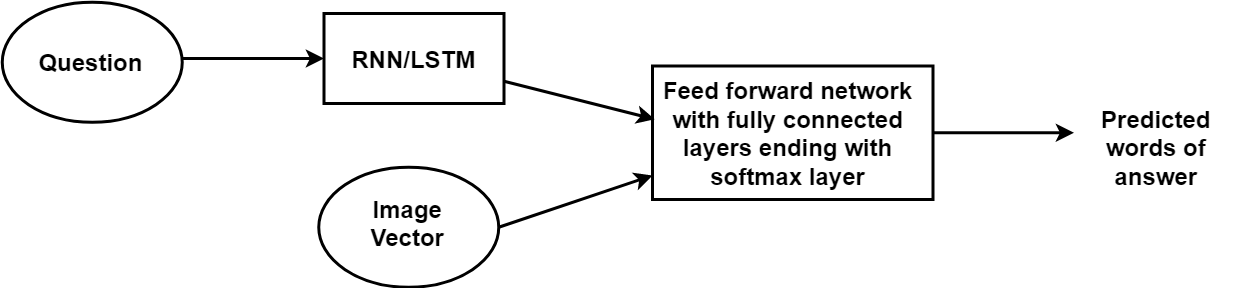
Wie der C++-Programmierer bei der Analyse großer Datenmengen helfen kann
Die Programmiersprache C wurde von Dennis Ritchie in den Bell Labs in einer Zeit (1969-1973) entwickelt, als jeder CPU-Zyklus und jeder Byte Speicher sehr teuer war. Aus diesem Grund wurde C (und später C++) so konzipiert, dass die maximale Leistung der Hardware mit der Sprachkomplexität erzielt werden konnte. Derzeit ist der C++ Programmierer besonders begehrt auf dem Arbeitsmarkt, für ganz bestimmte Abläufe, die wir später genauer beschreiben werden.
Warum sollten Sie einen C++ Entwickler mieten, wenn es um große Daten geht?
C++ ermöglicht, als Sprache auf einem niedrigen Level, eine Feinabstimmung der Leistung der Anwendung in einer Weise, die bei der Verwendung von Sprachen auf einem hohen Level nicht möglich ist. Warum sollten Sie einen C++ Entwickler mieten? C++ bietet den Entwicklern eine viel bessere Kontrolle über den Systemspeicher und die Ressourcen, als die der C Programmierer oder Anderer.
C++ ist die einzige Sprache, in der man Daten mit mehr als 1 GB pro Sekunde knacken, die prädiktive Analyse in Echtzeit neu trainieren und anwenden und vierstellige QPS einer REST-ful API in der Produktion bedienen kann, während die [eventuelle] Konsistenz des Aufzeichnungssystems ständig erhalten bleibt. Auf einem einzigen Server, natürlich aus Gründen der Zuverlässigkeit dupliziert, aber das, ohne in Repliken, Sharding und das Auffüllen und Wiederholen von persistenten Nachrichtenwarteschlangen investieren zu. Für ein groß angelegtes Werbesystem, dynamischen Lastausgleich oder eine hocheffiziente adaptive Caching-Schicht ist C++ die klügste Wahl.
Die allgemeine Vorstellung ist, dass R und Python schneller sind, aber das ist weit von der Wahrheit entfernt. Ein gut optimierter C++-Code könnte hundertmal schneller laufen, als das gleiche Stück Code, das in Python oder R geschrieben wurde. Die einzige Herausforderung bei C++ ist die Menge an Arbeit, die Sie bewältigen müssen, um die fertigen Funktionen zum Laufen zu bringen. Sie müssen wissen, wie man Zeiger verteilt und verwaltet – was ehrlich gesagt ein wenig kompliziert sein kann. Die C# Programmierer Ausbildung ist aus diesem Grunde z.Z. sehr begehrt.
R und Python
Akademiker und Statistiker haben R über zwei Jahrzehnte entwickelt. R verfügt nun über eines der reichsten Ökosysteme, um Datenanalysen durchzuführen. Es sind etwa 12000 Pakete in CRAN (Open-Source-Repository) verfügbar. Es ist möglich, eine Bibliothek zu finden, für was auch immer für eine Analyse Sie durchführen möchten. Die reiche Vielfalt der Bibliothek macht R zur ersten Wahl für statistische Analysen, insbesondere für spezialisierte analytische Arbeiten.
Python kann so ziemlich die gleichen Aufgaben wie R erledigen: Data Wrangling, Engineering, Feature Selection Web Scrapping, App und so weiter. Python ist ein Werkzeug, um maschinelles Lernen in großem Maßstab einzusetzen und zu implementieren. Python-Codes sind einfacher zu warten und robuster als R. Vor Jahren hatte Python nicht viele Bibliotheken für Datenanalyse und maschinelles Lernen. In letzter Zeit holt Python auf und bietet eine hochmoderne API für maschinelles Lernen oder künstliche Intelligenz. Der größte Teil der datenwissenschaftlichen Arbeit kann mit fünf Python-Bibliotheken erledigt werden: Numpy, Pandas, Scipy, Scikit-Learning und Seaborn.
Aber das Wissen, mit Zeigern zu arbeiten oder den Code in C++ zu verwalten, ist mit einem hohen Preis verbunden. Aus diesem Grunde werden C++ Programmierer gesucht, für die Bewältigung von großen Datenpaketen. Ein tiefer Einblick in das Innenleben der Anwendung ermöglicht es ihnen, die Anwendung im Falle von Fehlern besser zu debuggen und sogar Funktionen zu erstellen, die eine Kontrolle des Systems auf Mikroebene erfordern. Schauen Sie sich doch nach C# Entwickler in Berlin um, denn sie haben einen besonders guten Ruf unter den neuen Entwicklern.
Das Erlernen der Programmierung ist eine wesentliche Fähigkeit im Arsenal der Analysten von Big Data. Analysten müssen kodieren, um numerische und statistische Analysen mit großen Datensätzen durchzuführen. Einige der Sprachen, in deren Erlernen auch die C Entwickler Zeit und Geld investieren sollten, sind unter anderem Python, R, Java und C++. Je mehr sie wissen, desto besser – Programmierer sollten immer daran denken, dass sie nicht nur eine einzelne Sprache lernen sollten. C für Java Programmierer sollte ein MUSS sein.
Wo wird das C++ Programmieren eingesetzt?
Die Programmiersprache C++ ist eine etablierte Sprache mit einem großen Satz von Bibliotheken und Tools, die bereit ist, große Datenanwendungen und verteilte Systeme zu betreiben. In den meisten Fällen wird C++ zum Schreiben von Frameworks und Paketen für große Daten verwendet. Diese Programmiersprache bietet auch eine Reihe von Bibliotheken, die beim Schreiben von Algorithmen für das tiefe Lernen helfen. Mit ausreichenden C++-Kenntnissen ist es möglich, praktisch unbegrenzte Funktionen auszuführen. Dennoch ist C++ nicht die Sprache, die man leicht erlernen kann, da man die über 1000 Seiten Spezifikation und fast 100 Schlüsselwörter beherrschen muss.
Die Verwendung von C++ ermöglicht die prozedurale Programmierung für intensive Funktionen der CPU und die Kontrolle über die Hardware, und diese Sprache ist sehr schnell, weshalb sie bei der Entwicklung verschiedener Spiele oder in Spielmaschinen weit verbreitet ist.
C++ bietet viele Funktionen, die anderen Sprachen fehlen. Darüber hinaus bietet die Sprache auch Zugang zu umfangreichen Vorlagen, die es Ihnen ermöglichen, generische Codes zu schreiben. Als betroffenes Unternehmen sollten Sie sich deshalb tatsächlich überlegen, einen C++ Programmierer zu suchen oder in einen Kurs von C++ für Ihren C Programmierer zu investieren. Am Ende lohnen sich bestimmt diese Kosten.
Und vergessen Sie nicht: C++ ist die einzige Sprache, die in der Lage ist, 1 GB+ Daten in weniger als einer Sekunde zu verarbeiten. Darüber hinaus können Sie Ihr Modell neu trainieren und prädiktive Analysen in Echtzeit und sogar die Konsistenz der Systemaufzeichnung anwenden. Diese Gründe machen C++ zu einer bevorzugten Wahl für Sie, wenn Sie einen Datenwissenschaftler für Ihr Unternehmen suchen.
Beispiele für die Verwendung von C++
Die Verwendung von C++ zur Entwicklung von Anwendungen und vielen produktbasierten Programmen, die in dieser Sprache entwickelt wurden, hat mehrere Vorteile, die nur auf ihren Eigenschaften und ihrer Sicherheit beruhen. Unten finden Sie eine Liste der häufigsten Anwendungen von C++.
- Google-Anwendungen – Einige der Google-Anwendungen sind auch in C++ geschrieben, darunter das Google-Dateisystem und der Google-Chromium-Browser sowie MapReduce für die Verarbeitung großer Clusterdaten. Die Open-Source-Gemeinschaft von Google hat über 2000 Projekte, von denen viele in den Programmiersprachen C oder C++ geschrieben und bei GitHub frei verfügbar sind.
- Mozilla Firefox und Thunderbird – Der Mozilla-Internetbrowser Firefox und der E-Mail-Client Thunderbird sind beide in der Programmiersprache C++ geschrieben, und sie sind ebenfalls Open-Source-Projekte. Der C++-Quellcode dieser Anwendungen ist in den MDN-Webdokumenten zu finden.
- Adobe-Systeme – Die meisten der wichtigsten Anwendungen von Adobe-Systemen werden in der Programmiersprache C++ entwickelt. Zu diesen Anwendungen gehören Adobe Photoshop und Image Ready, Illustrator und Adobe Premier. Sie haben in der Vergangenheit eine Menge Open-Source-Codes veröffentlicht, immer in C++, und ihre Entwickler waren in der C++-Community aktiv.
- 12D-Lösungen – 12D Solutions Pty Ltd ist ein australischer Softwareentwickler, der sich auf Anwendungen im Bereich Bauwesen und Vermessung spezialisiert hat. Computer Aided Design-System für Vermessung, Bauwesen und mehr. Zu den Kunden von 12D Solutions gehören Umweltberater, Berater für Bau- und Wasserbau, lokale, staatliche und nationale Regierungsabteilungen und -behörden, Vermessungsingenieure, Forschungsinstitute, Bauunternehmen und Bergbau-Berater.
- In C/C++ geschriebene Betriebssysteme
Apple – Betriebssystem OS XApple – Betriebssystem OS X
Einige Teile von Apple OS X sind in der Programmiersprache C++ geschrieben. Auch einige Anwendungen für den iPod sind in C++ geschrieben.
Microsoft-BetriebssystemeMicrosoft-Betriebssysteme
Der Großteil der Software wird buchstäblich mit verschiedenen Varianten von Visual C++ oder einfach C++ entwickelt. Die meisten der großen Anwendungen wie Windows 95, 98, Me, 200 und XP sind ebenfalls in C++ geschrieben. Auch Microsoft Office, Internet Explorer und Visual Studio sind in Visual C++ geschrieben.
- Betriebssystem Symbian – Auch Symbian OS wird mit C++ entwickelt. Dies war eines der am weitesten verbreiteten Betriebssysteme für Mobiltelefone.
Die Einstellung eines C- oder C++-Entwicklers kann eine gute Investition in Ihr Projekt-Upgrade sein
Normalerweise benötigen C- und C++-Anwendungen weniger Strom, Speicher und Platz als die Sprachen der virtuellen Maschinen auf hoher Ebene. Dies trägt dazu bei, den Kapitalaufwand, die Betriebskosten und sogar die Kosten für die Serverfarm zu reduzieren. Hier zeigt sich, dass C++ die Gesamtentwicklungskosten erheblich reduziert.
Trotz der Tatsache, dass wir eine Reihe von Tools und Frameworks nur für die Verwaltung großer Daten und die Arbeit an der Datenwissenschaft haben, ist es wichtig zu beachten, dass auf all diesen modernen Frameworks eine Schicht einer niedrigen Programmiersprache – wie C++ – aufgesetzt ist. Die Niedrigsprachen sind für die tatsächliche Ausführung des dem Framework zugeführten Hochsprachencodes verantwortlich. Es ist also ratsam in ein C-Entwickler-Gehalt zu investieren.
Der Grund dafür, dass C++ ein so unverzichtbares Werkzeug ist, liegt darin, dass es nicht nur einfach, sondern auch extrem leistungsfähig ist und zu den schnellsten Sprachen auf dem Markt gehört. Darüber hinaus verfügt ein gut geschriebenes Programm in C++ über ein komplexes Wissen und Verständnis der Architektur der Maschine, sowie der Speicherzugriffsmuster und kann schneller laufen als andere Programme. Es wird Ihrem Unternehmen Zeit- und Stromkosten sparen.
Zum Abschluss eine Grafik, die Sie als Unternehmer interessieren wird und die das Verhältnis von der Performance and der Sicherheit diverser Sprachen darstellt:
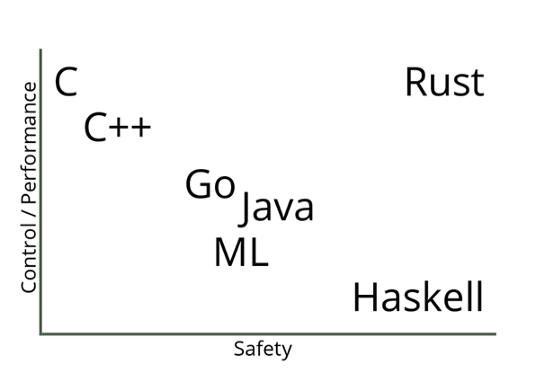
Aus diesen und weiteren Gründen neigen viele Unternehmensentwickler und Datenwissenschaftler mit massiven Anforderungen an Skalierbarkeit und Leistung zu dem guten alten C++. Viele Organisationen, die Python oder andere Hochsprachen für die Datenanalyse und Erkundungsaufgaben verwenden, verlassen sich auf C++, um Programme zu entwickeln, die diese Daten an die Kunden weiterleiten – in Echtzeit.

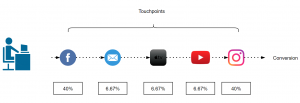
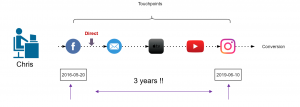
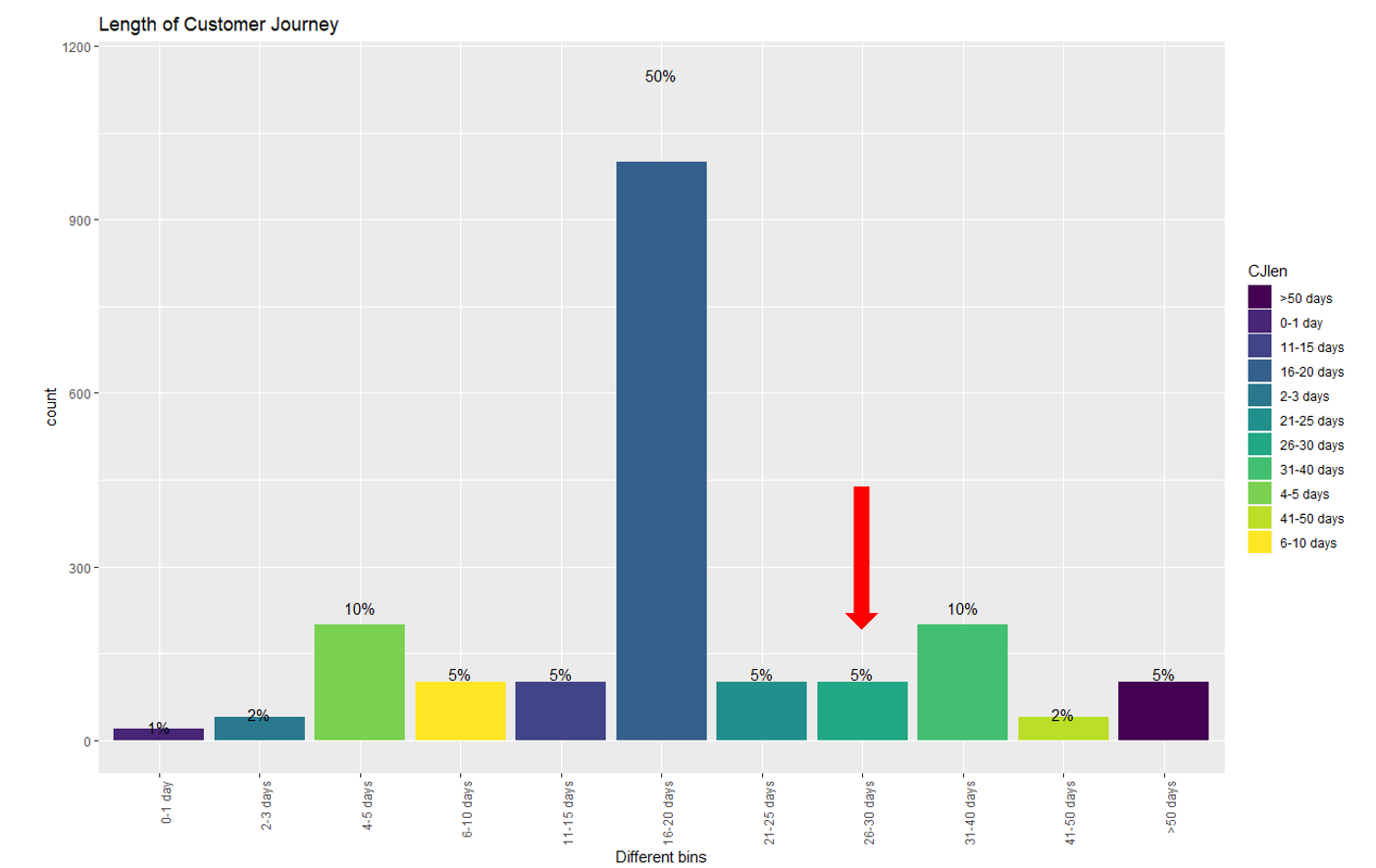











 Dr. Andreas Warntjen arbeitet seit Juli 2016 bei der Thalia Bücher GmbH, aktuell als Senior Manager Advanced and Predictive Analytics. Davor hat Herr Dr. Warntjen viele Jahre als Sozialwissenschaftler an ausländischen Universitäten geforscht. Er hat selbst langjährige Erfahrung in der statistischen Datenanalyse mit Stata, SPSS und R und arbeitet im Moment mit der in-memory Datenbank SAP HANA sowie Python und SAP’s Automated Predictive Library (APL).
Dr. Andreas Warntjen arbeitet seit Juli 2016 bei der Thalia Bücher GmbH, aktuell als Senior Manager Advanced and Predictive Analytics. Davor hat Herr Dr. Warntjen viele Jahre als Sozialwissenschaftler an ausländischen Universitäten geforscht. Er hat selbst langjährige Erfahrung in der statistischen Datenanalyse mit Stata, SPSS und R und arbeitet im Moment mit der in-memory Datenbank SAP HANA sowie Python und SAP’s Automated Predictive Library (APL).