Illustrative introductions on dimension reduction
"What is your image on dimensions?"
....That might be a cheesy question to ask to reader of Data Science Blog, but most…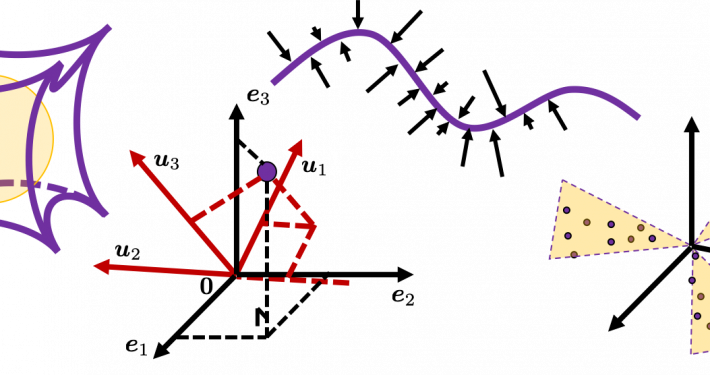
Spiky cubes, Pac-Man walking, empty M&M's chocolate: curse of dimensionality
"Curse of dimensionality" means the difficulties of machine learning which arise when the dimension of data is higher. In…
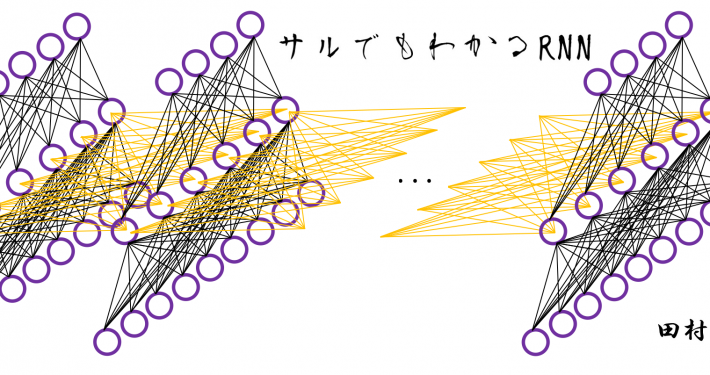
Back propagation of LSTM: just get ready for the most tiresome part
First of all, the summary of this article is "please just download my Power Point slides and be patient, following the equations."…
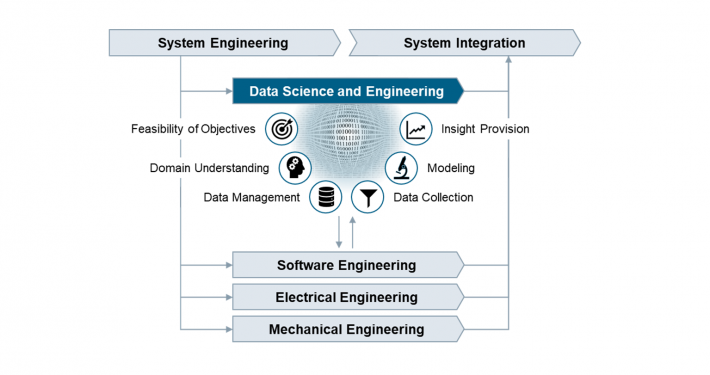
How to develop digital products and solutions for industrial environments?
In this article, we substantiate why Data Science and Engineering should be introduced as new engineering discipline in the Product Lifecycle Management process.
Understanding LSTM forward propagation in two ways
*This article is only for the sake of understanding the equations in the second page of the paper named "LSTM: A Search Space…
Hypothesis Test for real problems
A statistical hypothesis is a belief made about a population parameter. This belief may or might not be right. In other words, hypothesis testing is a proper technique utilized by scientist to support or reject statistical hypotheses. The foremost ideal approach to decide if a statistical hypothesis is correct is examine the whole population.

Must-have Skills to Master Data Science
The need to process a massive amount of data sets is making Data Science the most-demanded job across diverse industry verticals.…

Process Mining mit Celonis - Artikelserie
Insgesamt stellt Celonis ein unabhängiges und leistungsstarkes Process Mining Tool bereit, wobei der Anwender die Wahl zwischen einer on-Premise-Lösung sowie einer Cloud-Lösung hat. Die „prebuild Process-Connectors“ und die vordefinierten Analysen können ein Process Mining Projekt signifikant beschleunigen und somit die Time-to-Value lukrativ verkürzen. Die Analyse Tools sind leicht bedienbar und schaffen dank integrierter Machine Learning Algorithmen Optimierungspotentiale.

AI Voice Assistants are the Next Revolution: How Prepared are You?
According to Jeff Bezos, Amazon CEO, he says we’re already living in the golden era of artificial intelligence as such where the voice assistant flagship already exists, i.e. Alexa.




























Wahrscheinlichkeitesrechnung – Grundstein für Predictive Analytics
/6 Comments/in Data Science, Mathematics, Predictive Analytics, Statistics /by Benjamin AunkoferDie Wahrscheinlichkeitsrechnung behandelt die Gesetzmäßigkeiten des (von außen betrachtet) zufälligen Vorkommens bestimmter Ereignisse aus einer vorgegebenen Ereignismenge. Die mathematische Statistik fasst diese Wahrscheinlichkeitsrechnung zur Stochastik zusammen, der Mathematik des Zufalls. Mit diesem Artikel – zu der ich eine Serie plane – möchte ich den Einstieg in Predictive Analytics wagen, zugegebenermaßen ein Themengebiet, in dem man […]
Die Abschätzung von Pi mit Apache Spark
/0 Comments/in Apache Spark, Data Science, Data Science Hack, Experience, Main Category, optimization, Scala, Tools /by Dr. Mirco MüllerAuf den Berliner Data Science/Big Data/Data Analytics/…-Meetups auf denen ich in letzter Zeit des Öfteren zugegen war, tauchte immer wieder der Begriff Spark auf. Ich wollte wissen was es hiermit auf sich hat. Nachdem ich Spark 1.5.1 lokal auf meinem Mac installiert hatte, fing ich an Wörter in frei verfügbaren Texten zu zählen. Da es […]
Die Risiken der Datenverwaltung in der Cloud
/1 Comment/in Cloud, Data Security /by Ina VozgirdienėDie externe Cloud lockt als Alternative zu eigenen Servern, weil sie standardisierte und sofort nutzbare Dienste ohne Investitionskosten bietet. Immer mehr Unternehmen adoptieren webbasierte Technologien in ihren täglichen Aktivitäten und es scheint, dass eben jene webbasierte Applikationen und Business-Tools unsere Zukunft vorgeben. Diesen Vorteilen stehen jedoch auch Risiken gegenüber, die ein Unternehmen bedenken sollte, bevor […]
Wie lernen Maschinen?
/8 Comments/in Big Data, Data Mining, Machine Learning, optimization /by Dr. Stefan KühnIm zweiten Teil wollen wir das mit Abstand am häufigsten verwendete Optimierungsverfahren – das Gradientenverfahren oder Verfahren des steilsten Abstiegs – anhand einiger Beispiele näher kennen lernen. Insbesondere werden wir sehen, dass die Suchrichtung, die bei der Benennung der Verfahren meist ausschlaggebend ist, gar nicht unbedingt die wichtigste Zutat ist.
Daten in Formation bringen
/1 Comment/in Big Data, Business Analytics, Business Intelligence, Data Mining, Data Science, Text Mining /by Sven GalonskaBei den vielfach stattfindenden Diskussionen um und über den Begriff Big Data scheint es eine Notwendigkeit zu sein, Daten und Informationen gegeneinander abzugrenzen. Auf Berthold Brecht geht folgendes Zitat zurück: „Ein Begriff ist ein Griff, mit denen man Dinge bewegen kann“. Folgt man dieser Aussage, so kann man leicht die falschen Dinge bewegen, wenn man […]
Wie lernen Maschinen?
/12 Comments/in Big Data, Data Science, Machine Learning, optimization, Statistics /by Dr. Stefan KühnMachine Learning ist eines der am häufigsten verwendeten Buzzwords im Data-Science- und Big-Data-Bereich. Aber lernen Maschinen eigentlich und wenn ja, wie? In den meisten Fällen lautet die Antwort: Maschinen lernen nicht, sie optimieren. Fällt der Begriff Machine Learning oder Maschinelles Lernen, so denken viele sicherlich zuerst an bekannte “Lern”-Algorithmen wie Lineare Regression, Logistische Regression, Neuronale […]
Text-Mining mit dem Aika Algorithmus
/0 Comments/in Artificial Intelligence, Data Mining, Machine Learning, Text Mining /by Lukas MolzbergerIn diesem Beitrag möchte ich das Open Source Projekt Aika vorstellen. Ziel des Projektes ist es einen Text-Mining Algorithmus zu entwickeln, der ein künstliches Neuronales Netz (kNN) mit einem Pattern Mining Algorithmus kombiniert. Dabei dient die Silbentrennung von Wörtern als initiale Aufgabe, anhand derer der Algorithmus weiterentwickelt wird. Für diese Aufgabe soll allerdings kein vordefiniertes […]
Die üblichen Verdächtigen – 8 häufige Fehler in der Datenanalyse
/1 Comment/in Big Data, Data Mining, Data Science, Experience, Predictive Analytics, Statistics, Text Mining /by Nannette SwedDas eine vorab: eine Liste der meist begangenen Fehler in der Datenanalyse wird in jedem Fall immer eine subjektive Einschätzung des gefragten Experten bleiben und unterscheidet sich je nach Branche, Analyse-Schwerpunkt und Berufserfahrung des Analysten. Trotzdem finden sich einige Missverständnisse über viele Anwendungsbereiche der Datenanalyse hinweg immer wieder. Die folgende Liste gibt einen Überblick über […]
Interview – Bedeutung von Data Science für Deutschland
/22 Comments/in Big Data, Data Science, Interview mit CIO, Interviews /by Benjamin AunkoferKlaas Wilhelm Bollhoefer ist Chief Data Scientist bei The unbelievable Machine Company (*um), einem Full-Service Dienstleister für Cloud Computing und Big Data aus Berlin. Er übersetzt Business-Anforderungen in kundenspezifische Big Data Lösungen und agiert an der Schnittstelle von Business, IT, Künstlicher Intelligenz und Design. Er ist Community Manager diverser Fachgruppen sowie Mitglied in Beiräten und Jurys […]
KNN: Natur als Vorbild – Biologische Neuronen
/0 Comments/in Artificial Intelligence, Big Data, Data Science, Machine Learning, Main Category /by Radek MackowiakBisher ist die genaue Funktionsweise des Gehirns bei der Verarbeitung sensorischer Informationen nicht bekannt. Neue Erkenntnisse im Bereich der Neurowissenschaften liefern jedoch einen Einblick über grundlegende Prinzipien wie das Gehirn von Säugetieren sensorische Informationen repräsentiert. Einer der wichtigsten Punkte ist dabei die Erkenntnis, dass der Neocortex, einem ankommenden Signal erlaubt ein komplexes Netzwerk von Neuronen […]