Interview mit Dr. Christina Bender über die Digitalisierung und Data Science in einem 270-jährigem Familienunternehmen.
 Dr. Christina Bender ist Senior Digital Strategist mit Schwerpunkt auf Data Science bei der Villeroy & Boch AG. Sie ist Diplom-Finanzökonomin und promovierte Mathematikerin. Als „Quant“ bei der UniCredit und Unternehmensberaterin bei der d‑fine GmbH sammelte sie bereits langjährige Erfahrung in der Konzeption und Umsetzung interdisziplinärer Digitalisierungs- und Prozessthemen in diversen Branchen. Als letzte Herausforderung im „echten“ Beraterleben hat sie bei d-fine als Prokuristin den Geschäftsbereich „Digitalisierung im Gesundheitswesen“ mit aufgebaut.
Dr. Christina Bender ist Senior Digital Strategist mit Schwerpunkt auf Data Science bei der Villeroy & Boch AG. Sie ist Diplom-Finanzökonomin und promovierte Mathematikerin. Als „Quant“ bei der UniCredit und Unternehmensberaterin bei der d‑fine GmbH sammelte sie bereits langjährige Erfahrung in der Konzeption und Umsetzung interdisziplinärer Digitalisierungs- und Prozessthemen in diversen Branchen. Als letzte Herausforderung im „echten“ Beraterleben hat sie bei d-fine als Prokuristin den Geschäftsbereich „Digitalisierung im Gesundheitswesen“ mit aufgebaut.
In der Digital Unit bei V&B bündelt sie als eine Art interne Beraterin alle Aktivitäten rund um Data Science (interimsweise inklusive Process Digitisation) für den Gesamtkonzern von Produktion über SCM bis CRM und Sales von der Strategie bis zur Betreuung der Umsetzung. Als Gründungsmitglied der Digital Unit hat sie die neue Unit und die digitale Roadmap von V&B aktiv gestaltet.
In ihrer beruflichen Karriere spielten komplexe Zusammenhänge und Daten also schon früh eine Rolle. Durch ihr breites Erfahrungsspektrum hat sie gelernt, dass Daten erst zum Produktionsfaktor werden, wenn sie in Anwendungsgebieten richtig angepasst eingesetzt und überzeugend präsentiert werden.
Data Science Blog: Frau Dr. Bender, womit genau befassen Sie sich als Digital Strategist? Und wie passt Data Science in dieses Konzept?
Zunächst war es die Aufgabe eine digitale Roadmap zu entwickeln und zwar abgestimmt auf ein Traditionsunternehmen, das sich in den letzten 270 Jahren ständig durch Innovation verändert hat. Als Beispiel, V&B hatte einen erfolgreichen „Merger“ vollzogen, da gab es das Wort „M&A“ noch gar nicht.
Ein erster Schritt war es dabei Themen zu sammeln und ein Vorgehen zu entwickeln, diese zu verstehen, zu priorisieren und sie dann stets als Ziel im Blick umzusetzen. Die meisten der Themen haben immer mit Daten und damit häufig mit Data Science zu tun. Das geht von Fragestellungen z.B. im Vertrieb, die durch einen Bericht im ERP-System abbildbar sind, bis hin zu komplexen Fragen der Bilderkennungstechnologie in der Produktion oder im Customer Relationship Management.
Um weiterhin die wirklich wichtigen Themen zu finden, ist es entscheidend die Chancen und Risiken der Digitalisierung und den Wert der richtigen Daten weit in die Fläche des Unternehmens zu tragen. Dieser Aufbau interner Kompetenzen durch uns als Digital Unit schafft Vertrauen und ist neben dem Vorantreiben konkreter Anwendungsfälle essentieller Bestandteil für eine erfolgreiche Digitalisierung.
Data Science Blog: An was für Anwendungsfällen arbeiten Sie konkret? Und wohin geht die Reise langfristig?
Derzeit arbeiten wir sowohl an kleineren Fragestellungen als auch an ca. vier größeren Projekten. Letztere sollen pain points gemeinsam mit den Fachexperten lösen und dadurch zu Leuchtturmprojekten werden, um eben Vertrauen zu schaffen. Dafür müssen wir ein “Henne-Ei”-Problem lösen. Oft sind die richtigen Daten für die Fragestellung noch nicht erfasst und/oder einige Menschen involviert, die eben erst durch ihnen nahestehende Leuchtturmprojekte überzeugt werden müssten. Daher arbeiten wir für eine erfolgreiche Umsetzung mit im täglichen Geschäft involvierten Fachexperten und erfahrenen Data Scientists mit gewissem Fach-Know-How, die uns einen gewissen Vertrauensvorsprung geben.
Das dauert seine Zeit, insbesondere weil wir stark agil vorgehen, um uns nicht zu verheddern. D.h. oft sieht eine Fragestellung am Anfang leicht aus und ist dann schlicht weg nicht realisierbar. Das muss man dann akzeptieren und eben auf die nächst priorisierte Fragestellung setzen. “Keramik ist halt anders als die Autoindustrie.” Über genaue Use Cases möchte ich daher noch nicht sprechen. Wir sind auf einem guten Weg.
Langfristig wünsche ich mir persönlich, dass Werte aus Daten – insbesondere bessere Entscheidungen durch Wissen aus Daten – möglichst selbständig durch Business-Experten geschaffen werden und dies durch ein schlagkräftiges zentrales Team ermöglicht wird. D.h. das Team sorgt für eine entsprechende stets aktuell für Data Science geeignete Infrastruktur und steht bei komplexen Fragestellungen zur Verfügung.
Data Science Blog: Welche Algorithmen und Tools verwenden Sie für Ihre Anwendungsfälle?
Wir arbeiten auch mit Methoden im Bereich „Deep Learning“, zum Beispiel für die Bilderkennung. Allerdings gerade um die Erwartungshaltung im Unternehmen nicht zu hoch zu hängen, schauen wir immer wofür sich diese Methodik eignet und wo sie nicht unsere eigentliche Frage beantworten kann (siehe unten) oder schlicht weg nicht genügend Daten verfügbar sind. Insbesondere, wenn wir die eigentlich Ursache eines Problems finden und darauf reagieren wollen, ist es schlecht, wenn sich die Ursache „tief“ im Algorithmus versteckt. Dafür eignet sich z.B. eine logistische Regression, sofern gut parametrisiert und mit gut aufbereiteten Daten befüttert, häufig deutlich besser.
Wir nutzen kostenpflichtige Software und Open Source. Wunsch wäre, möglichst jedem im Unternehmen die richtige Anwendung zur Verfügung zu stellen, damit sie oder er leicht selbst die richtige Exploration erstellen kann, um die richtige Entscheidung zu treffen. Für den Data Scientist mag das ein anderes Tool sein als für den Fachexperten im Geschäftsbereich.
Data Science Blog: Daten werden von vielen Unternehmen, vermutlich gerade von traditionsreichen Familienunternehmen, hinsichtlich ihres Wertes unterschätzt. Wie könnten solche Unternehmen Daten besser bewerten?
Unternehmen müssen sich genau überlegen, was die für sie richtigen Fragen sind. Aus welchen Daten oder deren Verknüpfung kann ich Wissen generieren, dass diese für mich relevante Fragen (überhaupt) beantwortet werden können, um mit vertretbarem Aufwand nachhaltig Mehrwerte zu generieren. Natürlich sind die schlimmsten „pain points“ immer am schwierigsten, sonst hätte sie vermutlich jemand vor mir gelöst. Dies wird stets begleitet, warum mit den schon gesammelten Daten noch kein Mehrwert generiert wurde und somit ggf. begründet warum kein (Zeit-)Budget frei gegeben wird, um weitere (dann hoffentlich die richtigen) Daten zu sammeln.
Als erstes ist es m.E. daher wichtig dem Entscheidungsträger klar zu machen, dass es keine Maschine gibt in die ggf. wahllos gesammelte Daten reingeworfen werden und die „KI“ spuckt dann die richtigen Antworten auf die richtigen nie gestellten Fragen heraus. Denn gäbe es diese Art künstlicher Intelligenz, wäre der Erfinder wohl längst der reichste Mensch der Welt.
Nein, dafür wird menschliche Intelligenz gebraucht und Freiraum für die Mitarbeiterinnen und Mitarbeiter, die richtigen Fragen und Antworten zu suchen und auch auf diesem Weg manchmal kurzfristig zu scheitern. Kurz gesagt, braucht es eine Datenstrategie, um alle, Vorstand und Mitarbeiterinnen und Mitarbeiter, auf diesen Weg mitzunehmen.
Data Science Blog: Wie erstellen Unternehmen eine Datenstrategie?
Unternehmensleiter wollen Ergebnisse sehen und verstehen oft nicht gleich, warum sie Geld in Daten investieren sollen, wenn erst mittel- bis langfristig ein Mehrwert herausspringt. Die alleinige Drohkulisse, wenn nicht jetzt, dann eben in 10 Jahren ohne uns, hilft da oft nur bedingt oder ist gar kontraproduktiv.
Wichtig ist es daher, alle an einen Tisch zu holen und gemeinsam eine Unternehmensvision und Ziele zu diskutieren, zu begreifen und zu vereinbaren, dass Daten dafür ein Faktor sind (oder ggf. vorerst auch nicht). Noch wichtiger ist der Weg dahin, die Datenstrategie, nämlich wie aus Daten langfristig nachhaltige Mehrwerte gehoben werden.
Um eine Datenstrategie zu erstellen, braucht es eine gewisse Mindestausstattung einerseits an dafür zumindest zum Teil freigestellten Experten aus dem Business und anderseits Datenexperten, die mit diesen Experten reden können. Sie müssen nach erfolgreicher Zielbildung einen minimalen Werkzeugkasten aus KnowHow und Technologie schaffen, der es erst ermöglicht Leuchtturmprojekte erfolgreich umzusetzen. Diese Leuchtturmprojekte dienen als erste erfolgreiche Beispielwege. Damit fällt es auch leichter den Werkzeugkasten als Grundlage zur Lösung größerer pain points weiter auszubauen. In Zeiten, wo halbwegs kommunikative Data Scientists mit Businessverständnis Mangelware sind, ist dies manchmal nur mit externer Unterstützung möglich. Doch Obacht, wichtig ist ein interner Koordinator, der alle Zügel in Händen behält, damit nicht viele richtige Antworten auf irrelevante nicht gestellte Fragen gegeben werden. Denn dann geht anfängliche Akzeptanz leicht verloren.
Data Science Blog: Wie stellen Sie ein Data Science Team auf? Und suchen Sie für dieses Team eher Nerds oder extrovertierte Beratertypen?
Kurz und knapp: Die gesunde Mischung wie ich selbst.
Natürlich ist je nach Aufgabengebiet die Gewichtung etwas verschoben. Gerade in einem Unternehmen, das gerade erst den Wert von Daten am entdecken ist, ist es entscheidend, dass diese Werte den Businessexperten auch begreiflich gemacht bzw. mehr noch zusammen entwickelt werden. Dafür brauchen wir Menschen, die beides beherrschen. D.h. sie können komplizierte Inhalte anschaulich vermitteln – „Anteil extrovertierter Berater“, und hinter den Kulissen den tatsächlichen Wert aus Daten finden. Für letzteres brauchen wir die Eigenschaften eines „Nerds“. Mal ehrlich, durch meine Lehrtätigkeit habe ich selbst gelernt: Erst wenn ich etwas selbst verständlich erklären kann, habe ich es selbst verstanden und kann mein Tun stetig verbessern.
Dr. Christina Bender präsentiert am 15. November 2018, dem zweiten Tag der Data Leader Days 2018, über die „Tradition und digitale Innovation bei einem Keramikhersteller – warum Deep Learning nicht immer das Allheilmittel ist“. Mehr über die Data Leader Days erfahren Sie hier: www.dataleaderdays.com


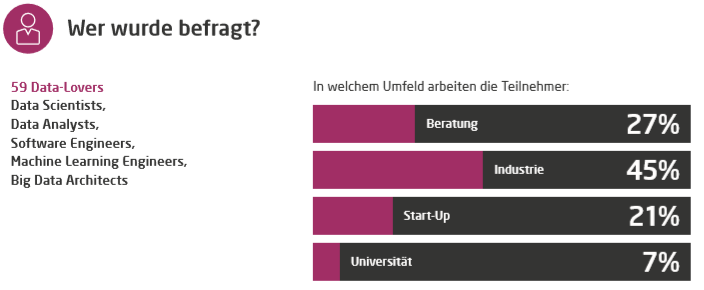






 Alice Albrecht ist Research Engineer bei
Alice Albrecht ist Research Engineer bei 


 Andreas Festl ist Data Scientist bei VIRTUAL VEHICLE, ein führendes F&E Zentrum für die Automobil- und Bahnindustrie mit Sitz in Graz, Österreich. Das Zentrum konzentriert sich auf die konsequente Virtualisierung der Fahrzeugentwicklung. Wesentliches Element dabei ist die Verknüpfung von numerischer Simulation und Hardware-Testen, welche ein umfassendes HW-SW Systemdesign sicherstellt. Herr Festl forscht dort an Kontext-basierten Informationssystemen für den Einsatz im Fahrzeug und in der Entwicklung. Er ist ausgebildeter Mathematiker, der sich schon früh dem Thema Data Science verschrieben hat. Zusätzlich ist Herr Festl in der Lehre für Data and Information Science an der Fachhochschule Joanneum tätig.
Andreas Festl ist Data Scientist bei VIRTUAL VEHICLE, ein führendes F&E Zentrum für die Automobil- und Bahnindustrie mit Sitz in Graz, Österreich. Das Zentrum konzentriert sich auf die konsequente Virtualisierung der Fahrzeugentwicklung. Wesentliches Element dabei ist die Verknüpfung von numerischer Simulation und Hardware-Testen, welche ein umfassendes HW-SW Systemdesign sicherstellt. Herr Festl forscht dort an Kontext-basierten Informationssystemen für den Einsatz im Fahrzeug und in der Entwicklung. Er ist ausgebildeter Mathematiker, der sich schon früh dem Thema Data Science verschrieben hat. Zusätzlich ist Herr Festl in der Lehre für Data and Information Science an der Fachhochschule Joanneum tätig.
 Miroslav Šedivý is a Senior Software Architect at UBIMET GmbH, using Python to make the sun shine and the wind blow. He is an enthusiast of both human and programming languages and found Python as his language of choice to setup very productive environments. Mr. Šedivý was born in Czechoslovakia, studied in France and is now living in Germany. Furthermore, he helps in the organization of the events PyCon.DE and Polyglot Gathering.
Miroslav Šedivý is a Senior Software Architect at UBIMET GmbH, using Python to make the sun shine and the wind blow. He is an enthusiast of both human and programming languages and found Python as his language of choice to setup very productive environments. Mr. Šedivý was born in Czechoslovakia, studied in France and is now living in Germany. Furthermore, he helps in the organization of the events PyCon.DE and Polyglot Gathering.
 Prof. Dr. Carsten Felden ist Vorsitzender des Vorstandes des TDWI e.V., der größten Community für Analytics und Buisness Intelligence.. Er ist selbst Experte und Consultant für Business Intelligence und für diesen Fachbereich Lehrstuhlinhaber an der TU Bergakademie Freiberg.
Prof. Dr. Carsten Felden ist Vorsitzender des Vorstandes des TDWI e.V., der größten Community für Analytics und Buisness Intelligence.. Er ist selbst Experte und Consultant für Business Intelligence und für diesen Fachbereich Lehrstuhlinhaber an der TU Bergakademie Freiberg.