How to develop digital products and solutions for industrial environments?
The Data Science and Engineering Process in PLM.
Huge opportunities for digital products are accompanied by huge risks
Digitalization is about to profoundly change the way we live and work. The increasing availability of data combined with growing storage capacities and computing power make it possible to create data-based products, services, and customer specific solutions to create insight with value for the business. Successful implementation requires systematic procedures for managing and analyzing data, but today such procedures are not covered in the PLM processes.
From our experience in industrial settings, organizations start processing the data that happens to be available. This data often does not fully cover the situation of interest, typically has poor quality, and in turn the results of data analysis are misleading. In industrial environments, the reliability and accuracy of results are crucial. Therefore, an enormous responsibility comes with the development of digital products and solutions. Unless there are systematic procedures in place to guide data management and data analysis in the development lifecycle, many promising digital products will not meet expectations.
Various methodologies exist but no comprehensive framework
Over the last decades, various methodologies focusing on specific aspects of how to deal with data were promoted across industries and academia. Examples are Six Sigma, CRISP-DM, JDM standard, DMM model, and KDD process. These methodologies aim at introducing principles for systematic data management and data analysis. Each methodology makes an important contribution to the overall picture of how to deal with data, but none provides a comprehensive framework covering all the necessary tasks and activities for the development of digital products. We should take these approaches as valuable input and integrate their strengths into a comprehensive Data Science and Engineering framework.
In fact, we believe it is time to establish an independent discipline to address the specific challenges of developing digital products, services and customer specific solutions. We need the same kind of professionalism in dealing with data that has been achieved in the established branches of engineering.
Data Science and Engineering as new discipline
Whereas the implementation of software algorithms is adequately guided by software engineering practices, there is currently no established engineering discipline covering the important tasks that focus on the data and how to develop causal models that capture the real world. We believe the development of industrial grade digital products and services requires an additional process area comprising best practices for data management and data analysis. This process area addresses the specific roles, skills, tasks, methods, tools, and management that are needed to succeed.
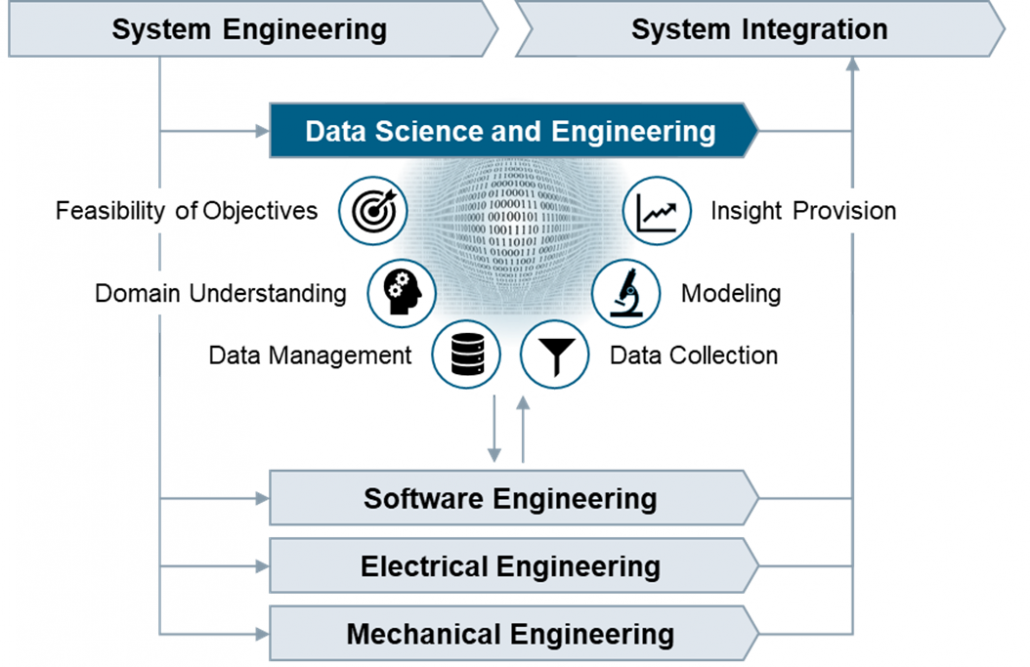
More than in other engineering disciplines, the outputs of Data Science and Engineering are created in repetitions of tasks in iterative cycles. The tasks are therefore organized into workflows with distinct objectives that clearly overlap along the phases of the PLM process.
| Feasibility of Objectives | |
| Understand the business situation, confirm the feasibility of the product idea, clarify the data infrastructure needs, and create transparency on opportunities and risks related to the product idea from the data perspective. | |
| Domain Understanding | |
| Establish an understanding of the causal context of the application domain, identify the influencing factors with impact on the outcomes in the operational scenarios where the digital product or service is going to be used. | |
| Data Management | |
| Develop the data management strategy, define policies on data lifecycle management, design the specific solution architecture, and validate the technical solution after implementation. | |
| Data Collection | |
| Define, implement and execute operational procedures for selecting, pre-processing, and transforming data as basis for further analysis. Ensure data quality by performing measurement system analysis and data integrity checks. | |
| Modeling | |
| Select suitable modeling techniques and create a calibrated prediction model, which includes fitting the parameters or training the model and verifying the accuracy and precision of the prediction model. | |
| Insight Provision | |
| Incorporate the prediction model into a digital product or solution, provide suitable visualizations to address the information needs, evaluate the accuracy of the prediction results, and establish feedback loops. |
Real business value will be generated only if the prediction model at the core of the digital product reliably and accurately reflects the real world, and the results allow to derive not only correct but also helpful conclusions. Now is the time to embrace the unique chances by establishing professionalism in data science and engineering.
Authors

Peter Louis

Peter Louis is working at Siemens Advanta Consulting as Senior Key Expert. He has 25 years’ experience in Project Management, Quality Management, Software Engineering, Statistical Process Control, and various process frameworks (Lean, Agile, CMMI). He is an expert on SPC, KPI systems, data analytics, prediction modelling, and Six Sigma Black Belt.

Ralf Russ
Ralf Russ works as a Principal Key Expert at Siemens Advanta Consulting. He has more than two decades experience rolling out frameworks for development of industrial-grade high quality products, services, and solutions. He is Six Sigma Master Black Belt and passionate about process transparency, optimization, anomaly detection, and prediction modelling using statistics and data analytics.4




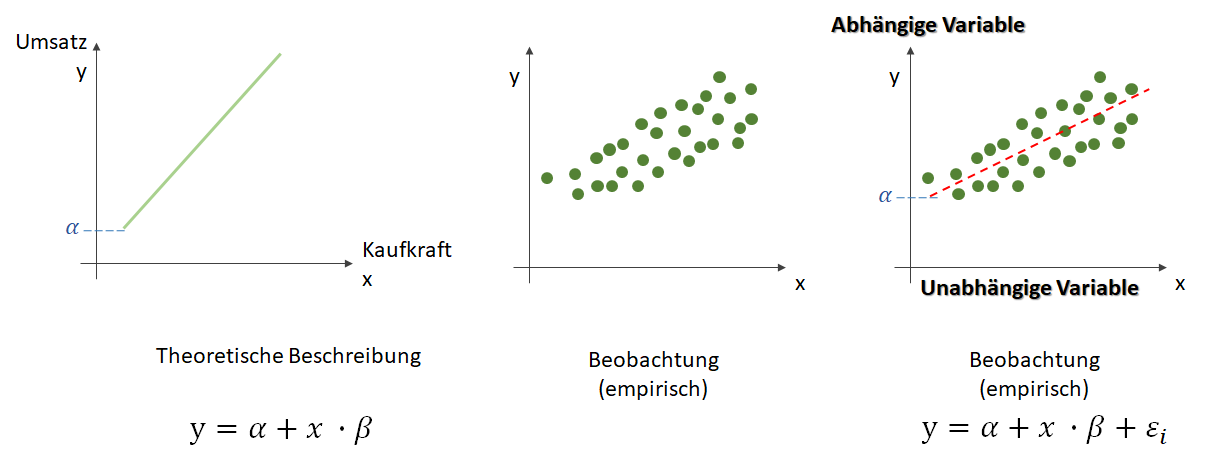
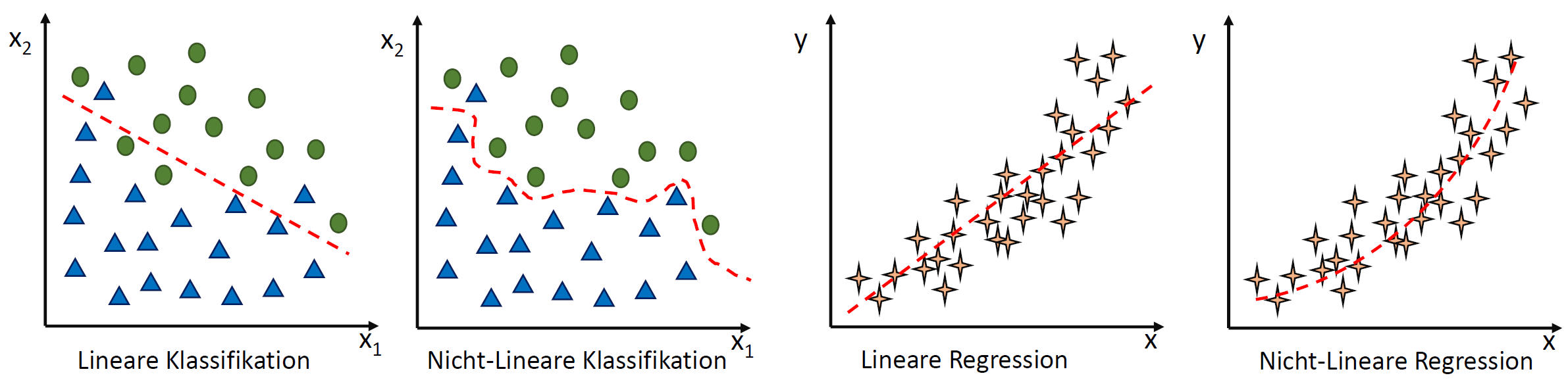
 , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  der Zielwert (abhängige Variable) und
der Zielwert (abhängige Variable) und  der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable
der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable  (Alpha) ist der
(Alpha) ist der  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung. ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.svg "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.svg "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.svg "Rendered by QuickLaTeX.com")
 .
.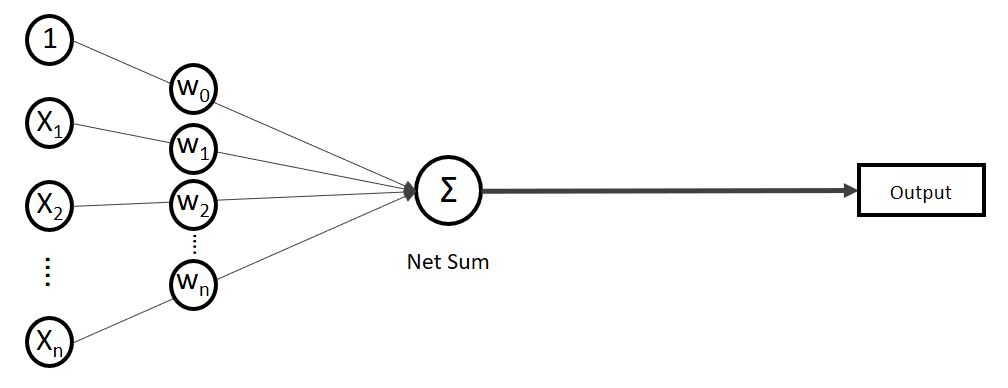
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
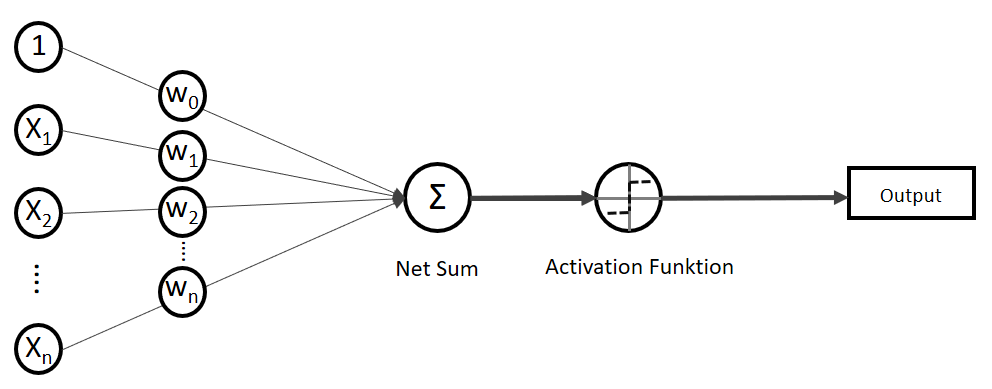
 (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 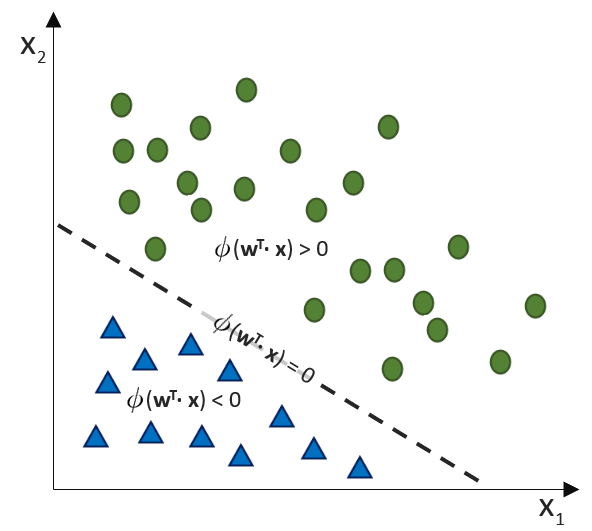
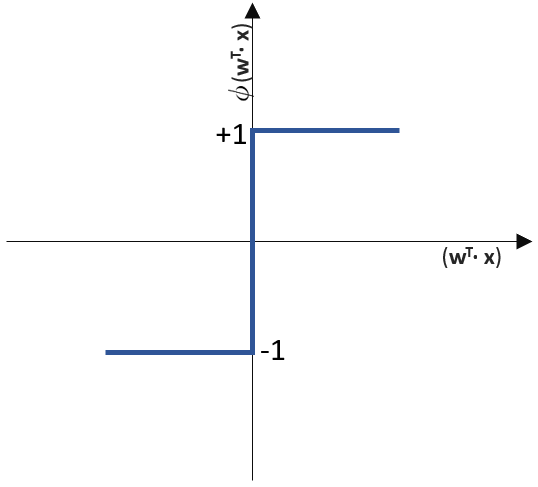
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.svg "Rendered by QuickLaTeX.com")