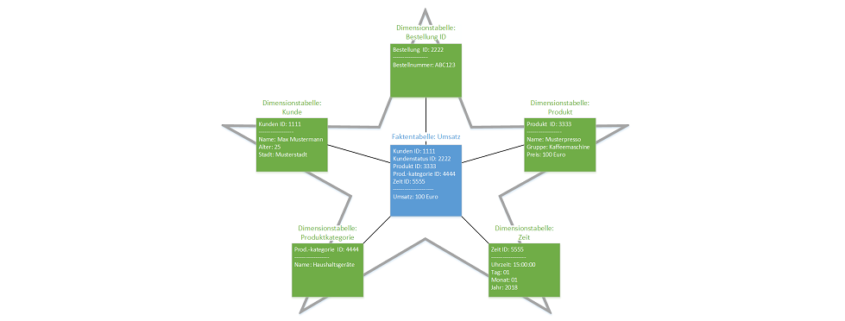
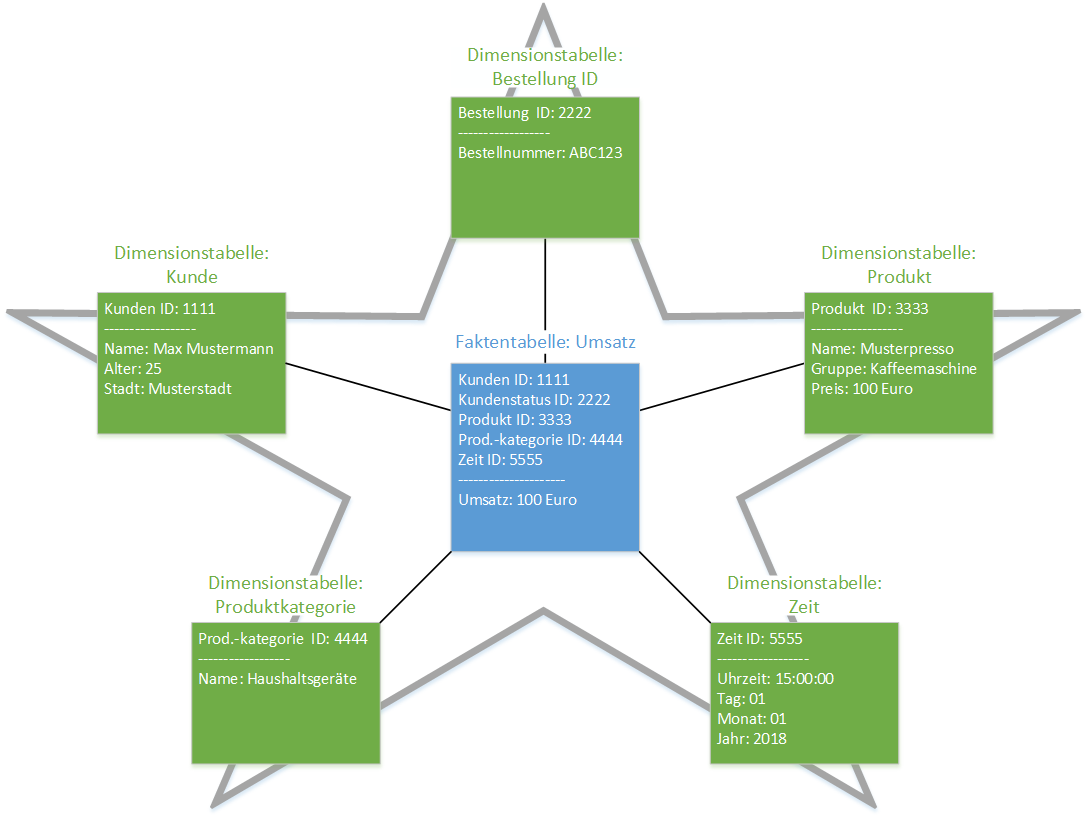
Wird Artificial Intelligence oder Cognitive Computing oder beides zusammen der Standard, den alle haben müssen?
 Prof. Dr. Carsten Felden ist Vorsitzender des Vorstandes des TDWI e.V., der größten Community für Analytics und Buisness Intelligence.. Er ist selbst Experte und Consultant für Business Intelligence und für diesen Fachbereich Lehrstuhlinhaber an der TU Bergakademie Freiberg.
Prof. Dr. Carsten Felden ist Vorsitzender des Vorstandes des TDWI e.V., der größten Community für Analytics und Buisness Intelligence.. Er ist selbst Experte und Consultant für Business Intelligence und für diesen Fachbereich Lehrstuhlinhaber an der TU Bergakademie Freiberg.
Data Science Blog: Herr Prof. Felden, welcher Weg hat Sie bis an die Spitze des erfolgreichsten deutschen Verbandes für Analytics und Business Intelligence geführt?
Ich möchte die Beantwortung gerne umdrehen: Der TDWI ist ein Verein, in dem sich jeder als Mitglied engagieren darf und soll. Und da die Themen mir Freude bereiten und immer wieder neue Facetten zeigen, bin ich auch mit Begeisterung dabei und trage dies gerne in den Verein. Zu diesen Themen bin ich über mein Studium der Wirtschaftswissenschaft gelangt, in dem ich Wirtschaftsinformatik und Logistik vertiefte. Bei Professor Chamoni bot sich mir 2002 die Gelegenheit zur Promotion, in der ich mittels Text Mining ein Analysesystem in Python entwickelte, um Energiemarktentwicklungen zu erklären. Schon während dieser Zeit ergaben sich aber immer wieder Fragestellungen, welche die Entscheidungsfindung an sich betrafen. Dies interessierte mich in den vielen Facetten, so dass ich eine Habilitationsschrift anschloss, um den Entscheidungsprozess näher von der theoretischen Seite zu beleuchten. Dabei nahm ich Datenanalyseprozesse als Grundlage, um deren Wirkung auf menschliche Entscheidungsträger zu betrachten. Mit der Übernahme meiner Professur in 2006 baute ich einen kompetenzcenterorientierten Lehrstuhl auf, der sich zum Ziel setzte zu untersuchen, wie man realistisch mit Daten arbeiten kann, was man mit Daten tun kann. Dies in unterschiedlichen Welten: dem internationalen High-Tech-Konzern, dem Mittelständler als Hidden Champion oder dem kleineren Unternehmen. Insbesondere die Verbindung von Theorie und Praxis hat immer wieder die universitäre Lehre befruchtet und diese wollte ich auch in den Verein tragen. Im Rahmen der Veranstaltungen des TDWI habe ich immer viele neue Dinge oder realistische Einschätzungen aktuell diskutierter Dinge erhalten und wollte letztlich diese auch aus meinen Projekterfahrungen in die dortigen Diskussionen in unterschiedlichen Veranstaltungen zurückbringen. Das ich nun Vorsitzender dieses Vereins sein darf ist aber den Mitgliedern zu verdanken, die Vertrauen in mich setzten, den Weg des Vereins weiter voran zu treiben und meinen Vorstandskollegen, ohne deren Arbeit und Unterstützung meine Tätigkeit nichts wert wäre. Es ist der Verein als Ganzes, der den Mehrwert bietet und nicht einzelne Personen.
Data Science Blog: Wie weit ist die Industrie mittlerweile beim Einsatz von AI, also künstlicher Intelligenz?
Eine eindeutige Antwort ist hier gar nicht möglich. Allein schon die Deutung des Begriffs in der Praxis, macht es manchmal schwer, zwischen echten und unechten AI-Projekten zu unterscheiden. Letztlich kann man aber abgrenzend sagen, dass AI die automatisierte Entscheidung ermöglicht und nicht bei der Entscheidungsunterstützung für einen menschlichen Aufgabenträger endet. Egal, ob es nun ein echte oder ein unechtes AI-Projekt ist, es gilt, dass Daten entsprechend zu identifizieren, zu extrahieren und ggf. zu transformieren und final bereitzustellen sind. Nun soll aber nicht der Manager mit seinem fachlichem Know How (=Bauchgefühl) diese Informationen zur Entscheidung nutzen, sondern die Maschine übernimmt auch diesen Part (ohne Bauchgefühl) basierend auf Algorithmen. Man darf den Begriff der Entscheidung nicht immer mit einer besonderen Tragweite verbinden, da schon das einfache Signal einer Maschine: „Ich bin frei, ich habe Zeit, ich kann das jetzt tun!“ ist eine Entscheidung.
Um auch noch kurz auf die Abgrenzung zu den unechten Projekten einzugehen: hier erlebe ich immer wieder, dass AI mit künstlichen neuronalen Netzen gleichgesetzt wird. Natürlich kann man solche Netze hier nutzen, aber letztlich geht es nur darum, den Entscheidungsprozess in unterschiedlichen Situationen zu automatisieren. Zu diesem Zweck muss man prüfen, wo das sinnhaft möglich ist, da es nicht das Ziel sein kann, alles ohne Wenn und Aber zu automatisieren. In technisch-affinen Unternehmen sehen wir schon einige Umsetzungen, die über den Pilot-Status hinaus sind. Beispielhaft zu nennen sind da vollautomatisierte Fertigungen, insofern der Herstellungsprozess reihenfolgeunabhängig ist oder aber Controllingprozesse. Im Kern sind es aktuell noch Tätigkeiten, die keinen ausgeprägten kreativen Kern beinhalten, aber ein hohes Maß an Kommunikation zwischen den Beteiligten Systemelementen erfordern. In Summe gibt es ein breites Interesse und schon viele Orientierungsbeispiele, die dazu führen werden, dass diese Projekte intensiver zunehmen werden.
Data Science Blog: Wie grenzen Sie eigentlich Artificial Intelligence und Cognitive Computing voneinander ab? Wo liegen die Unterschiede?
Letztlich kann ich hier zum vorherigen ergänzen: beim Cognitive Computing handelt es sich um die Fortführung der wissensbasierten Systeme beziehungsweise der Expertensysteme. Der enorme und damit auch beeindruckende Unterschied zu den Vorläufern ist die Fähigkeit des Lernens im Sinne einer inhaltlichen Weiterentwicklung der vorhandenen Wissensbasis, die nun wesentlich ausgeprägter ist und auch automatisiert in entsprechenden Wissensdomänen stattfinden kann. AI kann einerseits zum Lernen des Systems beitragen, andererseits das gelernte für die automatisierte Entscheidung anwenden. Beide Ansätze nutzen und befruchten sich also gegenseitig.
Data Science Blog: Welche Trends im Bereich Machine Learning bzw. Deep Learning werden Ihrer Meinung nach in den Jahren 2018 und 2019 von Bedeutung werden?
Da möchte ich direkt zu unserer diesjährigen Konferenz in München herüber schwenken. Traditionell finden wir dort die Trends der nächsten Jahre schon in Vorträgen und Diskussionen.
Insgesamt beobachten wir eine starke Entwicklung hin zur Analyse unstrukturierter Daten. Machine Learning wird zunehmend intensiv in textuellen Analysen genutzt, um zum Beispiel eine E-Mail-Kategorisierung beziehungsweise Reaktion auf eine E-Mail zu automatisieren. Darüber hinaus ist die Verarbeitung von Bildern mit Ansätzen des Deep Learning ein zunehmender Trend. Dies in Szenarios wie die Fehlererkennung in der Herstellung oder dem Erkennen des Anwenders und dahingehend automatischen Anpassung seiner vorliegenden Systemlösung mit den passenden Inhalten. Sie sehen also, dass alle Facetten der algorithmischen Datenanalyse bedeutend werden. Dabei stellen wir aber auch fest, dass der klassischen Hausaufgaben, wie Datenintegration, Datenqualitätssicherung, Datenbereitstellung etc. nicht vom Tisch sind, sondern auch immer wieder neu diskutiert werden. Hier kommt aktuell hinzu, Verfahren der künstlichen Intelligenz zu nutzen, um eine dynamische Schemaerzeugung in Zeiten von Data Lakes automatisiert auszuführen, um den Anwendern für die jeweilige Entscheidungssituation Daten bedarfs- und verarbeitungsgerecht zur Verfügung zu stellen. Wir sehen also, dass die Übernahme von Tätigkeiten durch maschinellen Aufgabenträger der treibende Faktor ist, was dann mittels Machine Learning bzw. Deep Learning umsetzbar ist.
Data Science Blog: In wie weit wird der Begriff „Business Intelligence“ Ihrer Meinung nach zukünftig erhalten bleiben? Wie nahtlos ließen sich die neuen Möglichkeiten mit künstlicher Intelligenz in BI-Systeme integrieren?
Nun ja, aktuell werden wir mit Schlagworten überflutet, die darüber hinaus noch oftmals mit unterschiedlichen Verständnissen belegt sind, so dass es mehr Verwirrung als Erkenntnis gibt. Wissenschaftlich betrachtet ist Business Intelligence ein allumfassender Begriff, da er lediglich benennt, dass Daten zu sammeln und zu Entscheidungszwecken aufzubereiten sind. Dies subsummiert also auch AI.
In der Praxis ist BI aber eher das alte, starre Berichtswesen und passt dann so gar nicht zu den dynamischen Analyticsansätzen. Hier muss man aber sagen, dass Self Service Ansätze und die zunehmende Flexibilisierung der Architekturen dabei unterstützt, beide Welten zusammenzubringen. Aktuell ist man noch auf dem Niveau, über Schnittstellen bewusst Code auszutauschen. Beispielsweise lässt sich R-Code in vielen BI-Werkzeugen ausführen. Letztlich erleben wir aber alle, dass Geräte immer einfacher zu steuern sind und dadurch Welten auch zusammenfließen und das wird auch hier geschehen, weil es die Anwender einfach so gewohnt sind.
Data Science Blog: Manchmal hört man, dass Data Scientists gerade an ihrer eigenen Arbeitslosigkeit arbeiten, da zukünftige Verfahren des maschinellen Lernens Data Mining selbstständig durchführen können. Werden Tools Data Scientists bald ersetzen?
Die Wirtschaftsinformatik hat das Postulat der sinnhaften Vollautomation. Daher sehe ich es auch hier so, dass man die Punkte beziehungsweise Stellen im Prozess identifizieren muss, wo die Anwendung der Data Science Sinn macht. Darüber hinaus sehe ich den Data Scientist eigentlich nicht als eine Person, sondern als ein Konglomerat an Fähigkeiten, oftmals verteilt über mehrere Abteilungen und damit auch mehrere Personen, die zusammenarbeiten müssen. Die geforderten Fähigkeiten werden sich sicherlich wandeln, jedoch wird Kommunikationsfähigkeit immer der Schlüssel sein und Tools werden dahingehend das Data Science Team nicht ersetzen, sondern immer Mittel zum Zweck im Rahmen der sinnhaften Vollautomation sein.
Data Science Blog: Für alle Studenten, die demnächst ihren Bachelor, beispielsweise in Informatik, Mathematik oder Wirtschaftswissenschaften, abgeschlossen haben, was würden sie diesen jungen Damen und Herren raten, wie sie gute Data Scientists werden können?
Kommunizieren können und neugierig sein. Sie werden alle viel im Rahmen ihrer Ausbildung an fundamentalen Fähigkeiten gelernt haben, aber lassen sie sich auf die Partner im Projekt ein, interessieren sie sich für all das, was auf der fachlichen Ebene geschieht und wie der technische Fortschritt aussieht. Ich kann immer nur wiederholen, dass offene Kommunikation eine wichtige Fähigkeit in Projekten ist, die nicht hoch genug bewertet werden kann. Die TDWI-Konferenz oder all die anderen Formate des Vereins bieten die Möglichkeit, Wissen aufzunehmen, auszutauschen und sich selber mit anderen zu vernetzen. Ich denke wirklich, dass gute Data Scientist derartiges nutzen, um die eigenen Themen bestmöglich angehen zu können, denn das ist der Schlüssel zum Erfolg!
Prof. Felden wird am 25. Juni die TDWI Konferenz in München eröffnen, die unter dem Slogan „Business Intelligence meets Artificial Intelligence“ die neuen Möglichkeiten unter Einsatz künstlicher Intelligenz in den Fokus stellen wird.