Illustrative introductions on dimension reduction
"What is your image on dimensions?"
....That might be a cheesy question to ask to reader of Data Science Blog, but most…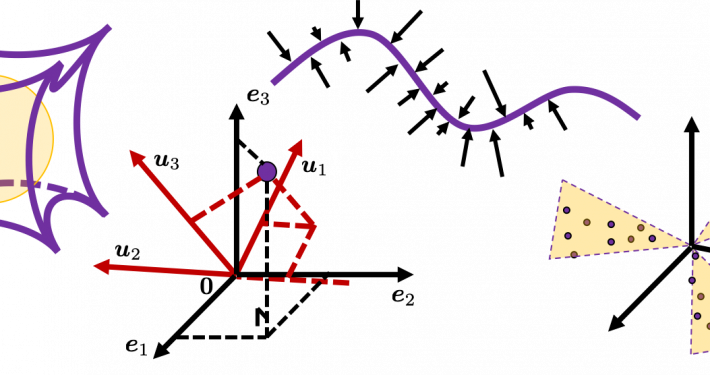
Spiky cubes, Pac-Man walking, empty M&M's chocolate: curse of dimensionality
"Curse of dimensionality" means the difficulties of machine learning which arise when the dimension of data is higher. In…
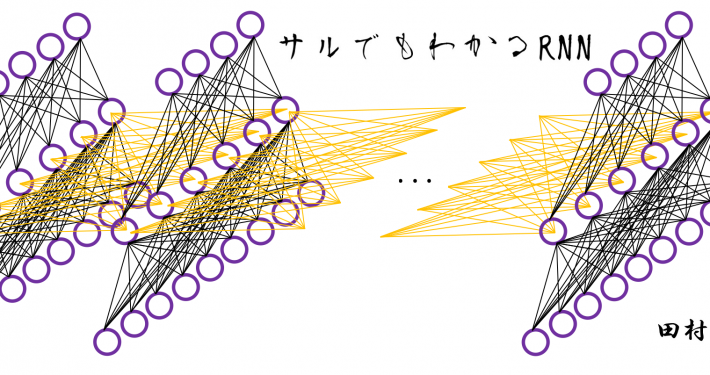
Back propagation of LSTM: just get ready for the most tiresome part
First of all, the summary of this article is "please just download my Power Point slides and be patient, following the equations."…
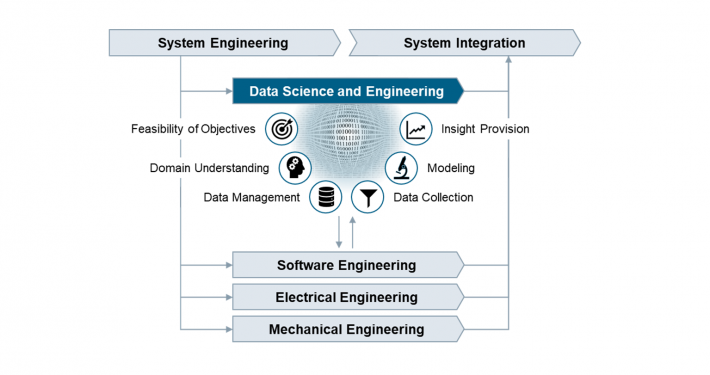
How to develop digital products and solutions for industrial environments?
In this article, we substantiate why Data Science and Engineering should be introduced as new engineering discipline in the Product Lifecycle Management process.
Understanding LSTM forward propagation in two ways
*This article is only for the sake of understanding the equations in the second page of the paper named "LSTM: A Search Space…
Hypothesis Test for real problems
A statistical hypothesis is a belief made about a population parameter. This belief may or might not be right. In other words, hypothesis testing is a proper technique utilized by scientist to support or reject statistical hypotheses. The foremost ideal approach to decide if a statistical hypothesis is correct is examine the whole population.

Must-have Skills to Master Data Science
The need to process a massive amount of data sets is making Data Science the most-demanded job across diverse industry verticals.…

Process Mining mit Celonis - Artikelserie
Insgesamt stellt Celonis ein unabhängiges und leistungsstarkes Process Mining Tool bereit, wobei der Anwender die Wahl zwischen einer on-Premise-Lösung sowie einer Cloud-Lösung hat. Die „prebuild Process-Connectors“ und die vordefinierten Analysen können ein Process Mining Projekt signifikant beschleunigen und somit die Time-to-Value lukrativ verkürzen. Die Analyse Tools sind leicht bedienbar und schaffen dank integrierter Machine Learning Algorithmen Optimierungspotentiale.

AI Voice Assistants are the Next Revolution: How Prepared are You?
According to Jeff Bezos, Amazon CEO, he says we’re already living in the golden era of artificial intelligence as such where the voice assistant flagship already exists, i.e. Alexa.























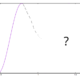





Die Rastrigin-Funktion
/0 Comments/in Mathematics, optimization, Python, Tutorial, Visualization /by Benjamin AunkoferJeder Data Scientist kommt hin und wieder mal in die Situation, einen Algorithmus trainieren bzw. optimieren zu wollen oder zu müssen, ohne jedoch, dass passende Trainingsdaten unmittelbar verfügbar wären. Zum einen kann man in solchen Fällen auf Beispieldaten zugreifen, die mit vielen Analysetools mitgeliefert werden, oder aber man generiert sich seine Daten via mathematischer Modelle […]
Python vs R Statistics
/1 Comment/in Data Mining, Data Science, Python, R Statistics /by Benjamin AunkoferImmer wieder wird mir von Einsteigern die Frage gestellt, ob sich der Einstieg und die Einarbeitung in die Programmiersprache Python eher lohnen würde als in R Statistics. Nun gibt es in den englischsprachigen Portalen bereits viele Diskussionen und Glaubenskriege zu diesem Vergleich – diese habe ich mir mit Absicht nicht weiter durchgelesen, sondern ich versuche […]
Statistical Relational Learning
/7 Comments/in Artificial Intelligence, Data Science, Machine Learning, Statistics /by Vishal BhallaAn Introduction to Statistical Relational Learning – Part 1 Statistical Relational Learning (SRL) is an emerging field and one that is taking centre stage in the Data Science age. Big Data has been one of the primary reasons for the continued prominence of this relational learning approach given, the voluminous amount of data available now […]
Was ist eigentlich Apache Spark?
/2 Comments/in Apache Spark, Big Data, Data Mining, Data Science, Data Science Hack, Data Warehousing, Database, Datacenter, Hadoop Framework, InMemory, Tool Introduction /by Benjamin AunkoferViele Technologieanbieter versprechen schlüsselfertige Lösungen für Big Data Analytics, dabei kann keine proprietäre Software-Lösung an den Umfang und die Mächtigkeit einiger Open Source Projekten heranreichen. Seit etwa 2010 steht das Open Source Projekt Hadoop, ein Top-Level-Produkt der Apache Foundation, als einzige durch Hardware skalierbare Lösung zur Analyse von strukturierten und auch unstrukturierten Daten. Traditionell im […]
Einführung in WEKA
/1 Comment/in Business Analytics, Business Intelligence, Data Mining, Data Science, Main Category, Statistics, Tool Introduction, Tutorial, Visualization /by Victoria IvanovaWaikato Environment for Knowledge Analysis, kurz WEKA, ist ein quelloffenes, umfangreiches, plattformunabhängiges Data Mining Softwarepaket. WEKA ist in Java geschrieben und wurde an der WAIKATO Iniversität entwickelt. In WEKA sind viele wichtige Data Mining/Machine Learning Algorithmen implementiert und es gibt extra Pakete, wie z. B. LibSVM für Support Vector Machines, welches nicht in WEKA direkt […]
Erfolgskriterien für Process Mining
/4 Comments/in Big Data, Business Analytics, Data Science, Experience, Process Mining, Tool Introduction, Visualization /by Anne Rozinat & Christian W. GüntherProcess Mining ist viel mehr als die automatische Erstellung von Prozessmodellen Process Mining ist auf dem Vormarsch. Durch Process Mining können Unternehmen erkennen, wie ihre Prozesse in Wirklichkeit ablaufen [1]. Die Ergebnisse liefern erstaunliche Einblicke in die Prozessabläufe, die Sie anderweitig nicht bekommen können. Jedoch gibt es auch einige Dinge, die schiefgehen können. In diesem […]
Data Driven Thinking
/4 Comments/in Big Data, Business Analytics, Business Intelligence, Carrier, Experience, Gerneral, Industrie 4.0, Main Category /by Benjamin AunkoferDaten gelten als vierter Produktionsfaktor – diese Erkenntnis hat sich mittlerweile in den meisten Führungsetagen durchgesetzt. Während das Buzzword Big Data gerade wieder in der Senke verschwindet, wird nun vor allem von der Data Driven Company gesprochen, oder – im Kontext von I4.0 – von der Smart Factory. Entsprechend haben die meisten Konzerne in den […]
Interview – OTTO auf dem Weg zum intelligenten Echtzeitunternehmen
/1 Comment/in Big Data, Business Analytics, Business Intelligence, Carrier, Experience, Gerneral, Interview mit CIO, Interviews, Use Case /by Benjamin AunkoferInterview mit Dr. Michael Müller-Wünsch über die Bedeutung von Data Science für den Online-Handel Dr. Michael Müller-Wünsch ist seit August 2015 CIO der OTTO-Einzelgesellschaft in Hamburg. Herr Müller-Wünsch studierte die Diplom-Studiengänge Informatik sowie BWL mit Schwerpunkt Controlling an der TU Berlin. In seinen Rollen als IT-Leiter und CIO wurde er mehrfach für seine Leistungen ausgezeichnet […]
Neuronale Netzwerke zur Spam-Erkennung
/1 Comment/in Artificial Intelligence, Big Data, Data Mining, Data Science, Data Security, Experience, Hacking, Machine Learning, Main Category, Predictive Analytics, Use Case /by Maximilian OedingerDie Funktionsweise der in immer mehr Anwendungen genutzten neuronalen Netzwerke stieß bei weniger technik-affinen Menschen bislang nur auf wenig Interesse. Geschuldet wird das sicher vor allem der eher trockenen Theorie, die hinter diesen Konstrukten steht und die sich für die meisten nicht auf Anhieb erschließt. Ein populäres Beispiel für die Fähigkeiten, die ein solches neuronales […]
Eine Hadoop Architektur mit Enterprise Sicherheitsniveau
/2 Comments/in Big Data, Data Science Hack, Data Security, Data Warehousing, Database, Datacenter, Hacking, Hadoop, Hadoop Framework, Main Category, Tutorial /by Georgios GkekasDies ist Teil 3 von 3 der Artikelserie zum Thema Eine Hadoop-Architektur mit Enterprise Sicherheitsniveau. Die ideale Lösung Man denkt, dass die Integration einer sehr alten Technologie, wie ActiveDirectory oder LDAP zusammen mit einem etablierten und ausgereiften Framework wie Hadoop reibungslos funktionieren würde. Leider sind solche Annahmen in der IT Welt zu gut um wahr zu […]