Interview – Die Bedeutung von Machine Learning für das Data Driven Business
Um das Optimum aus ihren Daten zu holen, müssen Unternehmen Data Analytics vorantreiben, um Entscheidungsprozesse für Innovation und Differenzierung stärker zu automatisieren. Die Data Science scheint hier der richtige Ansatz zu sein, ist aber ein neues und schnelllebiges Feld, das viele Sackgassen kennt. Cloudera Fast Forward Labs unterstützt Unternehmen dabei sich umzustrukturieren, Prozesse zu automatisieren und somit neue Innovationen zu schaffen.
 Alice Albrecht ist Research Engineer bei Cloudera Fast Forward Labs. Dort widmet sie sich der Weiterentwicklung von Machine Learning und Künstlicher Intelligenz. Die Ergebnisse ihrer Forschungen nutzt sie, um ihren Kunden konkrete Ratschläge und funktionierende Prototypen anzubieten. Bevor sie zu Fast Forward Labs kam, arbeitete sie in Finanz- und Technologieunternehmen als Data Science Expertin und Produkt Managerin. Alice Albrecht konzentriert sich nicht nur darauf, Maschinen “coole Dinge” beizubringen, sondern setzt sich auch als Mentorin für andere Wissenschaftler ein. Während ihrer Promotion der kognitiven Neurowissenschaften in Yale untersuchte Alice, wie Menschen sensorische Informationen aus ihrer Umwelt verarbeiten und zusammenfassen.
Alice Albrecht ist Research Engineer bei Cloudera Fast Forward Labs. Dort widmet sie sich der Weiterentwicklung von Machine Learning und Künstlicher Intelligenz. Die Ergebnisse ihrer Forschungen nutzt sie, um ihren Kunden konkrete Ratschläge und funktionierende Prototypen anzubieten. Bevor sie zu Fast Forward Labs kam, arbeitete sie in Finanz- und Technologieunternehmen als Data Science Expertin und Produkt Managerin. Alice Albrecht konzentriert sich nicht nur darauf, Maschinen “coole Dinge” beizubringen, sondern setzt sich auch als Mentorin für andere Wissenschaftler ein. Während ihrer Promotion der kognitiven Neurowissenschaften in Yale untersuchte Alice, wie Menschen sensorische Informationen aus ihrer Umwelt verarbeiten und zusammenfassen.
![]() Read this article in English:
Read this article in English:
“Interview – The Importance of Machine Learning for the Data Driven Business”
Data Science Blog: Frau Albrecht, Sie sind eine bekannte Keynote-Referentin für Data Science und Künstliche Intelligenz. Während Data Science bereits im Alltag vieler Unternehmen angekommen ist, scheint Deep Learning der neueste Trend zu sein. Ist Künstliche Intelligenz für Unternehmen schon normal oder ein überbewerteter Hype?
Ich würde sagen, nichts von beidem stimmt. Data Science ist inzwischen zwar weit verbreitet, aber die Unternehmen haben immer noch Schwierigkeiten, diese neue Disziplin in ihr bestehendes Geschäft zu integrieren. Ich denke nicht, dass Deep Learning mittlerweile Teil des Business as usual ist – und das sollte es auch nicht sein. Wie jedes andere Tool, braucht auch die Integration von Deep Learning Modellen in die Strukturen eines Unternehmens eine klar definierte Vorgehensweise. Alles andere führt ins Chaos.
Data Science Blog: Nur um sicherzugehen, worüber wir reden: Was sind die Unterschiede und Überschneidungen zwischen Data Analytics, Data Science, Machine Learning, Deep Learning und Künstlicher Intelligenz?
Hier bei Cloudera Fast Forward Labs verstehen wir unter Data Analytics das Sammeln und Addieren von Daten – meist für schnelle Diagramme und Berichte. Data Science hingegen löst Geschäftsprobleme, indem sie sie analysiert, Prozesse mit den gesammelten Daten abgleicht und anschließend entsprechende Vorgänge prognostiziert. Beim Machine Learning geht es darum, Probleme mit neuartigen Feedbackschleifen zu lösen, die sich mit der Anzahl der zur Verfügung stehenden Daten noch detaillierter bearbeiten lassen. Deep Learning ist eine besondere Form des Machine Learnings und ist selbst kein eigenständiges Konzept oder Tool. Künstliche Intelligenz zapft etwas Komplizierteres an, als das, was wir heute sehen. Hier geht es um weit mehr als nur darum, Maschinen darauf zu trainieren, immer wieder dasselbe zu tun oder begrenzte Probleme zu lösen.
Data Science Blog: Und wie können wir hier den Kontext zu Big Data herstellen?
Theoretisch gesehen gibt es Data Science ja bereits seit Jahrzehnten. Die Bausteine für modernes Machine Learning, Deep Learning und Künstliche Intelligenz basieren auf mathematischen Theoremen, die bis in die 40er und 50er Jahre zurückreichen. Die Herausforderung bestand damals darin, dass Rechenleistung und Datenspeicherkapazität einfach zu teuer für die zu implementierenden Ansätze waren. Heute ist das anders. Nicht nur die Kosten für die Datenspeicherung sind erheblich gesunken, auch Open-Source-Technologien wie etwa Apache Hadoop haben es möglich gemacht, jedes Datenvolumen zu geringen Kosten zu speichern. Rechenleistung, Cloud-Lösungen und auch hoch spezialisierte Chip-Architekturen, sind jetzt auch auf Anfrage für einen bestimmten Zeitraum verfügbar. Die geringeren Kosten für Datenspeicherung und Rechenleistung sowie eine wachsende Liste von Tools und Ressourcen, die über die Open-Source-Community verfügbar sind, ermöglichen es Unternehmen jeder Größe, von sämtlichen Daten zu profitieren.
Data Science Blog: Was sind die Herausforderungen beim Einstieg in Data Science?
Ich sehe zwei große Herausforderungen: Eine davon ist die Sicherstellung der organisatorischen Ausrichtung auf Ergebnisse, die die Data Scientists liefern werden (und das Timing für diese Projekte). Die zweite Hürde besteht darin, sicherzustellen, dass sie über die richtigen Daten verfügen, bevor sie mit dem Einstellen von Data Science Experten beginnen. Das kann “tricky” sein, wenn man im Unternehmen nicht bereits über Know-how in diesem Segment verfügt. Daher ist es manchmal besser, im ersten Schritt einen Data Engineer oder Data Strategist einzustellen, bevor man mit dem Aufbau eines Data Science Team beginnt.
Data Science Blog: Es gibt viele Diskussionen darüber, wie man ein datengesteuertes Unternehmen aufbauen kann. Geht es bei Data Science nur darum, am Ende das Kundenverhalten besser zu verstehen?
Nein “Data Driven” bedeutet nicht nur, die Kunden besser zu verstehen – obwohl das eine Möglichkeit ist, wie Data Science einem Unternehmen helfen kann. Abgesehen vom Aufbau einer Organisation, die sich auf Daten und Analysen stützt, um Entscheidungen über das Kundenverhalten oder andere Aspekte zu treffen, bedeutet es, dass Daten das Unternehmen und seine Produkte voranbringen.
Data Science Blog: Die Zahl der Technologien, Tools und Frameworks nimmt zu, was zu mehr Komplexität führt. Müssen Unternehmen immer auf dem Laufenden bleiben oder könnte es ebenso hilfreich sein, zu warten und Pioniere zu imitieren?
Obwohl es generell für Unternehmen nicht ratsam ist, pauschal jede neue Entwicklung zu übernehmen, ist es wichtig, dass sie mit den neuen Rahmenbedingungen Schritt halten. Wenn ein Unternehmen wartet, um zu sehen, was andere tun, und deshalb nicht in neue Entwicklungen investiert, haben sie den Anschluss meist schon verpasst.
Data Science Blog: Global Player verfügen meist über ein großes Budget für Forschung und den Aufbau von Data Labs. Mittelständische Unternehmen stehen immer unter dem Druck, den Break-Even schnell zu erreichen. Wie können wir die Wertschöpfung von Data Science beschleunigen?
Ein Team zu haben, das sich auf ein bestimmtes Set von Projekten konzentriert, die gut durchdacht und auf das Geschäft ausgerichtet sind, macht den Unterschied aus. Data Science und Machine Learning müssen nicht auf Forschung und Innovation verzichten, um Werte zu schaffen. Der größte Unterschied besteht darin, dass sich kleinere Teams stärker bewusst sein müssen, wie sich ihre Projektwahl in neue Rahmenbedingungen und ihre besonderen akuten und kurzfristigen Geschäftsanforderungen einfügt.
Data Science Blog: Wie hilft Cloudera Fast Forward Labs anderen Unternehmen, den Einstieg in Machine Learning zu beschleunigen?
Wir beraten Unternehmen, basierend auf ihren speziellen Bedürfnissen, über die neuesten Trends im Bereich Machine Learning und Data Science. Und wir zeigen ihnen, wie sie ihre Datenteams aufbauen und strukturieren können, um genau die Fähigkeiten zu entwickeln, die sie benötigen, um ihre Ziele zu erreichen.
Data Science Blog: Zum Schluss noch eine Frage an unsere jüngeren Leser, die eine Karriere als Datenexperte anstreben: Was macht einen guten Data Scientist aus? Arbeiten sie lieber mit introvertierten Coding-Nerds oder den Data-loving Business-Experten?
Ein guter Data Scientist sollte sehr neugierig sein und eine Liebe für die Art und Weise haben, wie Daten zu neuen Entdeckungen und Innovationen führen und die nächste Generation von Produkten antreiben können. Menschen, die im Data Science Umfeld erfolgreich sind, kommen nicht nur aus der IT. Sie können aus allen möglichen Bereichen kommen und über die unterschiedlichsten Backgrounds verfügen.










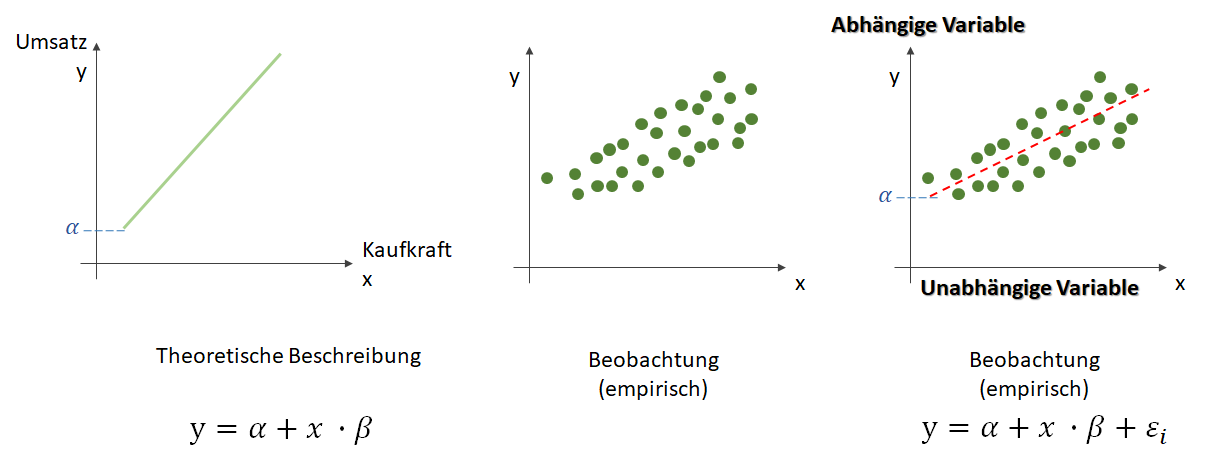
 , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  der Zielwert (abhängige Variable) und
der Zielwert (abhängige Variable) und  der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable
der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable  (Alpha) ist der
(Alpha) ist der  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung. ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.svg "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.svg "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.svg "Rendered by QuickLaTeX.com")
 .
.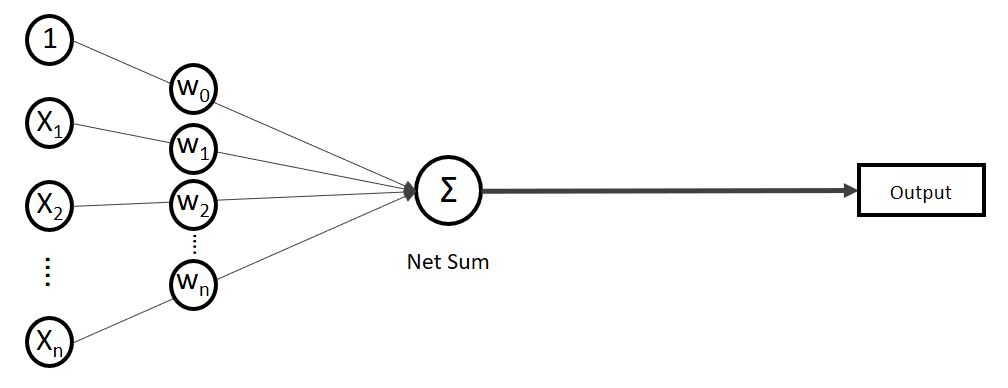
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
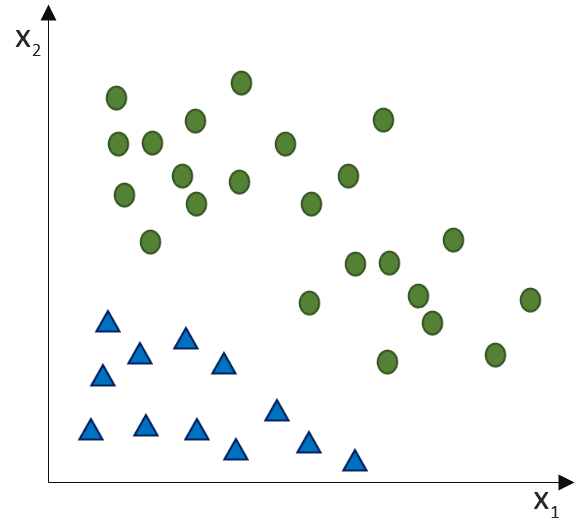
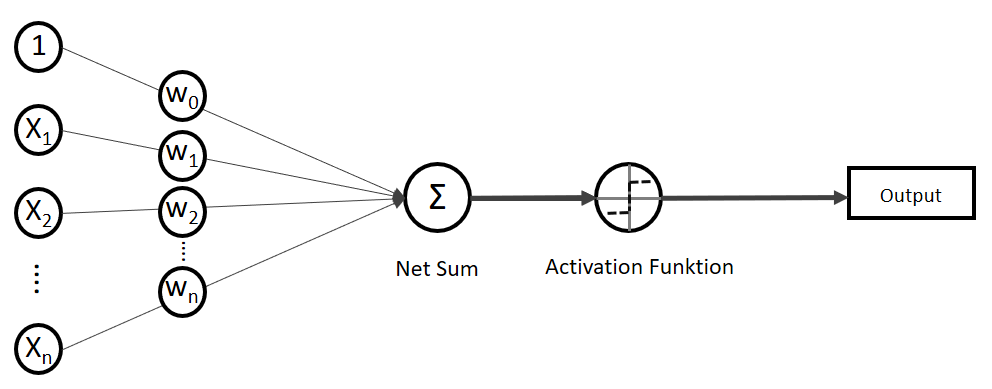
 (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 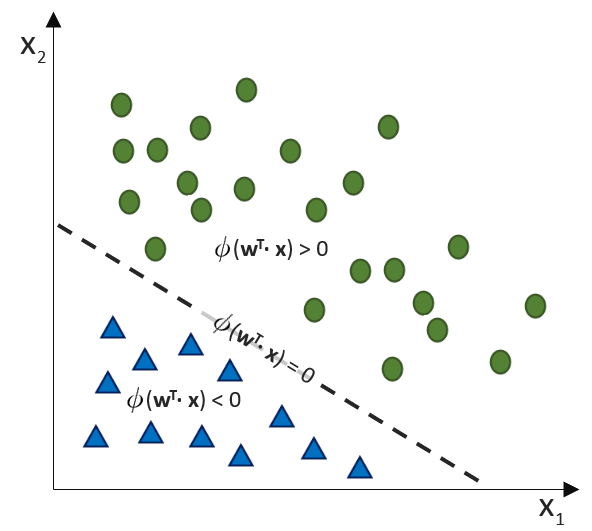
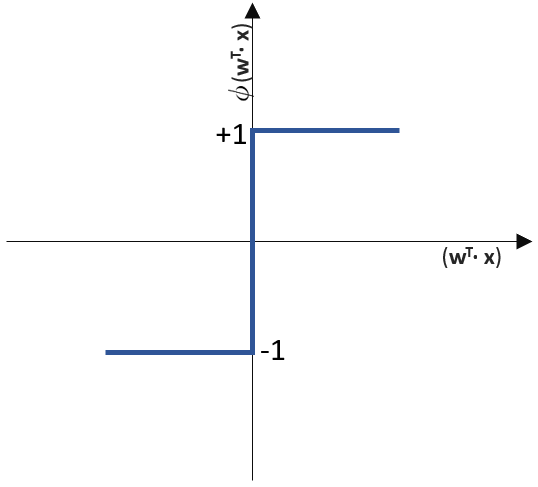
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.svg "Rendered by QuickLaTeX.com")
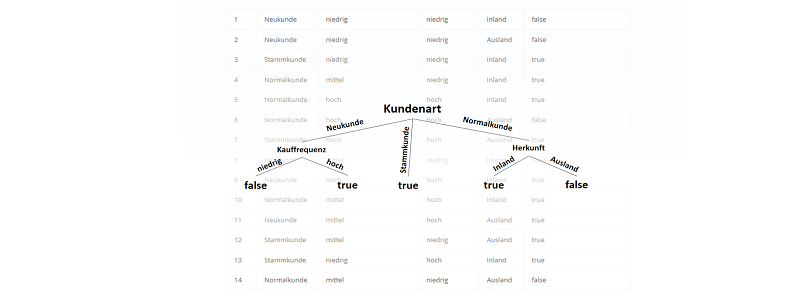
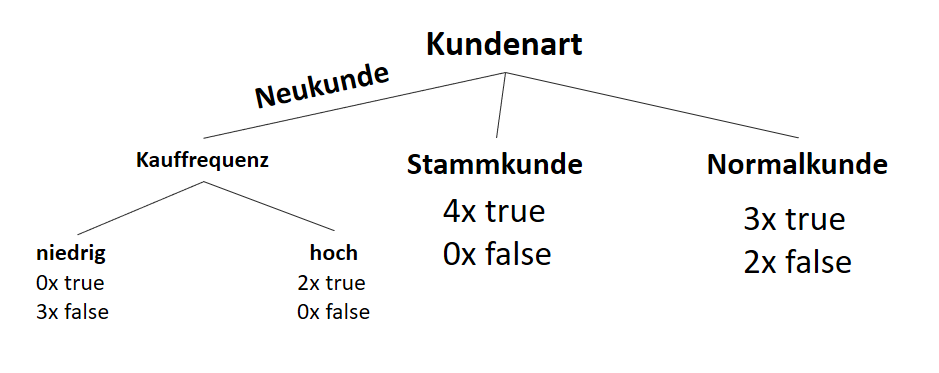
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

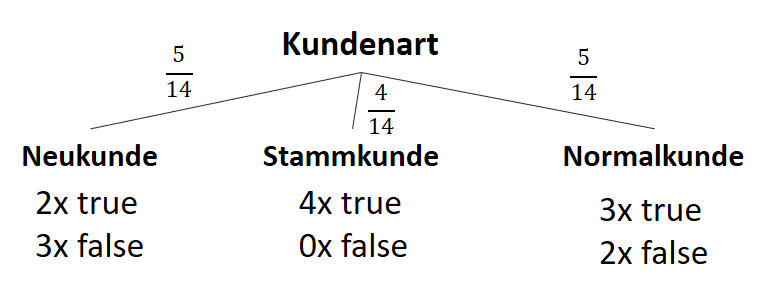



![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.svg "Rendered by QuickLaTeX.com")
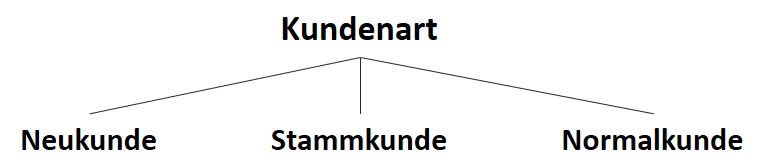
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.svg "Rendered by QuickLaTeX.com")
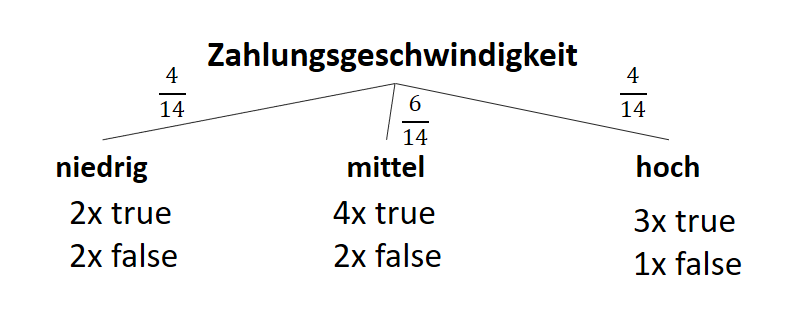



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.svg "Rendered by QuickLaTeX.com")
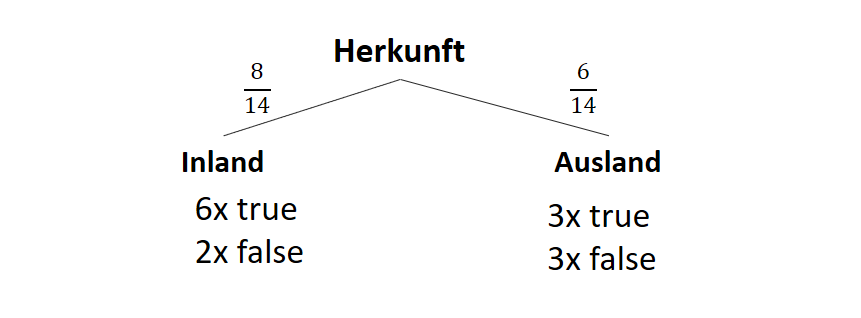


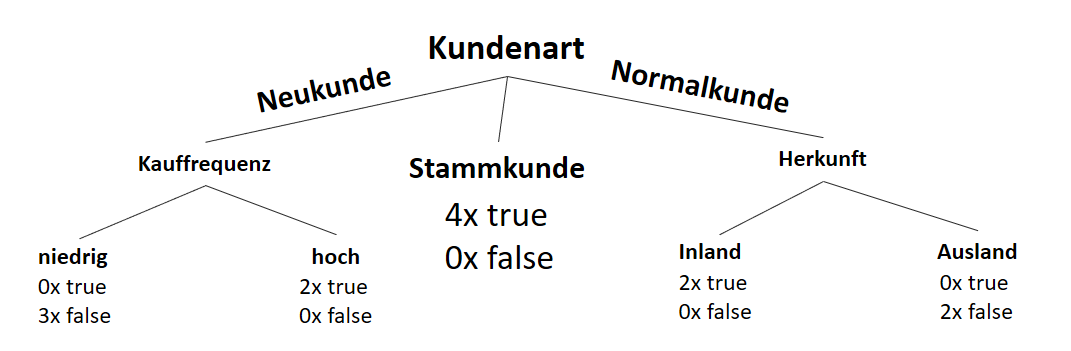
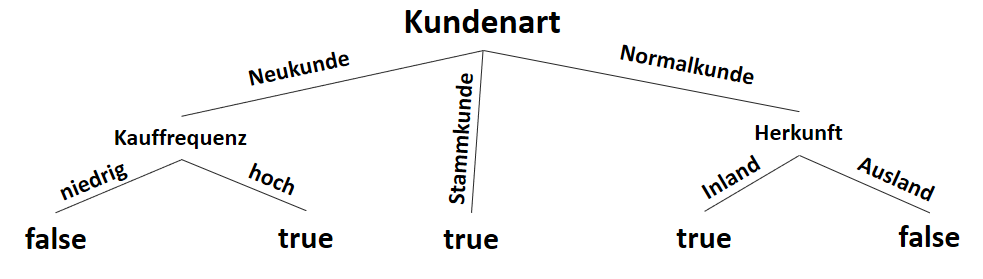
![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.svg "Rendered by QuickLaTeX.com")
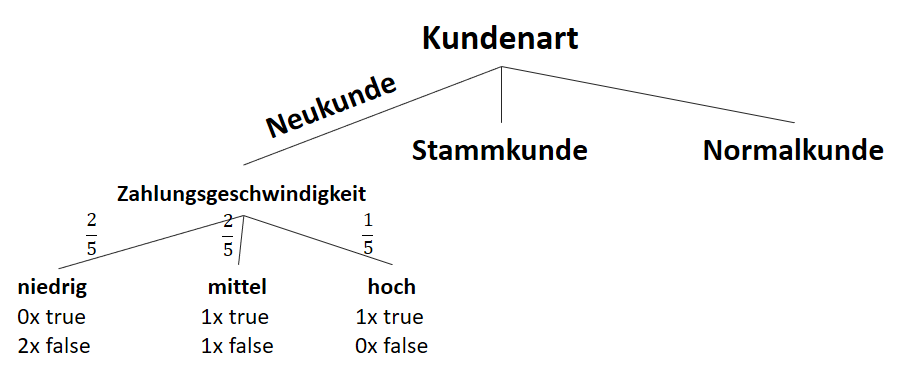



![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.svg "Rendered by QuickLaTeX.com")
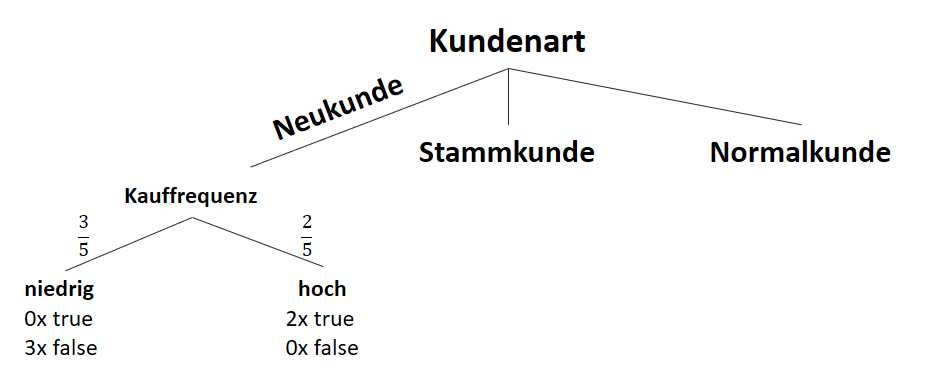
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.svg "Rendered by QuickLaTeX.com")