Process Mining Tools – Artikelserie
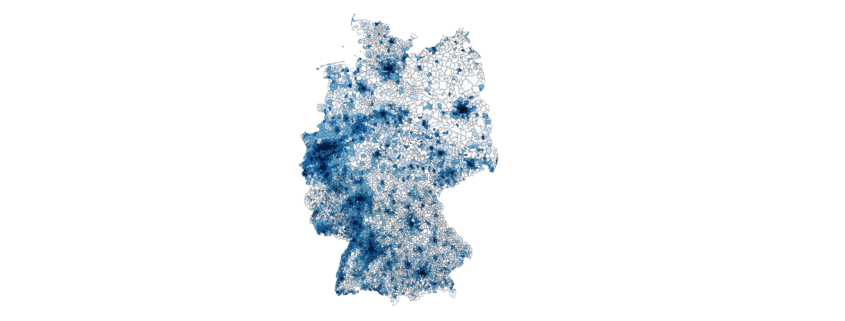
Process Mining ist nicht länger nur ein Buzzword, sondern ein relevanter Teil der Business Intelligence. Process Mining umfasst die Analyse von Prozessen und lässt sich auf alle Branchen und Fachbereiche anwenden, die operative Prozesse haben, die wiederum über operative IT-Systeme erfasst werden. Um die zunehmende Bedeutung dieser Data-Disziplin zu verstehen, reicht ein Blick auf die Entwicklung der weltweiten Datengenerierung an. Waren es 2010 noch 2 Zettabytes (ZB), sind laut Statista für das Jahr 2020 mehr als 50 ZB an Daten zu erwarten. Für 2025 wird gar mit einem Bestand von 175 ZB gerechnet.
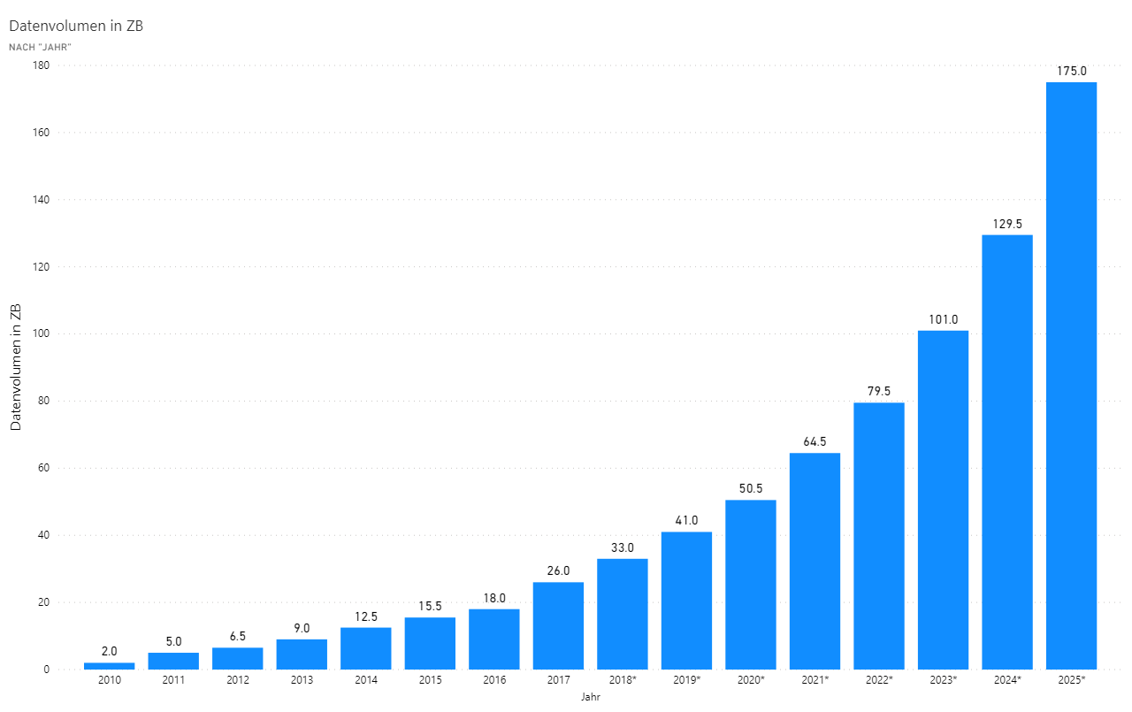
Abbildung 1 zeigt die Entwicklung des weltweiten Datenvolumen (Stand 2018). Quelle: https://www.statista.com/statistics/871513/worldwide-data-created/
Warum jetzt eigentlich Process Mining?
Warum aber profitiert insbesondere Process Mining von dieser Entwicklung? Der Grund liegt in der Unordnung dieser Datenmenge. Die Herausforderung der sich viele Unternehmen gegenübersehen, liegt eben genau in der Analyse dieser unstrukturierten Daten. Hinzu kommt, dass nahezu jeder Prozess Datenspuren in Informationssystemen hinterlässt. Die Betrachtung von Prozessen auf Datenebene birgt somit ein enormes Potential, welches in Anbetracht der Entwicklung zunehmend an Bedeutung gewinnt.
Was war nochmal Process Mining?
Process Mining ist eine Analysemethodik, welche dazu befähigt, aus den abgespeicherten Datenspuren der Informationssysteme eine Rekonstruktion der realen Prozesse zu schaffen. Diese Prozesse können anschließend als Prozessflussdiagramm dargestellt und ausgewertet werden. Die klassischen Anwendungsfälle reichen von dem Aufspüren (Discovery) unbekannter Prozesse, über einen Soll-Ist-Vergleich (Conformance) bis hin zur Anpassung/Verbesserung (Enhancement) bestehender Prozesse. Mittlerweile setzen viele Firmen darüber hinaus auf eine Integration von RPA und Data Science im Process Mining. Und die Analyse-Tiefe wird zunehmen und bis zur Analyse einzelner Klicks reichen, was gegenwärtig als sogenanntes „Task Mining“ bezeichnet wird.
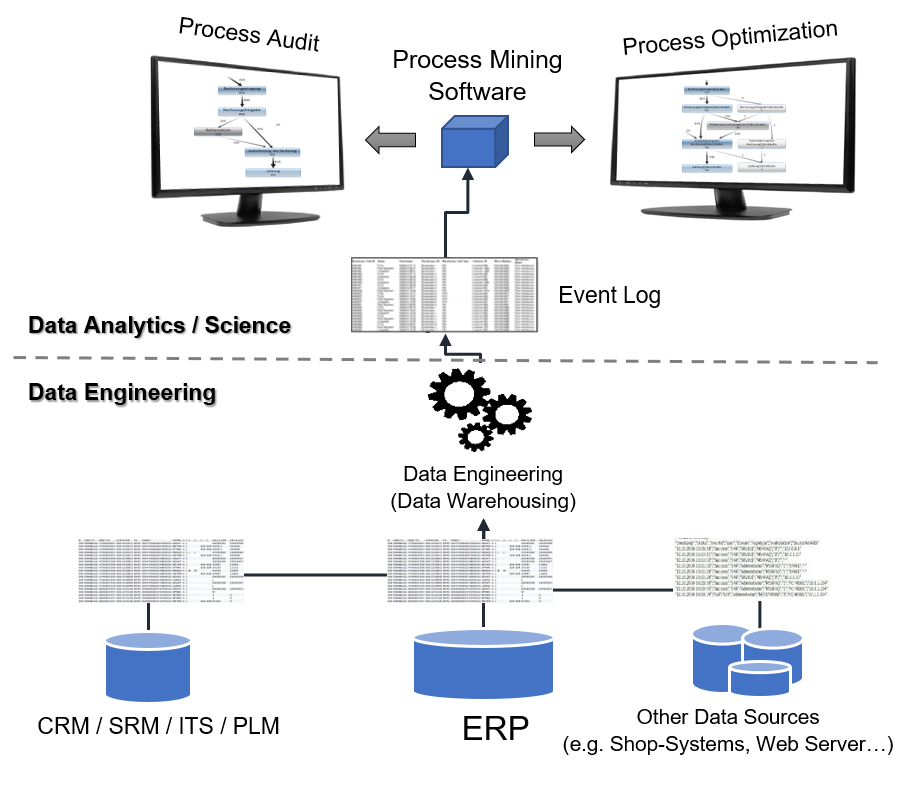
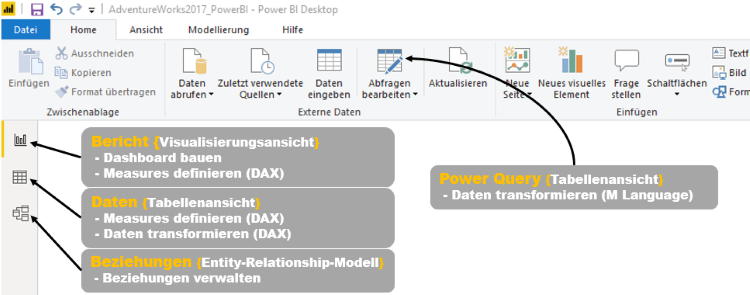
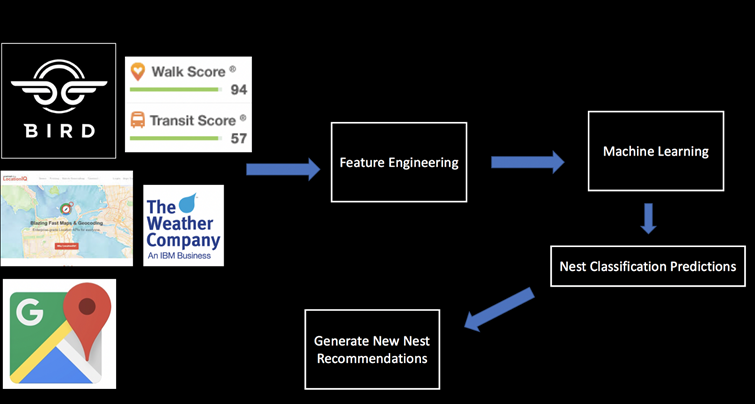
Abbildung 2 zeigt den typischen Workflow eines Process Mining Projektes. Oftmals dient das ERP-System als zentrale Datenquelle. Die herausgearbeiteten Event-Logs werden anschließend mittels Process Mining Tool visualisiert.
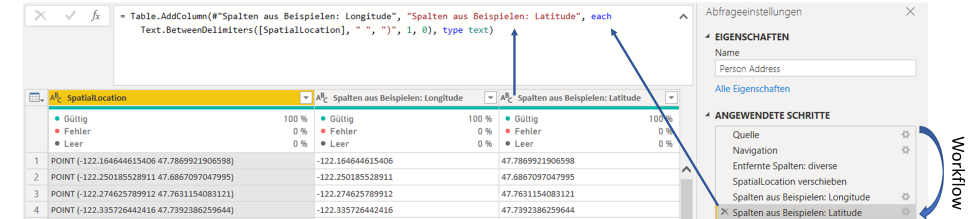
In jedem Fall liegt meistens das Gros der Arbeit auf die Bereitstellung und Vorbereitung der Daten und der Transformation dieser in sogenannte „Event-Logs“, die den Input für die Process Mining Tools darstellen. Deshalb arbeiten viele Anbieter von Process Mining Tools schon länger an Lösungen, um die mit der Datenvorbereitung verbundenen zeit -und arbeitsaufwendigen Schritte zu erleichtern. Während fast alle Tool-Anbieter vorgefertigte Protokolle für Standardprozesse anbieten, gehen manche noch weiter und bieten vollumfängliche Plattform Lösungen an, welche eine effiziente Integration der aufwendigen ETL-Prozesse versprechen. Der Funktionsumfang der Process Mining Tools geht daher mittlerweile deutlich über eine reine Darstellungsfunktion hinaus und deckt ggf. neue Trends sowie optimierte Einsteigerbarrieren mit ab.
Motivation dieser Artikelserie
Die Motivation diesen Artikel zu schreiben liegt nicht in der Erläuterung der Methode des Process Mining. Hierzu gibt es mittlerweile zahlreiche Informationsquellen. Eine besonders empfehlenswerte ist das Buch „Process Mining“ von Will van der Aalst, einem der Urväter des Process Mining. Die Motivation dieses Artikels liegt viel mehr in der Betrachtung der zahlreichen Process Mining Tools am Markt. Sehr oft erlebe ich als Data-Consultant, dass Process Mining Projekte im Vorfeld von der Frage nach dem „besten“ Tool dominiert werden. Diese Fragestellung ist in Ihrer Natur sicherlich immer individuell zu beantworten. Da individuelle Projekte auch einen individuellen Tool-Einsatz bedingen, beschäftige ich mich meist mit einem großen Spektrum von Process Mining Tools. Daher ist es mir in dieser Artikelserie ein Anliegen einen allgemeingültigen Überblick zu den üblichen Process Mining Tools zu erarbeiten. Dabei möchte ich mich nicht auf persönliche Erfahrungen stützen, sondern die Tools anhand von Testdaten einem praktischen Vergleich unterziehen, der für den Leser nachvollziehbar ist.
Um den Umfang der Artikelserie zu begrenzen, werden die verschiedenen Tools nur in Ihren Kernfunktionen angewendet und verglichen. Herausragende Funktionen oder Eigenschaften der jeweiligen Tools werden jedoch angemerkt und ggf. in anderen Artikeln vertieft. Das Ziel dieser Artikelserie soll sein, dem Leser einen ersten Einblick über die am Markt erhältlichen Tools zu geben. Daher spricht dieser Artikel insbesondere Einsteiger aber auch Fortgeschrittene im Process Mining an, welche einen Überblick über die Tools zu schätzen wissen und möglicherweise auch mal über den Tellerand hinweg schauen mögen.
Die Tools
Die Gruppe der zu betrachteten Tools besteht aus den folgenden namenhaften Anwendungen:

Die Auswahl der Tools orientiert sich an den „Market Guide for Process Mining 2019“ von Gartner. Aussortiert habe ich jene Tools, mit welchen ich bisher wenig bis gar keine Berührung hatte. Diese Auswahl an Tools verspricht meiner Meinung nach einen spannenden Einblick von verschiedene Process Mining Tools am Markt zu bekommen.
Die Anwendung in der Praxis
Um die Tools realistisch miteinander vergleichen zu können, werden alle Tools die gleichen Datengrundlage benutzen. Die Datenbasis wird folglich über die gesamte Artikelserie hinweg für die Darstellungen mit den Tools genutzt. Ich werde im nächsten Artikel explizit diese Datenbasis kurz erläutern.
Das Ziel der praktischen Untersuchung soll sein, die Beispieldaten in die verschiedenen Tools zu laden, um den enthaltenen Prozess zu visualisieren. Dabei möchte ich insbesondere darauf achten wie bedienbar und anpassungsfähig/flexibel die Tools mir erscheinen. An dieser Stelle möchte ich eindeutig darauf hinweisen, dass dieser Vergleich und seine Bewertung meine Meinung ist und keineswegs Anspruch auf Vollständigkeit beansprucht. Da der Markt in Bewegung ist, behalte ich mir ferner vor, diese Artikelserie regelmäßig anzupassen.
Die Kriterien
Neben der Bedienbarkeit und der Anpassungsfähigkeit der Tools möchte ich folgende zusätzliche Gesichtspunkte betrachten:
- Bedienbarkeit: Wie leicht gehen die Analysen von der Hand? Wie einfach ist der Einstieg?
- Anpassungsfähigkeit: Wie flexibel reagiert das Tool auf meine Daten und Analyse-Wünsche?
- Integrationsfähigkeit: Welche Schnittstellen bringt das Tool mit? Läuft es auch oder nur in der Cloud?
- Skalierbarkeit: Ist das Tool dazu in der Lage, auch große und heterogene Daten zu verarbeiten?
- Zukunftsfähigkeit: Wie steht es um Machine Learning, ETL-Modeller oder Task Mining?
- Preisgestaltung: Nach welchem Modell bestimmt sich der Preis?
Die Datengrundlage
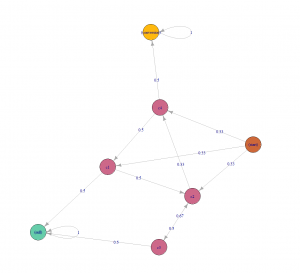
Die Datenbasis bildet ein Demo-Datensatz der von Celonis für die gesamte Artikelserie netter Weise zur Verfügung gestellt wurde. Dieser Datensatz bildet einen Versand Prozess vom Zeitpunkt des Kaufes bis zur Auslieferung an den Kunden ab. In der folgenden Abbildung ist der Soll Prozess abgebildet.
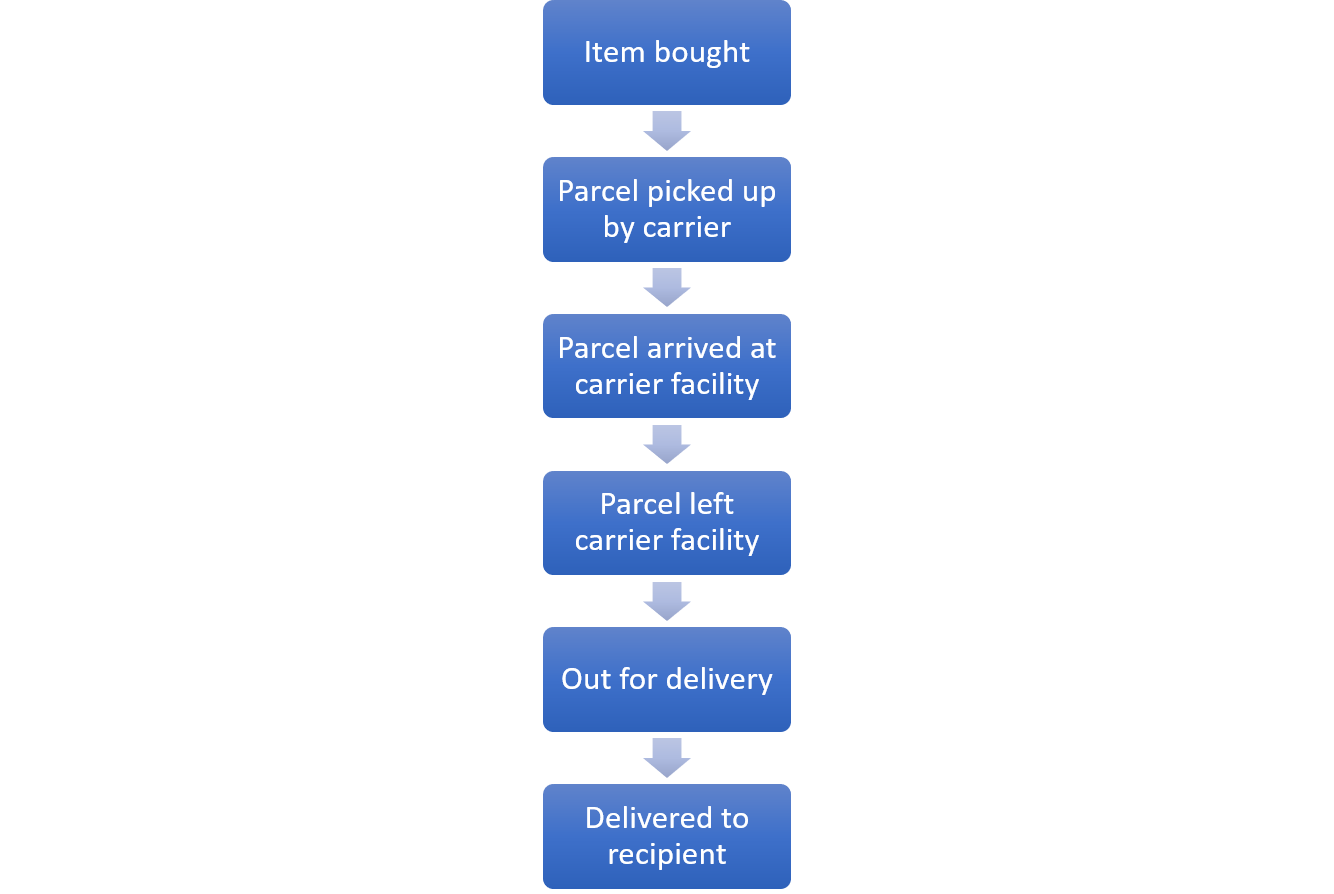
Abbildung 4 zeigt den gewünschten Versand Prozess der Datengrundlage von dem Kauf des Produktes bis zur Auslieferung.
Die Datengrundlage besteht aus einem 60 GB großen Event-Log, welcher lokal in einer Microsoft SQL Datenbank vorgehalten wird. Da diese Tabelle über 600 Mio. Events beinhaltet, wird die Datengrundlage für die Analyse der einzelnen Tools auf einen Ausschnitt von 60 Mio. Events begrenzt. Um die Performance der einzelnen Tools zu testen, wird jedoch auf die gesamte Datengrundlage zurückgegriffen. Der Ausschnitt der Event-Log Tabelle enthält 919 verschiedene Varianten und weisst somit eine ausreichende Komplexität auf, welche es mit den verschiednene Tools zu analysieren gilt.
Folgender Veröffentlichungsplan gilt für diese Artikelserie und wird mit jeder Veröffentlichung verlinkt:
- Celonis (erscheint demnächst)
- PAFnow (erscheint demnächst)
- MEHRWERK (erscheint demnächst)
- Lana Labs (erscheint demnächst)
- Signavio (erscheint demnächst)
- Process Gold (erscheint demnächst)
- Fluxicon Disco (erscheint demnächst)
- Aris Process Mining der Software AG (erscheint demnächst)
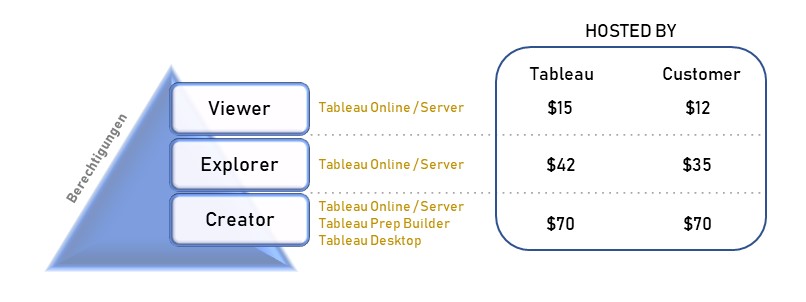 Der Creator ist befähigt, alle Funktionen von Tableau zu nutzen, sofern ein Unternehmen die angebotenen Add-ons hinzukauft. Die Lizenz Explorer ermöglicht es dem User, durch den Creator vordefinierte Datasets in Eigenregie zu analysieren und zu visualisieren. Demnach obliegt dem Creator, und somit einer kleinen Personengruppe, die Datenbereitstellung, womit eine Single Source of Truth garantiert werden soll. Der Viewer hat nur die Möglichkeit Berichte zu konsumieren, zu teilen und herunterzuladen. Wobei in Bezug auf Letzteres der Viewer limitiert ist, da dieser nicht die kompletten zugrundeliegenden Daten herunterladen kann. Lediglich eine Aggregation, auf welcher die Visualisierung beruht, kann heruntergeladen werden. Ein
Der Creator ist befähigt, alle Funktionen von Tableau zu nutzen, sofern ein Unternehmen die angebotenen Add-ons hinzukauft. Die Lizenz Explorer ermöglicht es dem User, durch den Creator vordefinierte Datasets in Eigenregie zu analysieren und zu visualisieren. Demnach obliegt dem Creator, und somit einer kleinen Personengruppe, die Datenbereitstellung, womit eine Single Source of Truth garantiert werden soll. Der Viewer hat nur die Möglichkeit Berichte zu konsumieren, zu teilen und herunterzuladen. Wobei in Bezug auf Letzteres der Viewer limitiert ist, da dieser nicht die kompletten zugrundeliegenden Daten herunterladen kann. Lediglich eine Aggregation, auf welcher die Visualisierung beruht, kann heruntergeladen werden. Ein