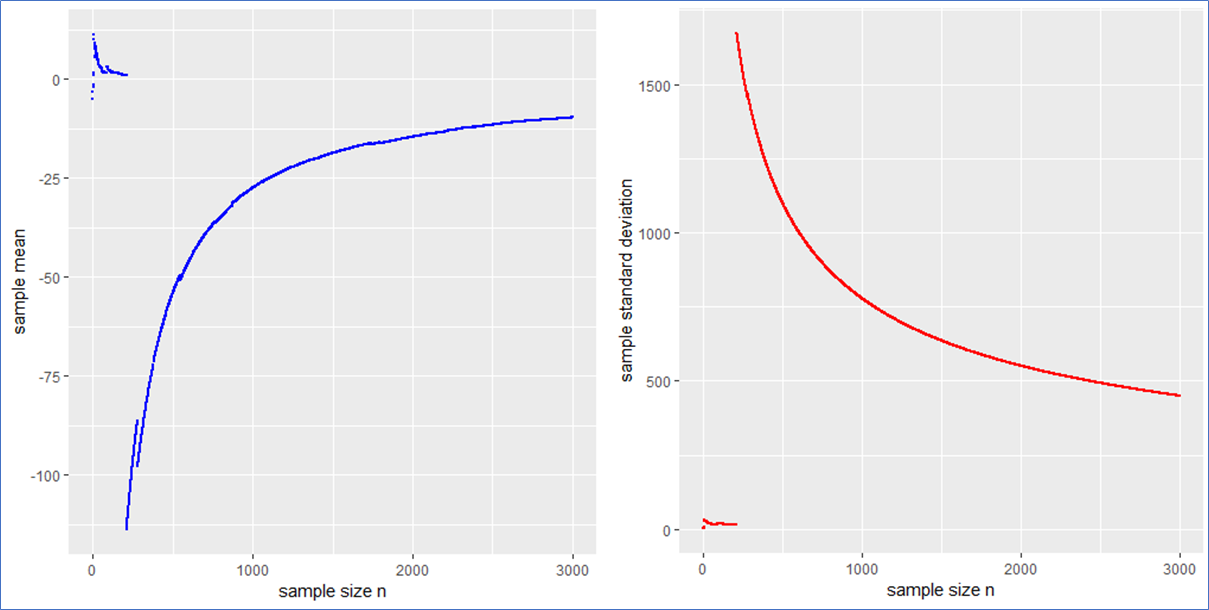
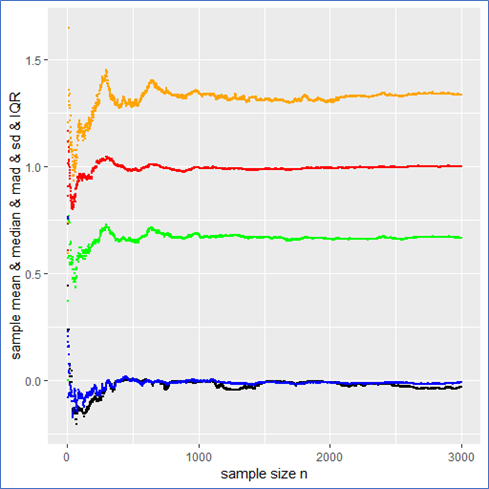
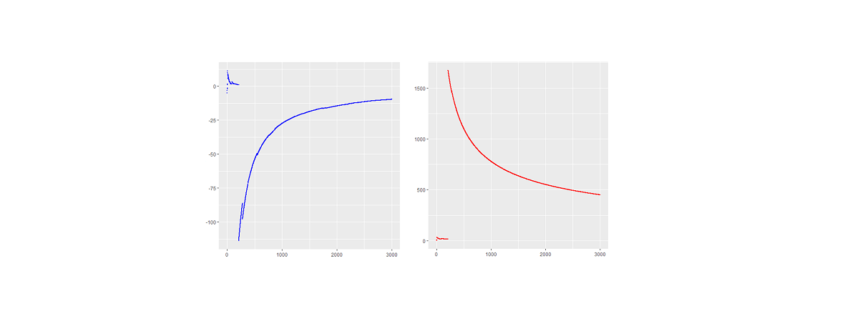
 . This means that the sample mean is also standard Cauchy distributed implying that with a different Cauchy sample one could have easily observed different sample means far of the presented values in blue.
. This means that the sample mean is also standard Cauchy distributed implying that with a different Cauchy sample one could have easily observed different sample means far of the presented values in blue. in such a case? What to do?
in such a case? What to do?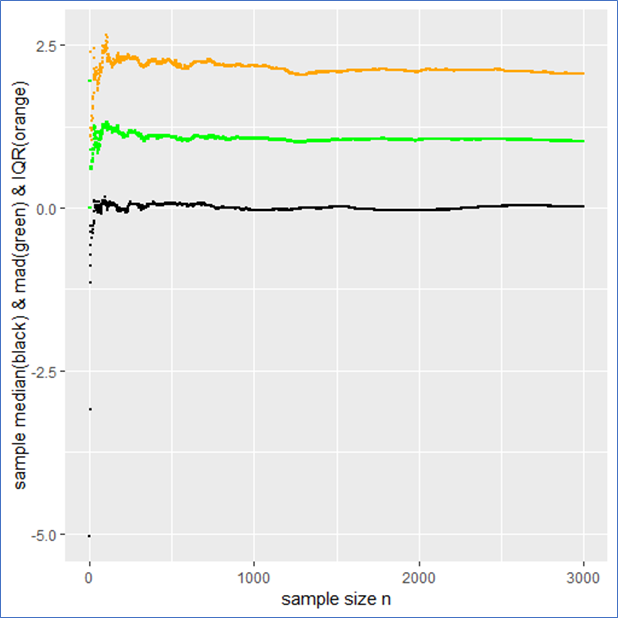
 mad meaning that the IQR is twice the mad.
mad meaning that the IQR is twice the mad. from it to present the usual stochastic confidence intervals for the sample mean.
from it to present the usual stochastic confidence intervals for the sample mean.