Maschinelles Lernen mit Entscheidungsbaumverfahren – Artikelserie
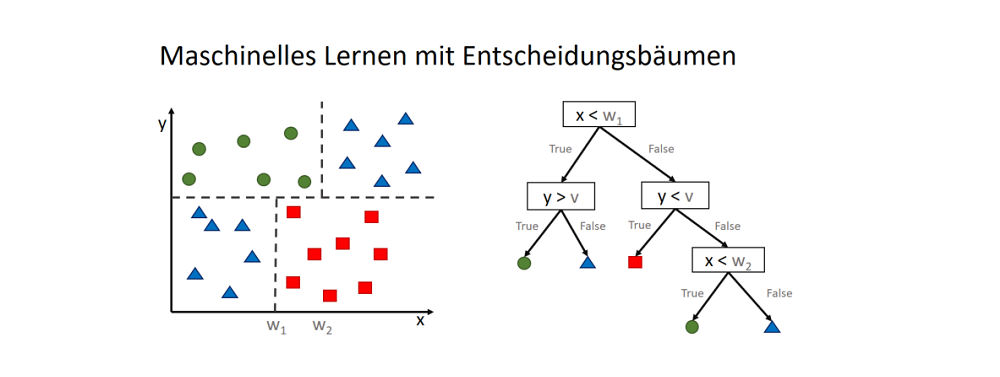
Das Entscheidungsbaumverfahren (Decision Tree) ist eine verbreitete Möglichkeit der Regression oder Klassifikation über einen vielfältigen Datensatz. Das Verfahren wird beispielsweise dazu verwendet, um die Kreditwürdigkeit von Bankkunden zu klassifizieren oder auch, um eine Funktion zur Vorhersage einer Kaufkraft zu bilden.
Sicherlich hat beinahe jeder Software-Entwickler bereits einen Entscheidungsbaum (meistens binäre Baumstrukturen) programmiert und auch Maschinenbauingenieure benutzen Entscheidungsbäume, um Konstruktionsstrukturen darzustellen. Im Data Science haben Entscheidungsbäume allerdings eine etwas andere Bedeutung, denn ein Data Scientist befasst sich weniger mit dem manuellen Erstellen von solchen Baumstrukturen, sondern viel mehr mit Algorithmen, die ausreichend gute (manchmal: best mögliche) Baumstrukturen automatisch aus eine Menge mehr oder weniger bekannter Daten heraus generieren, die dann für eine automatische Klassifikation bzw. Regression dienen können.
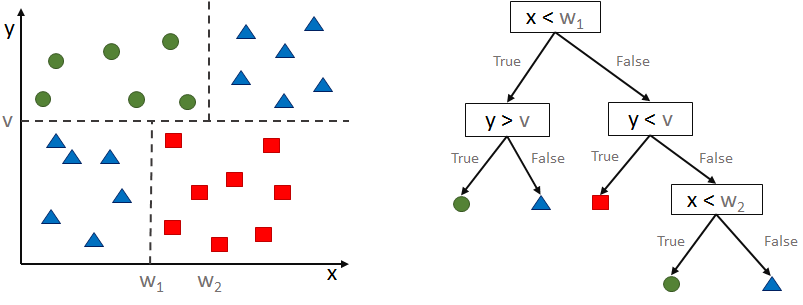
Entscheidungsbäume sind also eine Idee des überwachten maschinellen Lernens, bei der Algorithmen zum Einsatz kommen, die aus einer Datenmenge heraus eine hierarchische Struktur von möglichst wenigen Entscheidungswegen bilden. Diese Datenmenge stellt eine sogenannte Trainingsstichprobe dar. Meiner Erfahrung nach werde Entscheidungsbäume oftmals in ihrer Mächtigkeit, aber auch in ihrer Komplexität unterschätzt und die Einarbeitung fiel mehr selbst schwerer, als ich anfangs annahm: In der Praxis stellt das Verfahren den Data Scientist vor viele Herausforderungen.
In dieser Artikelserie wird es vier nachfolgende Teile geben (Verlinkung erfolgt nach Veröffentlichung):
- Teil 1 von 4 – Maße für Unreinheit in Daten
- Teil 2 von 4 – Der gängigste Entscheidungsbaum-Algorithmus: ID3
- Teil 3 von 4 – Ein Rechenbeispiel mit dem ID3-Algorithmus
- Teil 4 von 4 – Entscheidungsbaumverfahren in Python programmieren (erscheint demnächst!)
Benjamin Aunkofer
Benjamin Aunkofer ist Lead Data Scientist bei DATANOMIQ und Hochschul-Dozent für Data Science und Data Strategy. Darüber hinaus arbeitet er als Interim Head of Business Intelligence und gibt Seminare/Workshops zu den Themen BI, Data Science und Machine Learning für Unternehmen.








Trackbacks & Pingbacks
[…] nicht stehen, denn sie sind ein Beispiel des parallelen Ensembles bzw. des Voting Classifiers mit Entscheidungsbäumen (Decision Trees). Random Forests möchte ich an dieser Stelle dennoch ansprechen, denn sie sind […]
[…] Dieser Artikel ist Teil 2 von 4 der Artikelserie Maschinelles Lernen mit Entscheidungsbaumverfahren. […]
[…] Dieser Artikel ist Teil 2 von 4 der Artikelserie Maschinelles Lernen mit Entscheidungsbaumverfahren. […]
[…] Dieser Artikel ist Teil 1 von 4 der Artikelserie Maschinelles Lernen mit Entscheidungsbaumverfahren. […]
Leave a Reply
Want to join the discussion?Feel free to contribute!