
Data Science mit dem iPad Pro (und der Cloud)
Seit einiger Zeit versuche ich mein iPad Pro stärker in meinen Arbeitsaltag zu integrieren. Ähnlich wie Joseph (iPad Pro 10.5 as my Main Computer – Part 1, Part 2 und Part 3) sprechen auch für mich seit der Einführung des iPad Pro 9,7″, das nochmal verbesserte Display, die größeren Speicheroptionen, das faltbaren Smart Keyboard (funktioniert über einen seitlichen Konnektor und nicht über eine störanfällige BlueTooth-Verbindung) und der Apple Pencil dafür, dieses Gerät statt eines Notebooks zu nutzen.
Abbildung 1: Mein Homescreen
Neben der besseren Mobilität ist hier vor allen Dingen iOS 11 und das kommende iOS 12 zu nennen, welches mit einem verbesserte Dateisystem (transparente Einbindung von iCloud, DropBox, Google Drive etc.) und die Möglichkeit zwei Apps nebeneinander im Splitscreen auszuführen.
Apropos Apps: Diese sind ein weiteres Argument für mich, dieses Setup zu testen ist die unverändert gute bis sehr gute Qualität der verfügbaren iOS-Apps zu nutzen. Vorbei sind zum Glück die Zeiten, in der man keine eigenen Schriftarten (nach-) installieren kann (ich nutze dafür AnyFont), keine Kommendozeilenwerkzeug existieren (ich nutze StaSh), kein SSH-Tunneling (hier nutze ich SSH Tunnel von Yuri Bushev) funktioniert und sich GitHub/GitLab nicht nutzen lässt (hier nutze ich WorkingCopy). Ganze Arbeitsabläufe lassen sich darüber hinaus mit Hilfe von Workflow (und in iOS 12 mit Siri Shortcuts) automatisieren. Zum schreiben nutze ich verschiede Anwendungen, je nach Anwendungsfall. Für einfache (Markdown-) Texte nutze ich iA Writer und Editorial. Ulysses nutze ich nicht, da ich in dem Bereich Abomodelle nicht umbedingt bevorzuge, wenn es sich nicht vermeiden lässt.
Software Entwicklung
Die Entwicklung von Software nativ auf dem iPad Pro funktioniert am besten mit Pythonista. Für alles andere benötigt man entsprechende Server auf denen sich der benötigte Tool-Stack befindet, welchen man benötigt. Hier nutze ich am liebsten Linux-Systeme (CentOS oder Ubuntu) da diese sehr nah an Systemen sind, welche ich für Produktivsysteme nutze.
Mit der Nutzung von Cloud-Infrastrukturen wie sie einem zum Beispiel Amazon Web Service bietet, lassen sich sehr schnell und vor allen Dingen on-demand, Systeme starten. Schnell merkt man, dass sich dieser Vorgang stark automatisieren lässt, möchte man nicht ständig mit Hilfe der AWS Console arbeiten. Mit Pythonista und der StaSh lässt sich zu diesem Zweck sehr einfach die boto2-Bibliothek installieren, welche eine direkte Anbindung des AWS SDKs über Python ermöglicht. Damit wiederum lassen sich alle AWS-Dienste als Infrastructure-as-Code nutzen.
Mit boto3 lassen sich nicht nur EC2-Instanzen starten oder der Inhalt von S3-Buckets bearbeiten. Es können auch die verschiedenen Amazon-Dienste zum Beispiel aus dem Bereich Maschine Learning genutzt werden. Damit lassen sich dann leicht Objekte in Bildern erkennen oder der Inhalt von Texten analysieren.
Mosh und Blink
Möchte man effizient auf EC2-Instanzen arbeiten so lohnt ein Blick auf die UDP-basierte Mosh. Im Gegensatz zu normalen SSH-Verbindungen über TCP/IP, puffert Mosh Verbindungsabbrüche. So lassen sich Verbindungen auch nach mehreren Tagen noch ohne Probleme weiter nutzen. Genau wie SSH benötigt Mosh auch eine entsprechende Server-Komponente auf dem Host und ein Terminal, welches Mosh kann. Die Installation ist jedoch auch nicht schwieriger als bei anderer Software. Auf der Seite des iPads nutzte ich sowohl für SSH als auch Mosh die Termial-App Blink.
Mehrere Terminals
Wenn ich früher meinen Mac genutzt habe, dann hatte ich in der Regel mehr als eine (SSH-) Verbindung zum Zielsystem offen. Grund hierfür war, dass ich gern mehrere Dienste auf einem Server-Systems gleichzeitig im Auge behalten wollte. Ein oder zwei Fenster für die Ansicht von Logdateien mit ‘tail’, ein Fenster für meinen Lieblingseditor ‘vim’ und ein Fenster für die Arbeit auf der Kommandozeile. Seit dem ich das auf dem iPad mache, habe ich den Terminalmultiplexer tmux schätzen gelernt. Dieser ermöglicht, wie der Name sagt, die Verwaltung getrennter Sitzungen innerhalb eines Terminals (mehr dazu unter https://robots.thoughtbot.com/
Offline Dokumentation

Abbildung 2: Pythonista und Boto3 – Mit dem iPad die AWS kontrollieren
Seitdem es den Amazon Kindle in Deutschland gibt, nutze ich diesen Dienst. Ich hatte mir 2010 den Kindle2 noch aus den USA schicken lassen und dann irgendwann mein Konto auf den deutschen Kindle-Store migriert. Demnach nutze ich seit gut 9 Jahren die Kindle-Apps für meine Fachbücher. Auf dem iPad habe ich so bequem Zugriff auf über hundert IT- und andere Fachbücher. Papers und Cheat-Sheets speichere ich als PDFs in meinem DropBox- oder GoogleDrive-Account. Damit ich auch offline Zugriff auf die wichtigsten Manuelas habe (Python, git, ElasticSearch, Node.js etc.), nutze ich das freie Dash.
Data Science
Für die Entwicklung von MVPs für den Bereich Data Science ist Spark, und hier vor allen Dingen PySpark in Kombination mit Jupyter Notebook, mein Werkzeug der Wahl. Auf den ersten Blick eine Unmöglichkeit auf dem iPad. Auf den zweiten aber lösbar. In der Regel arbeite ich eh mit Daten, welche zu groß sind um auf einem normalen Personalcomputer in endlicher Zeit effizient verarbeitet werden zu können. Hier arbeite ich mehr und mehr in der Cloud und hier aktuell verstärkt in der von Amazon.
Mein Workflow funktioniert demnach so:
- Erstellung des nötigen Python Skripts für die Ausführung einer bestimmten AWS-Umgebung (EMR, SageMaker etc.) mit boto3 in Pythonista auf dem iPad
- Ausführen der Umgebung inkl. Kostenkontrolle (Billing-API)
- Aufbau eines SSH-Tunnels mit Hilfe eines SSH Tunnel / alternativ mit Mosh
- Nutzung von Blink bzw. SSH Pro für die SSH-Verbindung
- Nutzung von Juno um eine entfernte Jupyter Notebook / Jupyter Hub Installation nutzen zu können
PySpark im Jupyter Notebook
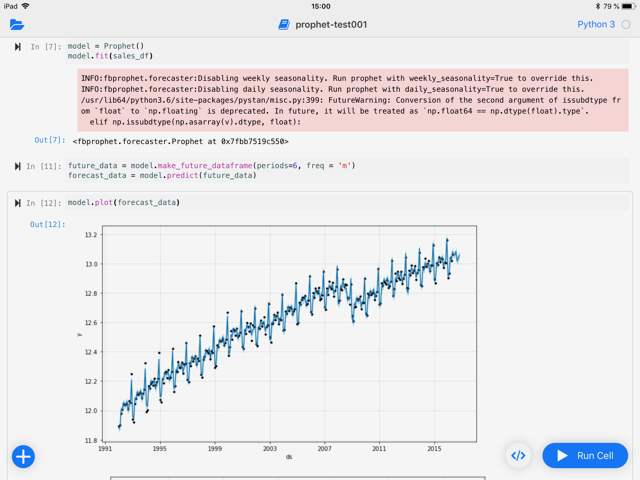
Abbildung 3: Mit Juno Jupyter Notebook aus auf dem iPad nutzen
Amazons Elastic Map Reduce Dienst bringt bereits eine Jupyter Notebook Installation inkl. Spark/PySpark mit und ermöglicht einen sicheren Zugang über einen verschlüsselten Tunnel. Einziges Problem bei der Nutzung von EMR: Alle Daten müssen in irgend einem System persistiert werden. Dies gilt nicht nur für die eigentlichen Daten sondern auch für die Notebooks. Günstiger Storage lässt sich über S3 einkaufen und mit Hilfe von s3fs-fuse (https://github.com/s3fs-fuse/
Fokussierung im Großraumbüro
Jeder der ab und zu mal in Großraumbüros, in der Bahn oder Flugzeug arbeitet muß, kennt das Problem: Ab und zu möchte man sein Umfeld so gut es geht ausblenden um sich auf die eigene Arbeit voll und ganz zu konzentrieren. Dabei helfen kleine und große Kopfhörer ob mit oder ohne Noice Cancelation. Mit sind die Kabellosen dabei am liebsten und ich nutze lieber In-Ears als Over-Ears wegen der Wärmeentwicklung. Ich mag einfach keine warme Ohren beim Denken. Nach dem das geklärt ist wäre die nächste Frage: Musik oder Geräusche. Ab und zu kann ich Musik beim Arbeiten ertragen wenn sie
1. ohne Gesang und
2. dezent rhythmisch ist.
Zum Arbeiten höre ich dann gern Tosca, Milch Bar, oder Thievery Corporation. Schreiben kann ich unter Geräuscheinwirkung aber besser. Hier nutze ich Noisly mit ein paar eignen Presets für Wald-, Wind- und Wassergeräusche.
Fazit
Das iPad Pro als Terminal des 21. Jahrhunderts bietet dank hervorragender Apps und der Möglichkeit zumindest Python nativ auszuführen, eine gute Ausgangsbasis für das mobile Arbeiten im Bereich Data Science. Hier muss man sich nur daran gewöhnen, dass man seinen Code nicht lokal ausführen kann, sondern dazu immer eine entsprechende Umgebung auf einem Server benötigt. Hier muß es nicht zwingend ein Server in der Cloud sein. Ein alter Rechner mit Linux und den nötigen Tools im Keller tut es auch. Für welches Modell man sich auch entscheidet, man sollte sehr früh Anfangen das Aufsetzten der entsprechenden Server-Umgebungen zu automatisieren (Infrastructure-as-Code). Auch hier bietet sich Pythonista (in Kombination mit Workflow) an. Was bei der täglichen Arbeit auf dem iPad manchmal stört ist, dass nicht alle Aktionen mit der Tastatur ausgeführt werden können und es hier immer noch zu einem haptischen Bruch kommt, wenn man einige Dingen nur über das Touch-Display macht und einige ausschließlich über die Tastatur. Manchmal würde ich mir auch ein größeres Display wünschen oder die Möglichkeit den Winkel des iPads auf der Tastatur ändern zu können. Diese Nachteile würde ich allerdings nicht gegen die Mobilität (Gewicht + Akkulaufzeit) eintauschen wollen.
Ramon Wartala
Ramon Wartala ist Director Data Science bei der SinnerSchrader AG in Hamburg. Sein Buch „Praxiseinstieg Deep Learning“ kam Ende letzten Jahres im O’Reilly Verlag heraus.








Leave a Reply
Want to join the discussion?Feel free to contribute!