Optimize AI Talent: Perception from Across the Globe
Despite the AI hype, the AI skill gap is turning into some pariah while businesses are accelerating to become demigods.
Reports from the “Global Talent Competitiveness Index (GTCI) 2020” cover multiple parameters both national and organizational to generate insight for further action. This report compiles 70 variables including 132 national economies across the globe – based on all groups of income and at every developmental level.
The sole purpose of the GTCI report is to narrow down the skill gap by delivering the right data inputs. The figures mentioned in the report could be of value to private and public organizations.
GTCI report covered multiple themes that need to be addressed: –
As the race to embrace AI spurs, it is evident to address the challenges faced due to AI and how best these problems can be solved.
The pace at which AI is developing is transforming the way we work, forcing a technology shift, change in the corporate structure, changing the innovation system for AI professionals in every possible way.
There’s more that is needed to be done as AI and automation continue to affect the way we work.
- Reskilling in workplaces to eliminate dearth of talent
As the role in AI keeps evolving, organizations need a larger workforce, especially to play technology roles such as AI engineers and AI specialists. Looking closely at the statistics you may not fail to notice that the number of AI job roles is on the rise, but there’s scarce talent.
Employers must take on reskilling as a critical measure. Else how will the technology market keep up with changing trends? Reskilling in the form of training or AI certifications should be emphasized. Having an in-house AI talent is an added advantage to the company.
- Skill gap between growing countries (low performing and high performing) are widening
Based on the GTCI report, it is seen there is a skill gap happening not only across industries but between nations. The report also highlights which country lacks basic digital skills, and this highly gets contributed toward a digital divide between nations.
- High-level of cooperation needed to embrace AI benefits
As much as the world shows concern toward embracing AI, not much has been done to achieve these transformations. And AI has huge potential to transform society and make it a better place to live. However, to embrace these benefits, corporations must engage in AI regulation.
From a talent acquisition perspective, this simply means employers will need more training and reskilling opportunities.
- AI to allow nations to skip generations
On a technological front, AI makes it possible to skip generations in developed nations. Although, not common due to structural obstruction.
- Cities are now competing to become talent magnets and AI hubs
As AI continues to hit the market, organizations are aggressively coming up with newer policies to attract and retain AI professionals.
No doubt, cities are striving to attract the right kind of talent as competition keeps increasing. As such many cities are competing in becoming core AI engines in transforming energy grids, transportation, and many other multiple segments. Cities are now becoming the main test beds for AI-based tools i.e. self-driven vehicles, tele-surveillance, and facial recognition.
- Sustainable AI comes when the society is equally up for it
With certain communities not adopting and accepting the advent of AI, it is difficult to say whether these communities will not try to distort AI narratives. As a result, it is crucial for multiple stakeholders to embrace AI and developed the AI workforce in parallel.
Not to forget, regulators and policy-makers have an equal role to play to ensure there’s a smooth transition in jobs. As AI-induced transformation skyrockets, educators and leaders need to move quickly as the new generations’ complete focus is entirely based on doing their bit to the society.
Two decades passed ever since McKinsey declared the war for talent – particularly for high-performing employees. As organizations are extensively looking to hire the right talent, it is imperative to retain and attract talent at large.
Despite the unprecedented growth in AI technologies, it is near to being unanimous regarding having hold of organizations to master in AI, forget about retaining talent. They’re not even getting better at it.
Even top tech companies such as Google and Amazon, the demand for top talent outstrips the supply. Although you may find thousands of candidates applying for the same job role, the competition just gets tougher since such employers are tough nuts and pleasing them is not an easy task.
If these tech giants are finding it difficult to hire the right talent, you could imagine the plight of other companies.
Given the optimistic view regarding the technology future, it is much more challenging to convince that the war for talent truly resembles the war on talent.
The good news is organizations that look forward to adopting new technology and reskill their employees will most likely thrive in the competitive edge.

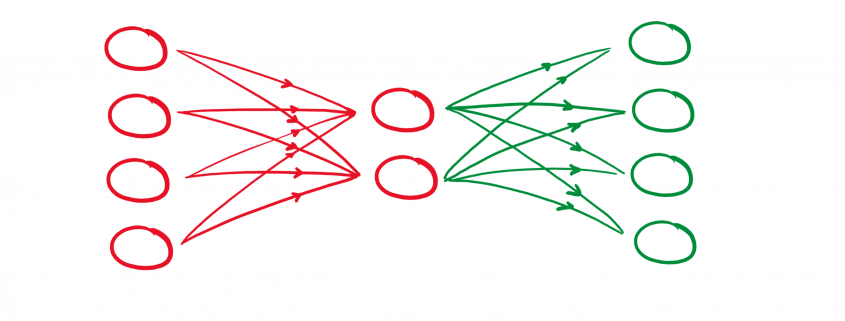
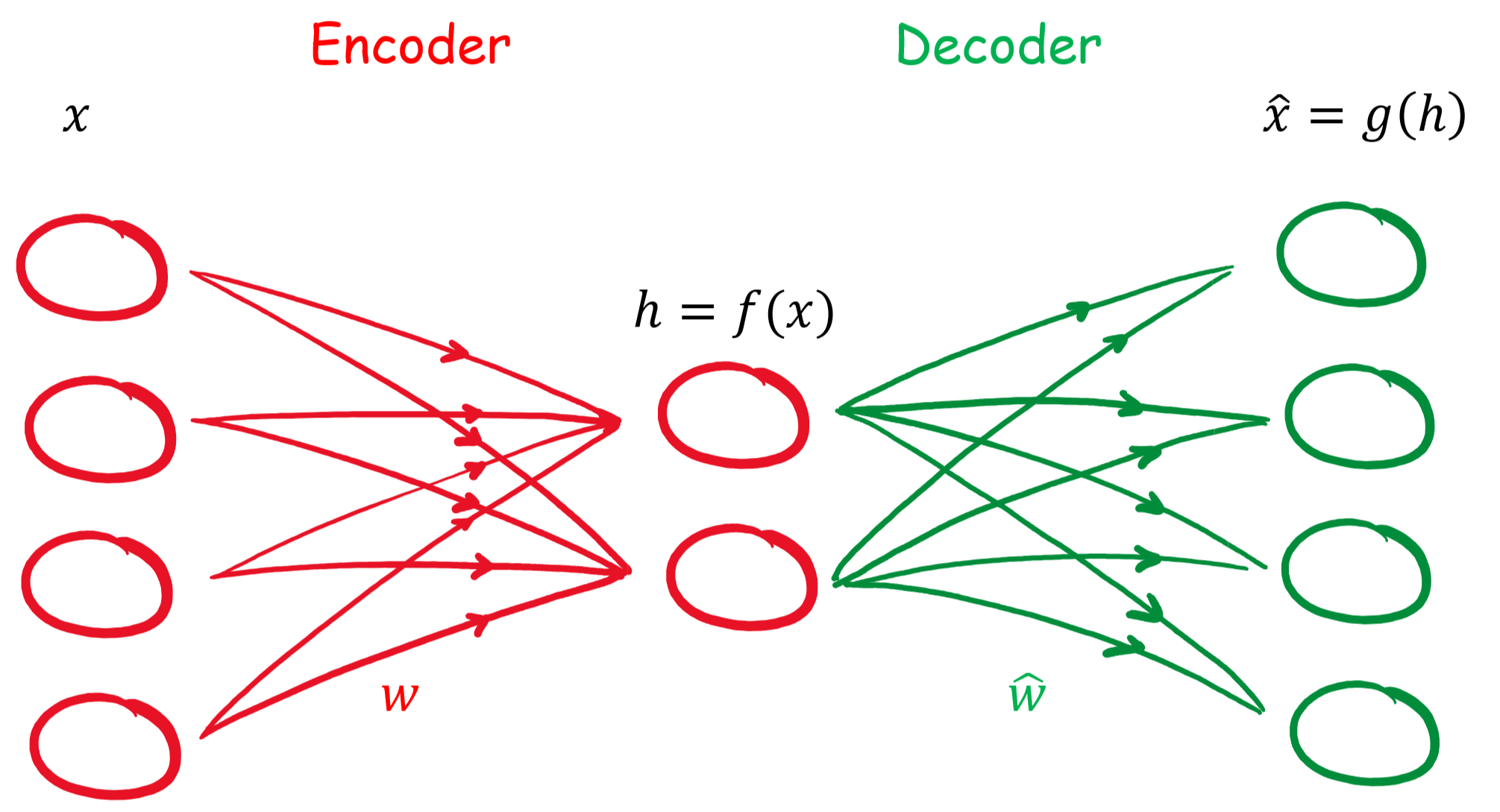






 gekennzeichnet werden. Damit besteht der Zusammenhang:
gekennzeichnet werden. Damit besteht der Zusammenhang:![\begin{align*} \mathbf{h} &= f(\mathbf{x}) = \sigma(\mathbf{W}\mathbf{x} + \mathbf{B}) \\ \hat{\mathbf{x}} &= g(\mathbf{h}) = \hat{\sigma}(\hat{\mathbf{W}} \mathbf{h} + \hat{\mathbf{B}}) \\ \hat{\mathbf{x}} &= \hat{\sigma} \{ \hat{\mathbf{W}} \left[\sigma ( \mathbf{W}\mathbf{x} + \mathbf{B} )\right] + \hat{\mathbf{B}} \}\\ \end{align*}](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-96b9128bd26ff4d2975a372d338e15c4_l3.svg "Rendered by QuickLaTeX.com")
![\begin{align*} L(\mathbf{x}, \hat{\mathbf{x}}) &= \mathbf{MSE}(\mathbf{x}, \hat{\mathbf{x}}) = \| \mathbf{x} - \hat{\mathbf{x}} \| ^2 &= \| \mathbf{x} - \hat{\sigma} \{ \hat{\mathbf{W}} \left[\sigma ( \mathbf{W}\mathbf{x} + \mathbf{B} )\right] + \hat{\mathbf{B}} \} \| ^2 \end{align*}](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-2afadab2e44942274d566bd163b513cf_l3.svg "Rendered by QuickLaTeX.com")
![\begin{align*} [1, 0, 0, 0] \ \widehat{=} \ 0 \\ [0, 1, 0, 0] \ \widehat{=} \ 1 \\ [0, 0, 1, 0] \ \widehat{=} \ 2 \\ [0, 0, 0, 1] \ \widehat{=} \ 3\\ \end{align*}](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-072135e2e36d72e0e3bf860c5308e03a_l3.svg "Rendered by QuickLaTeX.com")
![\begin{align*} [1, 0, 0, 0] \ \widehat{=} \ 0 \ \widehat{=} \ [0, 0] \\ [0, 1, 0, 0] \ \widehat{=} \ 1 \ \widehat{=} \ [0, 1] \\ [0, 0, 1, 0] \ \widehat{=} \ 2 \ \widehat{=} \ [1, 0] \\ [0, 0, 0, 1] \ \widehat{=} \ 3 \ \widehat{=} \ [1, 1] \\ \end{align*}](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-17422530a780bd436a53fc45b2a523aa_l3.svg "Rendered by QuickLaTeX.com")
 by
by