„Mit welchem BI-Tool arbeitest du am liebsten?“ Mit dieser Frage werde ich dieser Tage oft konfrontiert. Meine klassische Antwort und eine typische Beraterantwort: „Es kommt darauf an.“ Nach einem Jahr als Berater sitzt diese Antwort sicher, aber gerade in diesem Fall auch begründet. Auf den Analytics und Business Intelligence Markt drängen jedes Jahr etliche neue Dashboard-Anbieter und die etablierten erweitern Services und Technik in rasantem Tempo. Zudem sind die Anforderungen an ein BI-Tool höchst unterschiedlich und von vielen Faktoren abhängig. Meine Perspektive, also die Anwenderperspektive eines Entwicklers, ist ein Faktor und auch der Kern dieser Artikelserie. Um die Masse an Tools auf eine machbare Anzahl runter zu brechen werde ich die bekanntesten Tools im Vergleich ausprobieren und hier vorstellen. Die Aufgabe ist also schnell erklärt: Ein Dashboard mit den gleichen Funktionen und Aussagen in unterschiedlichen Tools erstellen. Im Folgenden werde ich auch ein paar Worte zur Bewertungsgrundlage und zur Datengrundlage verlieren.
Erstmal kurz zu mir: Wie bereits erwähnt arbeite ich seit einem Jahr als Berater, genauer als Data Analyst in einem BI-Consulting Unternehmen namens DATANOMIQ. Bereits davor habe ich mich auf der anderen Seite der Macht, quasi als Kunde eines Beraters, viel mit Dashboards beschäftigt. Aber erst in dem vergangenen Jahr wurde mir die Fülle an BI Tools bewusst und der Lerneffekt war riesig. Die folgende Grafik zeigt alle Tools welche ich in der Artikelserie vorstellen möchte.

Gartner’s Magic Quadrant for Analytics and Business Intelligence Platform führt jedes Jahr eine Portfolioanalyse über die visionärsten und bedeutendsten BI-Tools durch, unter der genannten befindet sich nur eines, welches nicht in dieser Übersicht geführt wird, ich jedoch als potenziellen Newcomer für die kommenden Jahre erwarte. Trotz mittlerweile einigen Jahren Erfahrung gibt es noch reichlich Potential nach oben und viel Neues zu entdecken, gerade in einem so direkten Vergleich. Also seht mich ruhig als fortgeschrittenen BI-Analyst, der für sich herausfinden will, welche Tools aus Anwendersicht am besten geeignet sind und vielleicht kann ich dem ein oder anderen auch ein paar nützliche Tipps mit auf den Weg geben.
Was ist eigentlich eine „Analytical and Business Intelligence Platform“?
Für alle, die komplett neu im Thema sind, möchte ich erklären, was eine Analytical and Business Intelligence Platform in diesem Kontext ist und warum wir es nachfolgend auch einfach als BI-Tool bezeichnen können. Es sind Softwarelösungen zur Generierung von Erkenntnissen mittels Visualisierung und Informationsintegration von Daten. Sie sollten einfach handhabbar sein, weil der Nutzer für die Erstellung von Dashboards keine speziellen IT-Kenntnisse mitbringen muss und das Userinterface der jeweiligen Software einen mehr oder minder gut befähigt die meisten Features zu nutzen. Die meisten und zumindest die oben genannten lassen sich aber auch um komplexere Anwendungen und Programmiersprachen erweitern. Zudem bestimmt natürlich auch der Use Case den Schwierigkeitsgrad der Umsetzung.
Cloudbasierte BI Tools sind mittlerweile der Standard und folgen dem allgemeinen Trend. Die klassische Desktop-Version wird aber ebenfalls von den meisten angeboten. Von den oben genannten haben lediglich Data Studio und Looker keine Desktop- Version. Für den einfachen User macht das keinen großen Unterschied, welche Version man nutzt. Aber für das Unternehmen in Gesamtheit ist es ein wesentlicher Entscheidungsfaktor für die Wahl der Software und auch auf den Workflow des Developers bzw. BI-Analyst kann sich das auswirken.
Unternehmensperspektive: Strategie & Struktur
Die Unternehmensstrategie setzt einen wesentlichen Rahmen zur Entwicklung einer Datenstrategie worunter auch ein anständiges Konzept zur Data Governance gehört.
Ein wesentlicher Punkt der Datenstrategie ist die Verteilung der BI- und Datenkompetenz im Unternehmen. An der Entwicklung der Dashboards arbeiten in der Regel zwei Parteien, der Developer, der im Unternehmen meistens die Bezeichnung BI- oder Data Analyst hat, und der Stakeholder, also einzelner User oder die User ganzer Fachabteilungen.
Prognose: Laut Gartner wird die Anzahl der Daten- und Analyse-Experten in den Fachabteilungen, also die Entwickler und Benutzer von BI Tools, drei Mal so schnell wachsen verglichen mit dem bereits starken Wachstum an IT-Fachkräften.
Nicht selten gibt es für ein Dashboard mehrere Stakeholder verschiedener Abteilungen. Je nach Organisation und Softwarelösung mit unterschiedlich weitreichenden Verantwortlichkeiten, was die Entwicklung eines Dashboards an geht.

Die obige Grafik zeigt die wesentlichen Prozessschritte von der Konzeption bis zum fertigen Dashboard und drei oft gelebte Konzepte zur Verteilung der Aufgaben zwischen dem User und dem Developer. Natürlich handelt es sich fast immer um einen iterativen Prozess und am Ende stellen sich auch positive Nebenerkenntnisse heraus. Verschiedene Tools unterstützen durch Ihre Konfiguration und Features verschiedene Ansätze zur Aufgabenverteilung, auch wenn mit jedem Tool fast jedes System gelebt werden kann, provozieren einige Tools mit ihrem logischen Aufbau und dem Lizenzmodell zu einer bestimmten Organisationsform. Looker zum Beispiel verkauft mit der Software das Konzept, dem User eine größere Möglichkeit zu geben, das Dashboard in Eigenregie zu bauen und gleichzeitig die Datenhoheit an den richtigen Stellen zu gewährleisten (mittlerer Balken in der Grafik). Somit wird dem User eine höhere Verantwortung übertragen und weit mehr Kompetenzen müssen vermittelt werden, da der Aufbau von Visualisierung ebenfalls Fehlerpotential in sich birgt. Ein Full‑Service hingegen unterstützt das Konzept fast aller Tools durch Zuweisen von Berechtigungen. Teilweise werden aber gewisse kostenintensive Features nicht genutzt oder auf Cloud-Lizenzen verzichtet, so dass jeder Mitarbeiter unabhängig auf einer eigenen Desktop-Version arbeitet, am Ende dann leider die Single Source of Truth nicht mehr gegeben ist. Denn das führt eigentlich gezwungenermaßen dazu, dass die User sich aus x beliebigen Datentöpfen bedienen, ungeschultes Personal falsche Berechnungen anstellt und am Ende die unterschiedlichen Abteilungen sich mit schlichtweg falschen KPIs überbieten. Das spricht meistens für ein Unternehmen ohne vollumfängliches Konzept für Data Governance bzw. einer fehlenden Datenstrategie.
Zu dem Thema könnte man einen Roman schreiben und um euch diesen zu ersparen, möchte ich kurz die wichtigsten Fragestellungen aus Unternehmensperspektive aufzählen, ohne Anspruch auf Vollständigkeit:
- Wann wird ein Return on Invest (ROI) realisiert werden?
- Wie hoch ist mein Budget für BI-Lösungen?
- Sollen die Mitarbeiter mit BI-Kompetenz zentral oder dezentral organisiert sein?
- Wie ist meine Infrastruktur aufgebaut? Cloudbasiert oder on Premise?
- Soll der Stakeholder/User Zeit-Ressourcen für den Aufbau von Dashboards erhalten?
- Über welche Skills verfügen die Mitarbeiter bereits?
- Welche Autorisierung in Bezug auf die Datensichtbarkeit und -manipulation haben die jeweiligen Mitarbeiter der Fachabteilungen?
- Bedarf an Dashboards: Wie häufig werden diese benötigt und wie oft werden bestehende Dashboards angepasst?
- Kann die Data Exploration durch den Stakeholder/User einen signifikanten Mehrwert liefern?
- Werden Dashboards in der Regel für mehrere Stakeholder gebaut?
Die Entscheidung für die Wahl eines Dashboards ist nicht nur davon abhängig, wie sich die Grafiken von links nach rechts schieben lassen, sondern es handelt sich auch um eine wichtige strategische Frage aus Unternehmersicht.
Ein Leitsatz hierbei sollte lauten:
Die Strategie des Unternehmens bestimmt die Anforderungen an das Tool und nicht andersrum!
Perspektive eines Entwicklers: Bewertungsgrundlage der Tools
So jetzt Mal Butter bei die Fische und ab zum Kern des Artikels. Jeder der Artikel wird aus den folgenden Elementen bestehen:
- Das Tool:
- Daten laden
- Daten transformieren
- Daten visualisieren
- Zukunftsfähigkeit am Beispiel von Pythonintegration
- Handhabbarkeit
- Umweltfaktoren:
- Community
- Dokumentation
- Features anderer Entwickler(-firmen) zur Erweiterung
- Lizenzmodell
- Cloud (SaaS) ODER on premise Lizenzen?
- Preis (pro Lizenz, Unternehmenslizenz etc.)
- Freie Version
Im Rahmen dieser Artikelserie erscheinen im Laufe der kommenden Monate folgende Artikel zu den Reviews der BI-Tools:
- Power BI von Microsoft
- Tableau
- MicroStrategy (erscheint demnächst)
- Looker (erscheint demnächst)
- Qlik Sense (erscheint demnächst)
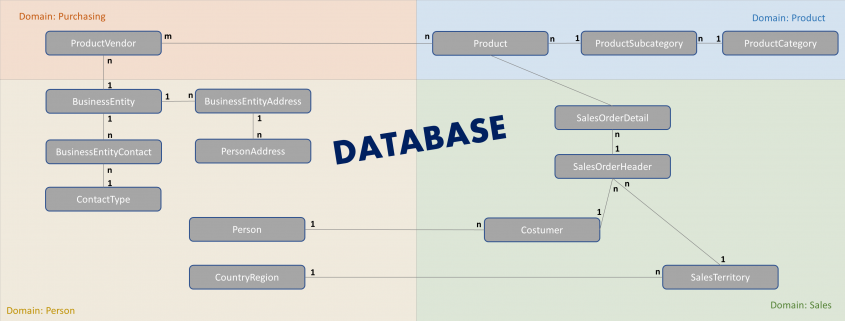
Über einen vorausgehend veröffentlichten Artikel wird die Datengrundlage erläutert, die für alle Reviews gemeinsam verwendet wird: Vorstellung der Datengrundlage