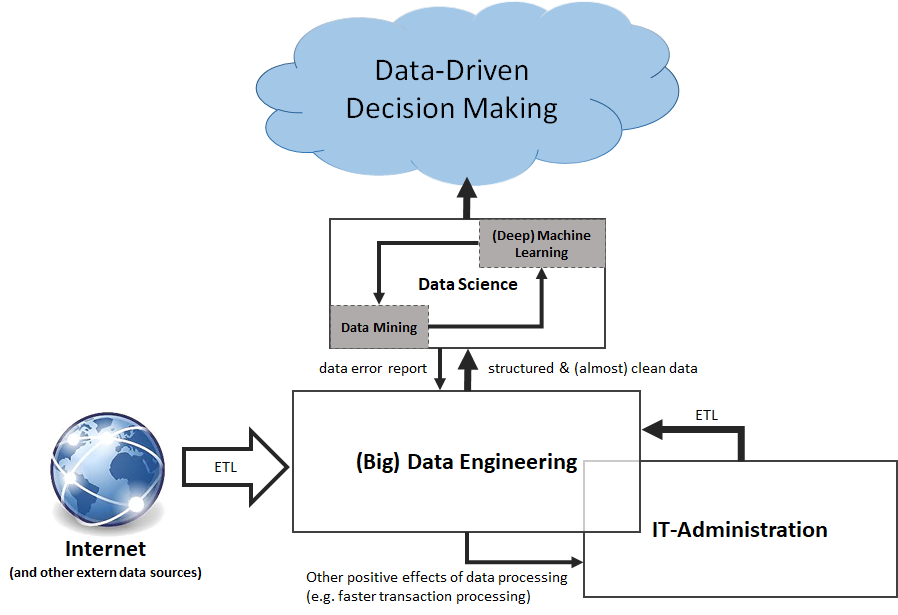
Ständig wachsende Datenflut – Muss nun jeder zum Data Scientist werden?
Weltweit rund 163 Zettabyte – so lautet die Schätzung von IDC für die Datenmenge weltweit im Jahr 2025. Angesichts dieser kaum noch vorstellbaren Zahl ist es kein Wunder, wenn Anwender in Unternehmen sich überfordert fühlen. Denn auch hier muss vieles analysiert werden – eigene Daten aus vielen Bereichen laufen zusammen mit Daten Dritter, seien es Dienstleister, Partner oder gekaufter Content. Und all das wird noch ergänzt um Social Content – und soll dann zu sinnvollen Auswertungen zusammengeführt werden. Das ist schon für ausgesprochene Data Scientists keine leichte Aufgabe, von normalen Usern ganz zu schweigen. Doch es gibt eine gute Nachricht dabei: den Umgang mit Daten kann man lernen.
Echtes Datenverständnis – Was ist das?
Unternehmen versuchen heute, möglichst viel Kapital aus den vorhandenen Daten zu ziehen und erlauben ihren Mitarbeitern kontrollierten, aber recht weit gehenden Zugriff. Das hat denn auch etliche Vorteile, denn nur wer Zugang zu Daten hat, kann Prozesse beurteilen und effizienter gestalten. Er kann mehr Informationen zu Einsichten verwandeln, Entwicklungen an den realen Bedarf anpassen und sogar auf neue Ideen kommen. Natürlich muss der Zugriff auf Informationen gesteuert und kontrolliert sein, denn schließlich muss man nicht nur Regelwerken wie Datenschutzgrundverordnung gehorchen, man will auch nicht mit den eigenen Daten dem Wettbewerb weiterhelfen.
Aber davon abgesehen, liegt in der umfassenden Auswertung auch die Gefahr, von scheinbaren Erkenntnissen aufs Glatteis geführt zu werden. Was ist wahr, was ist Fake, was ein Trugschluss? Es braucht einige Routine um den Unsinn in den Daten erkennen zu können – und es braucht zuverlässige Datenquellen. Überlässt man dies den wenigen Spezialisten im Haus, so steigt das Risiko, dass nicht alles geprüft wird oder auf der anderen Seite Wichtiges in der Datenflut untergeht. Also brauchen auch solche Anwender ein gewisses Maß an Datenkompetenz, die nicht unbedingt Power User oder professionelle Analytiker sind. Aber in welchem Umfang? So weit, dass sie fähig sind, Nützliches von Falschem zu unterscheiden und eine zielführende Systematik auf Datenanalyse anzuwenden.
Leider aber weiß das noch nicht jeder, der mit Daten umgeht: Nur 17 Prozent von über 5.000 Berufstätigen in Europa fühlen sich der Aufgabe gewachsen – das sagt die Data-Equality-Studie von Qlik. Und für Deutschland sieht es sogar noch schlechter aus, hier sind es nur 14 Prozent, die glauben, souverän mit Daten umgehen zu können. Das ist auch nicht wirklich ein Wunder, denn gerade einmal 49 Prozent sind (in Europa) der Ansicht, ausreichenden Zugriff auf Daten zu haben – und das, obwohl 85 Prozent glauben, mit höherem Datenzugriff auch einen besseren Job machen zu können.
Mit Wissens-Hubs die ersten Schritte begleiten
Aber wie lernt man denn nun, mit Daten richtig oder wenigstens besser umzugehen? Den Datenwust mit allen Devices zu beherrschen? An der Uni offensichtlich nicht, denn in der Data-Equality-Studie sehen sich nur 10 Prozent der Absolventen kompetent im Umgang mit Daten. Bis der Gedanke der Datenkompetenz Eingang in die Lehrpläne gefunden hat, bleibt Unternehmen nur die Eigenregie – ein „Learning by Doing“ mit Unterstützung. Wie viel dabei Eigeninitiative ist oder anders herum, wieviel Weiterbildung notwendig ist, scheint von Unternehmen zu Unternehmen unterschiedlich zu sein. Einige Ansätze haben sich jedoch schon bewährt:
- Informationsveranstaltungen mit darauf aufbauenden internen und externen Schulungen
- Die Etablierung von internen Wissens-Hubs: Data Scientists und Power-User, die ihr Know-how gezielt weitergeben: ein einzelne Ansprechpartner in Abteilungen, die wiederum ihren Kollegen helfen können. Dieses Schneeball-Prinzip spart viel Zeit.
- Eine Dokumentation, die gerne auch informell wie ein Wiki oder ein Tutorial aufgebaut sein darf – mit der Möglichkeit zu kommentieren und zu verlinken. Nützlich ist auch ein Ratgeber, wie man Daten hinterfragt oder wie man Datenquellen hinter einer Grafik bewertet.
- Management-Support und Daten-Incentives, die eine zusätzliche Motivation schaffen können. Dazu gehört auch, Freiräume zu schaffen, in denen sich Mitarbeiter mit Daten befassen können – Zeit, aber auch die Möglichkeit, mit (Test-)Daten zu spielen.
Darüber hinaus aber braucht es eine Grundhaltung, die sich im Unternehmen etablieren muss: Datenkompetenz muss zur Selbstverständlichkeit werden. Wird sie zudem noch spannend gemacht, so werden sich viele Mitarbeiter auch privat mit der Bewertung und Auswertung von Daten beschäftigen. Denn nützliches Know-how hat keine Nutzungsgrenzen – und Begeisterung steckt an.