Illustrative introductions on dimension reduction
"What is your image on dimensions?"
....That might be a cheesy question to ask to reader of Data Science Blog, but most…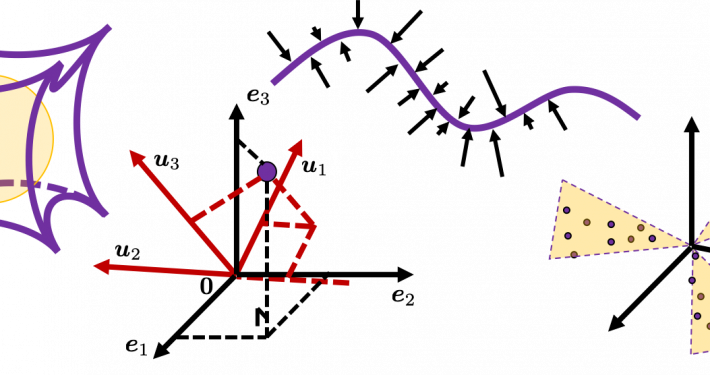
Spiky cubes, Pac-Man walking, empty M&M's chocolate: curse of dimensionality
"Curse of dimensionality" means the difficulties of machine learning which arise when the dimension of data is higher. In…
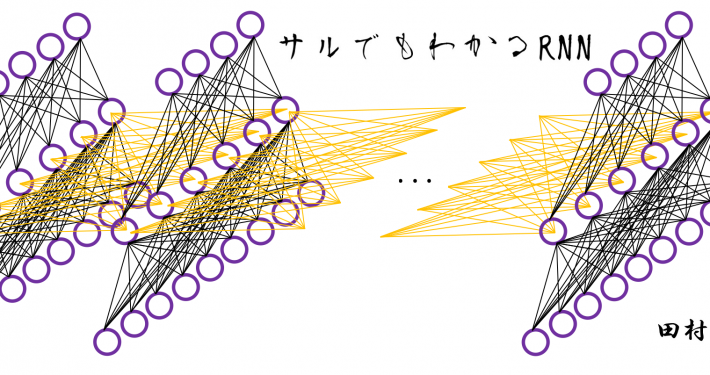
Back propagation of LSTM: just get ready for the most tiresome part
First of all, the summary of this article is "please just download my Power Point slides and be patient, following the equations."…
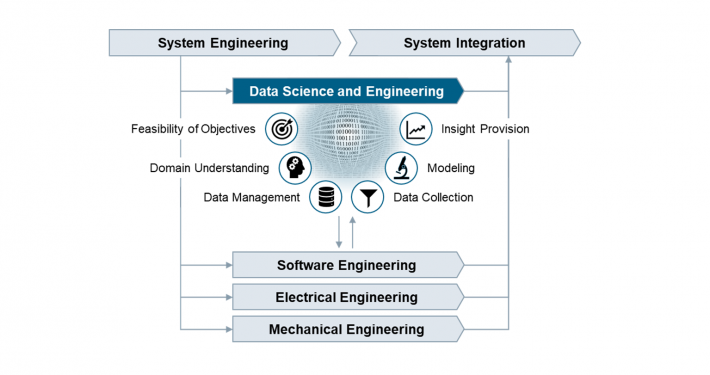
How to develop digital products and solutions for industrial environments?
In this article, we substantiate why Data Science and Engineering should be introduced as new engineering discipline in the Product Lifecycle Management process.
Understanding LSTM forward propagation in two ways
*This article is only for the sake of understanding the equations in the second page of the paper named "LSTM: A Search Space…
Hypothesis Test for real problems
A statistical hypothesis is a belief made about a population parameter. This belief may or might not be right. In other words, hypothesis testing is a proper technique utilized by scientist to support or reject statistical hypotheses. The foremost ideal approach to decide if a statistical hypothesis is correct is examine the whole population.

Must-have Skills to Master Data Science
The need to process a massive amount of data sets is making Data Science the most-demanded job across diverse industry verticals.…

Process Mining mit Celonis - Artikelserie
Insgesamt stellt Celonis ein unabhängiges und leistungsstarkes Process Mining Tool bereit, wobei der Anwender die Wahl zwischen einer on-Premise-Lösung sowie einer Cloud-Lösung hat. Die „prebuild Process-Connectors“ und die vordefinierten Analysen können ein Process Mining Projekt signifikant beschleunigen und somit die Time-to-Value lukrativ verkürzen. Die Analyse Tools sind leicht bedienbar und schaffen dank integrierter Machine Learning Algorithmen Optimierungspotentiale.

AI Voice Assistants are the Next Revolution: How Prepared are You?
According to Jeff Bezos, Amazon CEO, he says we’re already living in the golden era of artificial intelligence as such where the voice assistant flagship already exists, i.e. Alexa.









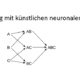



















KNN: Künstliche Neuronen
/5 Comments/in Big Data, Data Science, Machine Learning /by Nico HezelEs gibt sehr ausführliche Definitionen und Abbildungen für ein künstliches Neuron, die in diesem Artikel aber nicht behandelt werden. Der Grund dafür ist pragmatischer Natur. Es soll eine gewisse Konsistenz zu den anderen KNN-Beiträgen dieser Reihe bestehen und das Thema soll nicht zu einer wissenschaftlichen Abhandlung mutieren. In dem Beitrag KNN: Was sind künstliche neuronale […]
Interview – Big Data Analytics in der Versicherungsbranche
/0 Comments/in Big Data, Interview mit CIO, Interviews /by Benjamin AunkoferWelche Rolle spielt Big Data in der Versicherungsbranche? Ist Data Science bereits Alltag in einer Versicherung? Wenn ja, welche Analysen werden bereits durchgeführt? Hierzu haben wir den Datenarchitekt Norbert Schattner befragt und sehr interessante Antworten erhalten: Norbert Schattner ist Informations- & Datenarchitekt bei der Helsana AG in der Schweiz. Die Helsana AG ist ein Versicherungskonzern […]
Kontrolle und Steuerung von Spark Applikationen über REST
/0 Comments/in Big Data, Data Warehousing, Database /by Dr. Dietrich WettschereckApache Spark erfreut sich zunehmender Beliebtheit in der Data Science Szene da es in Geschwindigkeit und Funktionalität eine immense Verbesserung bzw. Erweiterung des reinen Hadoop MapReduce Programmiermodells ist. Jedoch bleibt Spark ebenso wie Hadoop eine Technologie für Experten. Es erfordert zumindest Kenntnisse von Unix-Skripten und muss über die Command-Line gesteuert werden. Die vorhandenen Weboberflächen bieten […]
KNN: Vorteile und Nacheile
/3 Comments/in Artificial Intelligence, Big Data, Data Science, GPU-Processing, Machine Learning /by Nico HezelWie jedes Verfahren haben auch künstliche Neuronale Netzwerke (KNN) ihre Vor- und Nachteile. Im Folgenden sollen einige benannt werden. Vorteile KNN können bessere Ergebnisse liefern als existierende statistische Ansätze, wenn das Problem ausreichend komplex ist. Das heißt, wenn das Problem nicht linear ist und es viele Eingabedaten mit vielen Variablen gibt. Es gibt zwar sogenannte […]
Komplexe Abläufe verständlich dargestellt mit Process Mining
/9 Comments/in Big Data, Business Analytics, Business Intelligence, Data Mining, Data Science, Process Mining /by Anne Rozinat & Christian W. GüntherStellen Sie sich vor, dass Ihr Data Science Team dabei helfen soll, die Ursache für eine wachsende Anzahl von Beschwerden im Kundenservice-Prozess zu finden. Sie vertiefen sich in die Daten des Service-Portals und generieren eine Reihe von Charts und Statistiken zur Verteilung der Beschwerden auf die verschiedenen Fachbereiche und Produktgruppen. Aber um das Problem zu […]
Auswertung von CSV- und Log-Dateien auf der Command Line mit awk
/2 Comments/in Data Mining, Data Science, Data Science at the Command Line /by Benjamin AunkoferDie Programmiersprache awk ist klein und unscheinbar, unter Data Science at the Command Line-Verfechtern allerdings ein häufiges Tool zur schnellen Analyse von CSV-Datein und vergleichbar strukturierten Daten (z. B. Logfiles) mit über Trennzeichen differenzierten Spalten. Auch in Shell-Skripten kommt awk meistens dann zum Einsatz, wenn es um den Zugriff, aber auch um die Manipulation von […]
KNN: Was sind künstliche neuronale Netze?
/4 Comments/in Artificial Intelligence, Big Data, Data Science, Machine Learning /by Nico HezelEin künstliches neuronales Netzwerk (KNN) besteht aus vielen miteinander verbundenen künstlichen Neuronen. Die einzelnen Neuronen haben unterschiedliche Aufgaben und sind innerhalb von Schichten (layer) angeordnet. Sogenannte Netzwerk Topologien geben vor, wie viele Neuronen sich auf einer Schicht befinden und welche Neuronen miteinander vernetzt sind. Neuronale Netze werden im Bereich der künstlichen Intelligenz eingesetzt und sind ein […]
Datenvisualisierung in Python [Tutorial]
/3 Comments/in Data Mining, Data Science, Python, Statistics, Tutorial, Visualization /by Benjamin AunkoferPython ist eine der wichtigsten Programmiersprachen in der Data Science Szene. Der Einstieg in diese Programmiersprache fällt zum Beispiel im Vergleich zur Programmiersprache R etwas einfacher, da Python eine leicht zu verstehende Syntax hat. Was jedoch beim Einstieg zur größeren Hürde werden kann, ist der Umgang mit den unüberschaubar vielen Bibliotheken. Die wichtigsten Bibliotheken für […]
Extraktion von Software-Metriken aus Java-Dateien mit ANTLR4
/1 Comment/in Data Mining, Data Science, Java, Re-Engineering /by Sven MeyerIn der Software-Entwicklung wird mehr und mehr auf Metriken gesetzt, um den Entwicklungsprozess zu messen und zu verbessern. Tools wie SonarQube und FindBugs helfen dabei – doch sie haben ihre Grenzen. Sie brauchen build-fähige Projekte. Die Metriken sind manchmal nicht genau genug dokumentiert oder lassen sich nur schwer anpassen. Dabei ist es gar nicht so […]
R für Process Mining & Projektmanagement – Literaturempfehlungen
/0 Comments/in Books, Process Mining, R Statistics, Statistics /by Dieter GennburgEs gibt immer wieder Skriptsprachen, die neu am IT-Horizont geboren um Anwender werben. Der IT-Manager muß also stets entscheiden, ob er auf einen neuen Zug aufspringt oder sein bisheriges Programmierwerkzeug aktuellen Anforderungen standhält. Mein Skriptsprachenkompass wurde über frühere Autoren kalibriert, an die hier erinnert werden soll, da sie grundsätzliche Orientierungshilfen für Projektplanungen gaben. Im Projektmanagement geht […]