Entscheidungsbaum-Algorithmus ID3
Dieser Artikel ist Teil 2 von 4 der Artikelserie Maschinelles Lernen mit Entscheidungsbaumverfahren.
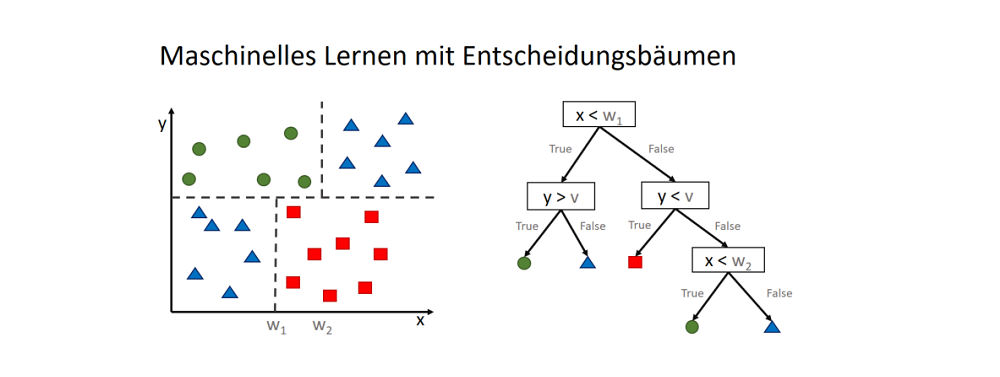
Entscheidungsbäume sind den Ingenieuren bestens bekannt, um Produkte hierarchisch zu zerlegen und um Verfahrensanweisungen zu erstellen. Die Data Scientists möchten ebenfalls Verfahrensanweisungen erstellen, jedoch automatisiert aus den Daten heraus. Auf diese Weise angewendet, sind Entscheidungsbäume eine Form des maschinellen Lernens: Die Maschine soll selbst einen Weg finden, um ein Objekt einer Klasse zuzuordnen.
Der ID3-Algorithmus
Den ID3-Algorithmus zu verstehen lohnt sich, denn er ist die Grundlage für viele weitere, auf ihn aufbauende Algorithmen. Er ist mit seiner iterativen und rekursiven Vorgehensweise auch recht leicht zu verstehen, er darf nur wiederum nicht in seiner Wirkung unterschätzt werden. Die Vorgehensweise kann in drei wesentlichen Schritten zerlegt werden, wobei der erste Schritt die eigentliche Wirkung (mit allen Vor- und Nachteilen) entfaltet:
- Schritt: Auswählen des Attributes mit dem höchsten Informationsgewinn
Betrachte alle Attribute (Merkmale) des Datensatzes und bestimme, welches Attribut die Daten am besten klassifiziert. - Schritt: Anlegen eines Knotenpunktes mit dem Attribut
Sollten die Ergebnisse unter diesem Knoten eindeutig sein (1 unique value), speichere es in diesem Knotenpunkt und springe zurück. - Schritt: Rekursive Fortführung dieses Prozesses
Andernfalls zerlege die Daten jedem Attribut entsprechend in n Untermengens (subsets), und wiederhole diese Schritte für jede der Teilmengen.
Der Informationsgewinn (Information Gain) – und wie man ihn berechnet
Der Informationsgewinn eines Attributes ( ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie: Entropie, ein Maß für die Unreinheit in Daten) des gesamten Datensatzes (
) (siehe Teil 1 der Artikelserie: Entropie, ein Maß für die Unreinheit in Daten) des gesamten Datensatzes ( ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

Wie die Berechnung des Informationsgewinnes funktioniert, wird Teil 3 dieser Artikel-Reihe (erscheint in Kürze) zeigen.
Die Vorzüge des ID3-Algorithmus – und die Nachteile
Der Algorithmus ist die Grundlage für viele weitere Algorithmen. In seiner Einfachheit bringt er gewisse Vorteile – die ihn vermutlich zum verbreitesten Entscheidungsbaum-Algorithmus machen – mit sich, aber hat auch eine Reihe von Nachteilen, die bedacht werden sollten.
| Vorteile | Nachteile |
|
|
Overfitting (Überanpassung) beachten und vermeiden
Aus Daten heraus generierte Entscheidungsbäume neigen zur Überanpassung. Das bedeutet, dass sich die Bäume den Trainingsdaten soweit anpassen können, dass sie auf diese perfekt passen, jedoch keine oder nur noch einen unzureichende generalisierende Beschreibung mehr haben. Neue Daten, die eine höhere Vielfältigkeit als die Trainingsdaten haben können, werden dann nicht mehr unter einer angemessenen Fehlerquote korrekt klassifiziert.
Vorsicht vor Key-Spalten!
Einige Attribute erzwingen eine Überanpassung regelrecht: Wenn beispielsweise ein Attribut wie „Kunden-ID“ (eindeutige Nummer pro Kunde) einbezogen wird, haben wir – bezogen auf das Klassifikationsergebnis – für jeden einzelnen Wert in dem Attribut eine Entropie von 0 zu erwarten, denn jeder ID beschreibt einen eindeutigen Fall (Kunde, Kundengruppe etc.). Daraus folgt, dass der Informationsgewinn für dieses Attribut maximal wird. Hier würde der Baum eine enorme Breite erhalten, die nicht hilfreich wäre, denn jeder Wert (IDs) bekäme einen einzelnen Ast im Baum, der zu einem eindeutigen Ergebnis führt. Auf neue Daten (neue Kundennummern) ist der Baum nicht anwendbar, denn er stellt keine generalisierende Beschreibung mehr dar, sondern ist nur noch ein Abbild der Trainingsdaten.
Prunning – Den Baum nachträglich kürzen
Besonders große Bäume sind keine guten Bäume und ein Zeichen für Überanpassung. Eine Möglichkeit zur Verkleinerung ist das erneute Durchrechnen der Informationsgewinne und das kürzen von Verzweigungen (Verallgemeinerung), sollte der Informationsgewinn zu gering sein. Oftmals wird hierfür nicht die Entropie oder der Gini-Koeffizient, sondern der Klassifikationsfehler als Maß für die Unreinheit verwendet.
Random Forests als Overfitting-Allheilmittel
Bei Random Forests (eine Form des Ensemble Learning) handelt es sich um eine Gemeinschaftsentscheidung der Klassenzugehörigkeit über mehrere Entscheidungsbäume. Diese Art des “demokratischen” Machine Learnings wird auch Ensemble Learning genannt. Werden mehrere Entscheidungsbäume unterschiedlicher Strukturierung zur gemeinsamen Klassifikation verwendet, wird die Wirkung des Overfittings einzelner Bäume in der Regel reduziert.
Benjamin Aunkofer
Benjamin Aunkofer ist Lead Data Scientist bei DATANOMIQ und Hochschul-Dozent für Data Science und Data Strategy. Darüber hinaus arbeitet er als Interim Head of Business Intelligence und gibt Seminare/Workshops zu den Themen BI, Data Science und Machine Learning für Unternehmen.








Leave a Reply
Want to join the discussion?Feel free to contribute!