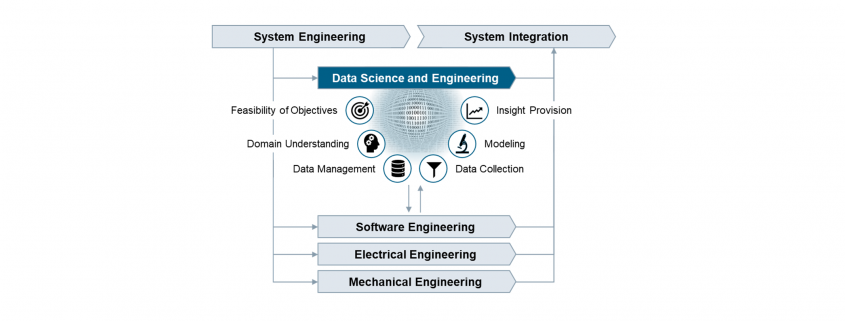
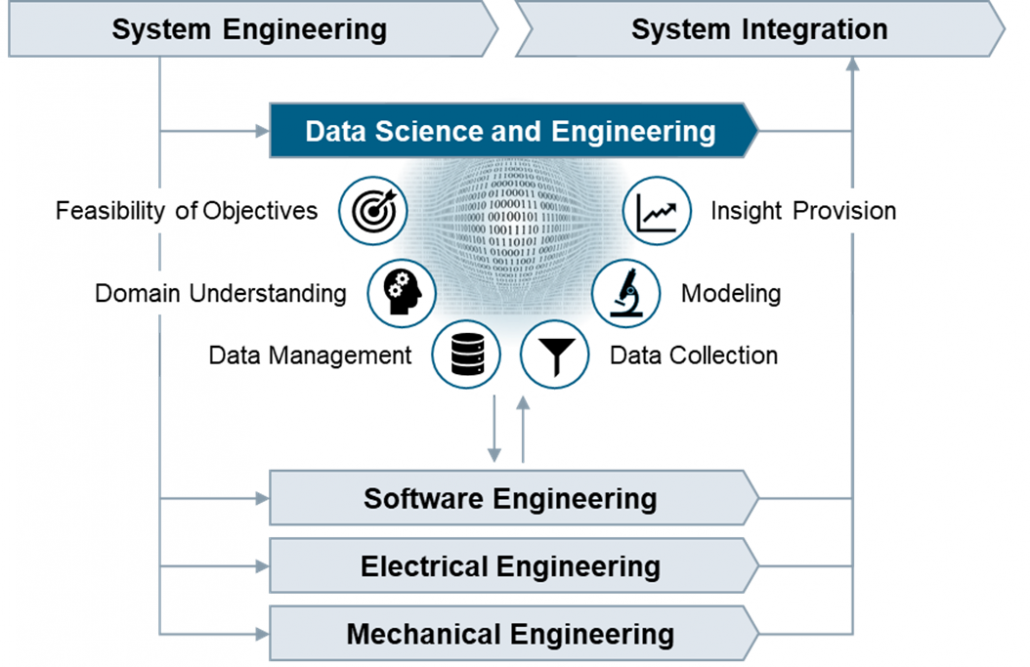
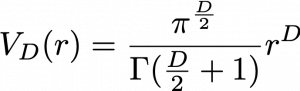Hypothesis tests are significant for evaluating answers to questions concerning samples of data.
A statistical hypothesis is a belief made about a population parameter. This belief may or might not be right. In other words, hypothesis testing is a proper technique utilized by scientist to support or reject statistical hypotheses. The foremost ideal approach to decide if a statistical hypothesis is correct is examine the whole population.
Since that’s frequently impractical, we normally take a random sample from the population and inspect the equivalent. Within the event sample data set isn’t steady with the statistical hypothesis, the hypothesis is refused.
Types of hypothesis:
There are two sort of hypothesis and both the Null Hypothesis (Ho) and Alternative Hypothesis (Ha) must be totally mutually exclusive events.
• Null hypothesis is usually the hypothesis that the event wont’t happen.
• Alternative hypothesis is a hypothesis that the event will happen.
Why we need Hypothesis Testing?
Suppose a specific cosmetic producing company needs to launch a new Shampoo in the market. For this situation they will follow Hypothesis Testing all together decide the success of new product in the market.
Where likelihood of product being ineffective in market is undertaken as Null Hypothesis and likelihood of product being profitable is undertaken as Alternative Hypothesis. By following the process of Hypothesis testing they will foresee the accomplishment.
How to Calculate Hypothesis Testing?
- State the two theories with the goal that just one can be correct, to such an extent that the two occasions are totally unrelated.
- Now figure a study plan, that will lay out how the data will be assessed.
- Now complete the plan and genuinely investigate the sample dataset.
- Finally examine the outcome and either accept or reject the null hypothesis.
Another example
Assume, Person have gone after a typing job and he has expressed in the resume that his composing speed is 70 words per minute. The recruiter might need to test his case. On the off chance that he sees his case as adequate, he will enlist him in any case reject him. Thus, he types an example letter and found that his speed is 63 words a minute. Presently, he can settle on whether to employ him or not. In the event that he meets all other qualification measures. This procedure delineates Hypothesis Testing in layman’s terms.
In statistical terms Hypothesis his typing speed is 70 words per minute is a hypothesis to be tested so-called null hypothesis. Clearly, the alternating hypothesis his composing speed isn’t 70 words per minute.
So, normal composing speed is population parameter and sample composing speed is sample statistics.
The conditions of accepting or rejecting his case is to be chosen by the selection representative. For instance, he may conclude that an error of 6 words is alright to him so he would acknowledge his claim between 64 to 76 words per minute. All things considered, sample speed 63 words per minute will close to reject his case. Furthermore, the choice will be he was producing a fake claim.
In any case, if the selection representative stretches out his acceptance region to positive/negative 7 words that is 63 to 77 words, he would be tolerating his case.
In this way, to finish up, Hypothesis Testing is a procedure to test claims about the population dependent on sample. It is a fascinating reasonable subject with a quite statistical jargon. You have to dive more to get familiar with the details.
Significance Level and Rejection Region for Hypothesis
Type I error probability is normally indicated by α and generally set to 0.05. The value of α is recognized as the significance level.
The rejection region is the set of sample data that prompts the rejection of the null hypothesis. The significance level, α, decides the size of the rejection region. Sample results in the rejection region are labelled statistically significant at level of α .
The impact of differing α is that If α is small, for example, 0.01, the likelihood of a type I error is little, and a ton of sample evidence for the alternative hypothesis is needed before the null hypothesis can be dismissed. Though, when α is bigger, for example, 0.10, the rejection region is bigger, and it is simpler to dismiss the null hypothesis.
Significance from p-values
A subsequent methodology is to evade the utilization of a significance level and rather just report how significant the sample evidence is. This methodology is as of now more widespread. It is accomplished by method of a p value. P value is gauge of power of the evidence against null hypothesis. It is the likelihood of getting the observed value of test statistic, or value with significantly more prominent proof against null hypothesis (Ho), if the null hypothesis of an investigation question is true. The less significant the p value, the more proof there is supportive of the alternative hypothesis. Sample evidence is measurably noteworthy at the α level just if the p value is less than α. They have an association for two tail tests. When utilizing a confidence interval to playout a two-tailed hypothesis test, reject the null hypothesis if and just if the hypothesized value doesn’t lie inside a confidence interval for the parameter.
Hypothesis Tests and Confidence Intervals
Hypothesis tests and confidence intervals are cut out of the same cloth. An event whose 95% confidence interval reject the hypothesis is an event for which p<0.05 under the relating hypothesis test, and the other way around. A p value is letting you know the greatest confidence interval that despite everything prohibits the hypothesis. As such, if p<0.03 against the null hypothesis, that implies that a 97% confidence interval does exclude the null hypothesis.
Hypothesis Tests for a Population Mean
We do a t test on the ground that the population mean is unknown. The general purpose is to contrast sample mean with some hypothetical population mean, to assess whether the watched the truth is such a great amount of unique in relation to the hypothesis that we can say with assurance that the hypothetical population mean isn’t, indeed, the real population mean.
Hypothesis Tests for a Population Proportion
At the point when you have two unique populations Z test facilitates you to choose if the proportion of certain features is the equivalent or not in the two populations. For instance, if the male proportion is equivalent between two nations.
Hypothesis Test for Equal Population Variances
F Test depends on F distribution and is utilized to think about the variance of the two impartial samples. This is additionally utilized with regards to investigation of variance for making a decision about the significance of more than two sample.
T test and F test are totally two unique things. T test is utilized to evaluate the population parameter, for example, population mean, and is likewise utilized for hypothesis testing for population mean. However, it must be utilized when we don’t know about population standard deviation. On the off chance that we know the population standard deviation, we will utilize Z test. We can likewise utilize T statistic to approximate population mean. T statistic is likewise utilised for discovering the distinction in two population mean with the assistance of sample means.
Z statistic or T statistic is utilized to assess population parameters such as population mean and population proportion. It is likewise used for testing hypothesis for population mean and population proportion. In contrast to Z statistic or T statistic, where we manage mean and proportion, Chi Square or F test is utilized for seeing if there is any variance inside the samples. F test is the proportion of fluctuation of two samples.
Conclusion
Hypothesis encourages us to make coherent determinations, the connection among variables, and gives the course to additionally investigate. Hypothesis for the most part results from speculation concerning studied behaviour, natural phenomenon, or proven theory. An honest hypothesis ought to be clear, detailed, and reliable with the data. In the wake of building up the hypothesis, the following stage is validating or testing the hypothesis. Testing of hypothesis includes the process that empowers to concur or differ with the expressed hypothesis.
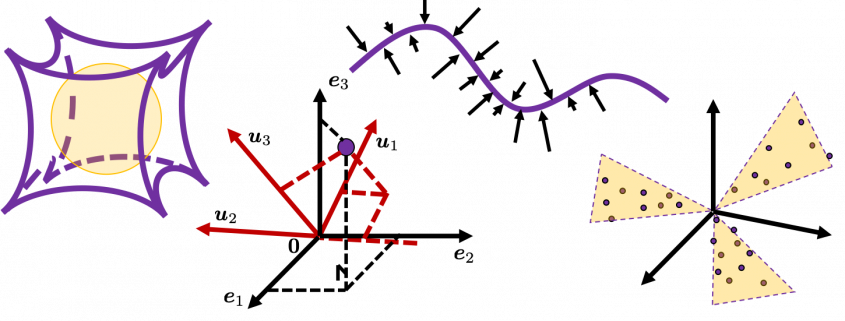
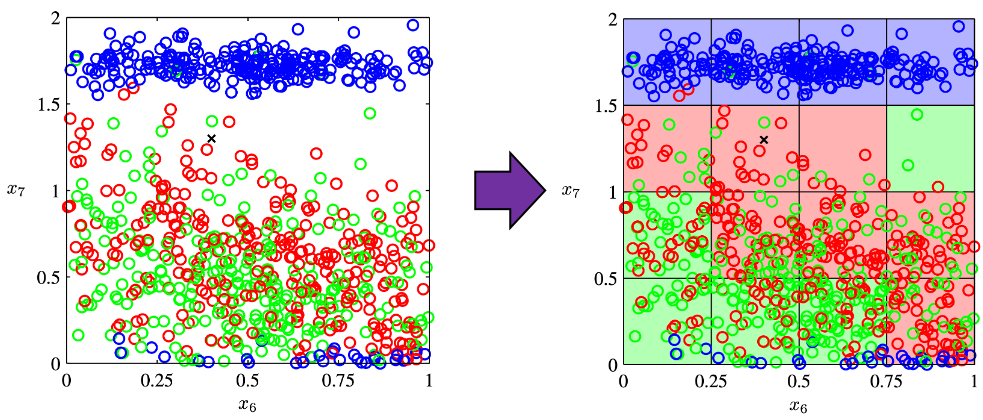
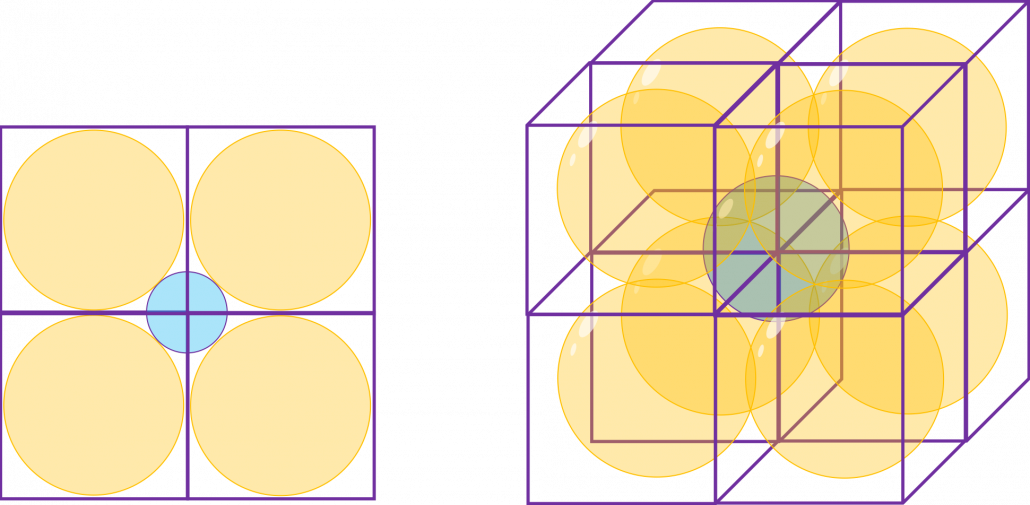
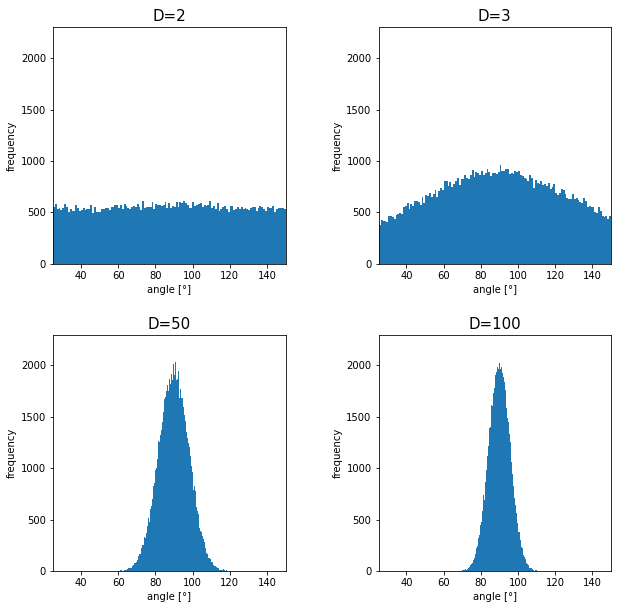
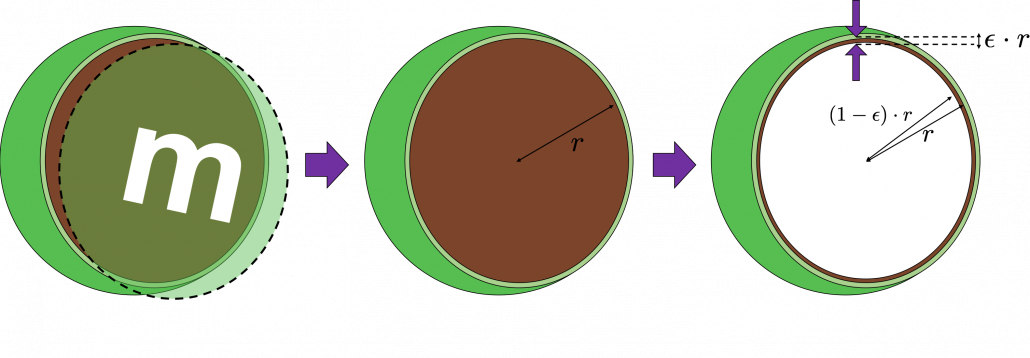
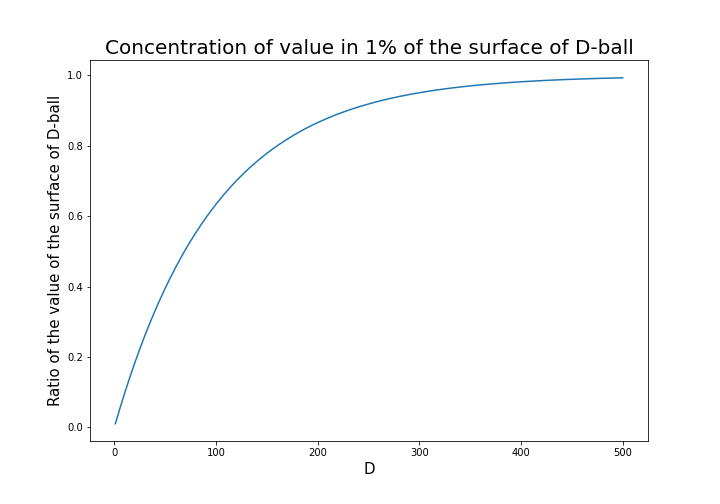
 grids respectively in 1, 2, 3 dimensional spaces, the number of the small regions in the grids are respectively 10, 100, 1000. Even though you cannot visualize it anymore, you can make grids for more than 3 dimensional data. If you continue increasing the degree of dimension, the number of grids increases exponentially, and that can soon surpass the number of training data points soon. That means there would be a lot of empty spaces in such high dimensional grids. And the classifying method above: coloring each grid and classifying unknown samples depending on the colors of the grids, does not work out anymore because there would be a lot of empty grids.
grids respectively in 1, 2, 3 dimensional spaces, the number of the small regions in the grids are respectively 10, 100, 1000. Even though you cannot visualize it anymore, you can make grids for more than 3 dimensional data. If you continue increasing the degree of dimension, the number of grids increases exponentially, and that can soon surpass the number of training data points soon. That means there would be a lot of empty spaces in such high dimensional grids. And the classifying method above: coloring each grid and classifying unknown samples depending on the colors of the grids, does not work out anymore because there would be a lot of empty grids.
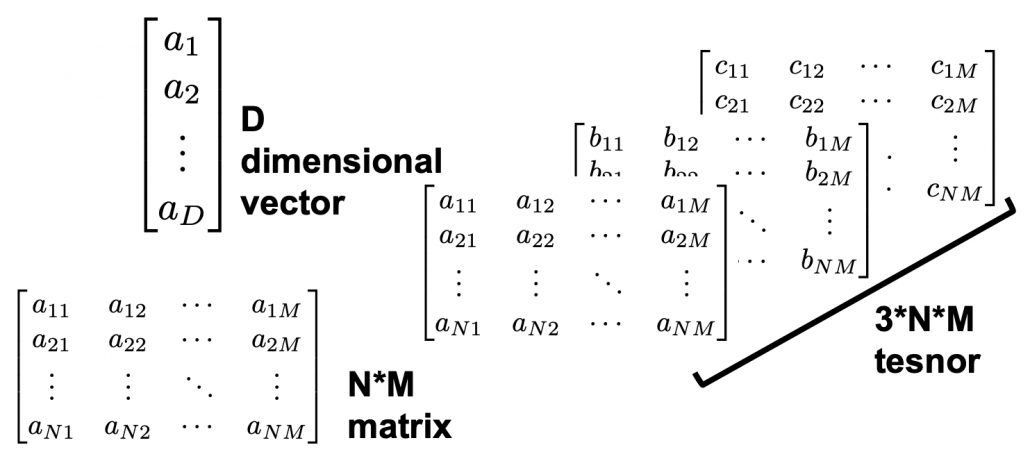
 in
in  dimensional space as below.
dimensional space as below.