KNN: Rückwärtspass
Im letzten Artikel der Serie haben wir gesehen wie bereits trainierte Netzwerke verwendet werden können. Als Training wird der Prozess bezeichnet der die Gewichte in einen Netzwerk so anpasst, dass bei einem Vorwärtspass durch ein Netzwerk zu einen festgelegten Eingangsdatensatz ein bestimmtes Ergebnis in der Ausgangsschicht ausgegeben wird. Im Umkehrschluss heißt das auch, dass wenn etwas anderes ausgeliefert wurde als erwartet, das Netzwerk entweder noch nicht gut genug oder aber auf ein anderes Problem hin trainiert wurde.
Training
Das Training selbst findet in drei Schritten statt. Zunächst werden die Gewichte initialisiert. Üblicherweise geschieht das mit zufälligen Werten, die aus einer Normalverteilung gezogen werden. Je nachdem wie viele Gewichte eine Schicht hat, ist es sinnvoll die Verteilung über den Sigma Term zu skalieren. Als Daumenregeln kann dabei eins durch die Anzahl der Gewichte in einer Schicht verwendet werden.
Im zweiten Schritt wird der Vorwärtspass für die Trainingsdaten errechnet. Das Ergebnis wird beim ersten Durchlauf alles andere als zufrieden stellend sein, es dient aber dem Rückwärtspass als Basis für dessen Berechnungen und Gewichtsänderungen. Außerdem kann der Fehler zwischen der aktuellen Vorhersage und dem gewünschten Ergebnis ermittelt werden, um zu entscheiden, ob weiter trainiert werden soll.
Der eigentliche Rückwärtspass errechnet aus der Differenz der Vorwärtspassdaten und der Zieldaten die Steigung für jedes Gewicht aus, in dessen Richtung dieses geändert werden muss, damit das Netzwerk bessere Vorhersagen trifft. Das klingt zunächst recht abstrakt, die genauere Mathematik dahinter werde ich in einem eigenen Artikel erläutern. Zur besseren Vorstellung betrachten wir die folgende Abbildung.
visuelle Darstellung aller Gewichtskombinationen und deren Vorhersagefehler
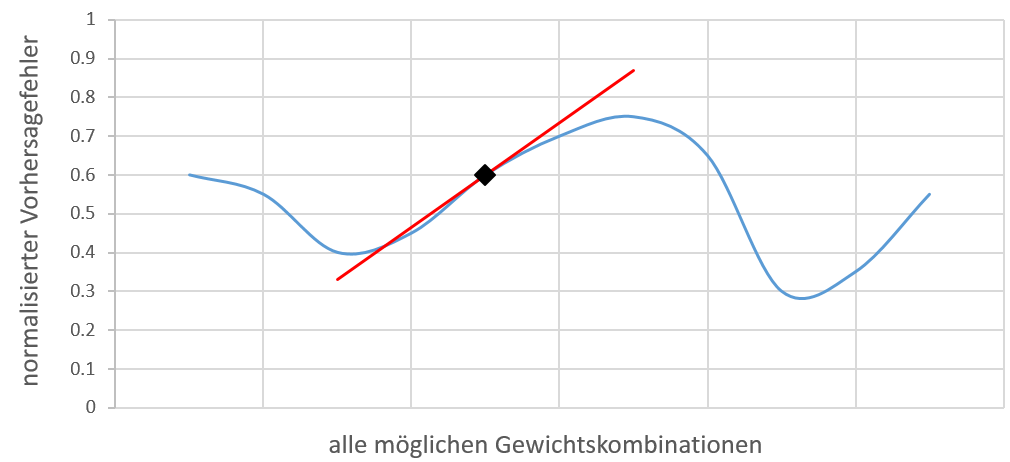
Das Diagramm zeigt in blau zu allen möglichen Gewichtskombinationen eines bestimmten, uns unbekannten, Netzwerks und Problems den entsprechenden Vorhersagefehler. Die Anzahl der Kombinationen hängt von der Anzahl der Gewichte und der Auflösung des Wertebereiches für diese ab. Theoretisch ist die Menge also unendlich, weshalb die blaue Kurve eine von mir ausgedachte Darstellung aller Kombinationen ist. Der erste Vorwärtspass liefert uns eine Vorhersage die eine normalisierte Differenz von 0.6 zu unserem eigentlichen Wunschergebnis aufweist. Visualisiert ist das Ganze mit einer schwarzen Raute. Der Rückwärtspass berechnet aus der Differenz und den Daten vom Vorwärtspass einen Änderungswunsch für jedes Gewicht aus. Da die Änderungen unabhängig von den anderen Gewichten ermittelt wurden, ist nicht bekannt was passieren würde wenn alle Gewichte sich auf einmal ändern würden. Aus diesem Grund werden die Änderungswünsche mit einer Lernrate abgeschwächt. Im Endeffekt ändert sich jedes Gewicht ein wenig in die Richtung, die es für richtig erachtet. In der Hoffnung einer Steigerung entlang zu einem lokalen Minimum zu folgen, werden die letzten beiden Schritte (Vor- und Rückwärtspass) mehrfach wiederholt. In dem obigen Diagramm würde die schwarze Raute der roten Steigung folgen und sich bei jeder Iteration langsam auf das linke lokale Minimum hinzubewegen.
Anwendungsbeispiel und Programmcode
Um den ganzen Trainingsprozess im Einsatz zu sehen, verwenden wir das Beispiel aus dem Artikel “KNN: Vorwärtspass”. Die verwendeten Daten kommen aus der Wahrheitstabelle eines X-OR Logikgatters und werden in ein 2-schichtiges Feedforward Netzwerk gespeist.
XOR Wahrheitstabelle
|
 |
Der Programmcode ist in Octave geschrieben und kann zu Testzwecken auf der Webseite von Tutorialpoint ausgeführt werden. Die erste Hälfte von dem Algorithmus kennen wir bereits, der Vollständigkeit halber poste ich ihn noch einmal, zusammen mit den Rückwärtspass. Hinzugekommen sind außerdem ein paar Konsolenausgaben, eine Lernrate- und eine Iterations-Variable die angibt wie viele Trainingswiederholungen durchlaufen werden sollen.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
%--------------------- Daten ----------------------- X = [0 0; % Eingangsdaten 0 1; 1 0; 1 1] Y = [0;1;1;0] % erwartete XOR Ausgangsdaten theta1 = normrnd(0, 1/(3*2), 3, 2); % 3x2 Gewichtsmatrix theta2 = normrnd(0, 1/(3*1), 3, 1); % 3x1 Gewichtsmatrix m = length(X) % Anzahl der Eingangsdaten iteration = 10000 % Anzahl der Trainingsiterationen alpha = 0.8 % lernrate printf("\n\nStarte Training ... ") for(i = 1:iteration) %--------------------- Vorwärtspass ----------------------- V = X; % anlegen der Eingangsdaten an die Eingangsschicht % 1. berechne die Aktivierungen der verborgenen Schicht Vb = [ones(m,1) V]; % hinzufügen der Bias Units (sind immer 1) Zv = Vb * theta1; % Summe aus den Eingangswerten multipliziert mit deren Gewichten H = 1 ./ (1 .+ e.^-Zv); % anwenden der Sigmoid Funktion auf die Aktivierungsstärke Zv % 2. berechne die Aktivierungen der Ausgangsschicht Hb = [ones(m,1) H]; % hinzufügen der Bias Units an die verborgene Schicht Zh = Hb * theta2; % Produkt aus den Aktivierungen der Neuronen in H und Theta2 O = 1 ./ (1 .+ e.^-Zh); % Vorhersage von dem Netzwerk % 3. berechne die Vorhersageungenauigkeit loss = (O .- Y) .^ 2; % quadratischer Fehler von der Vorhersage und der Zielvorgabe Y mse = sum(loss) / m; % durchschnittlicher quadratischer Fehler aller Vorhersagen %--------------------- Rückwärtspass ----------------------- % 1. Ableitung der Fehlerfunktion d = O .- Y; % Differenzmatrix zwischen der Vorhersage und der Zielvorgabe Y % 2. berechne die Änderungen für Theta2 und die Ableitung der Ausgangsschicht OMO = ones(size(O)) .- O; % Zwischenvariable: 1-Minus-Vorhersage Zhd = d .* O .* OMO; % Ableitung der Sigmoid Funktion theta2c = Hb' * Zhd; % Änderunswunsch für Theta2 Hd = Zhd * theta2'; % Ableitung von der Ausgangsschicht Hd(:,[1]) = []; % Ableitung von der Bias Unit % 3. berechne die Änderungen für Theta1 und die Ableitung der verborgenen Schicht HMO = ones(size(H)) .- H; % Zweischenvariable: 1 Minus Aktivierung der verborgenen Schicht Zvd = Hd .* H .* HMO; % Ableitung der Sigmoid Funktion von der Aktivierungsstärke Zv theta1c = Vb' * Zvd; % Änderunswunsch für Theta1 % weitere Ableitungen sind nicht notwendig theta1 -= theta1c .* alpha; % ändere die Gewichte von Theta1 und Theta2 theta2 -= theta2c .* alpha; % der Änderungswunsch wird von der Lernrate abgeschwächt endfor % Ausgabe von der letzten Vorhersage und den Gewichten printf("abgeschlossen. \n") printf("Letzte Vorhersage und trainierte Gewichte\n") O theta1 theta2 |
Zu jeder Zeile bzw. Funktion die wir im Vorwärtspass geschrieben haben, gibt es im Rückwärtspass eine abgeleitete Variante. Dank den Ableitungen können wir die Änderungswünsche der Gewichte in jeder Schicht ausrechnen und am Ende einer Trainingsiteration anwenden. Wir trainieren 10.000 Iterationen lang und verwenden eine Lernrate von 0,8. In komplexeren Fragestellungen, mit mehr Daten, würden diese Werte niedriger ausfallen.
Es ist außerdem möglich den ganzen Programmcode viel modularer aufzubauen. Dazu werde ich im nächsten Artikel auf eine mehr objekt-orientiertere Sprache wechseln. Nichts desto trotz liefert der obige Algorithmus gute Ergebnisse. Hier ist mal ein Ausgabebeispiel:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
X = 0 0 0 1 1 0 1 1 Y = 0 1 1 0 theta1 = 0.114950 0.046125 0.064683 0.139159 -0.164288 -0.094688 theta2 = 0.33607 -0.31128 0.13993 m = 4 iteration = 10000 alpha = 0.80000 Starte Training ... abgeschlossen. Letzte Vorhersage und trainierte Gewichte O = 0.014644 0.983308 0.986137 0.013060 theta1 = 3.2162 -3.0431 6.4365 5.6498 -6.3383 -5.8602 theta2 = 4.4759 -9.5057 9.9795 |
 ndgedanke dabei ist es, dass Neuronen entsprechend höher gewichtet werden sollten, wenn sie mit anderen hoch gewichteten Neuronen in Beziehung stehen. Wenn also beispielsweise eine Silbe in vielen hoch gewichteten Worten auftaucht, wird sie selbst entsprechend höher gewichtet.
ndgedanke dabei ist es, dass Neuronen entsprechend höher gewichtet werden sollten, wenn sie mit anderen hoch gewichteten Neuronen in Beziehung stehen. Wenn also beispielsweise eine Silbe in vielen hoch gewichteten Worten auftaucht, wird sie selbst entsprechend höher gewichtet.



 (Theta) multipliziert und die Ergebnisse aufsummiert. Das Zwischenergebnis ist die Aktivierungsstärke z:
(Theta) multipliziert und die Ergebnisse aufsummiert. Das Zwischenergebnis ist die Aktivierungsstärke z:![\[ z = X_0 \cdot \theta_0 + X_1 \cdot \theta_1 + X_2 \cdot \theta_2 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-49288c71db69e864888f642613627b1b_l3.png "Rendered by QuickLaTeX.com")

![\[ sigmoid(z) = \frac{1}{1+e^{-z}} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-d02636a1d3140b9e8e9dc48a1c5c395a_l3.png "Rendered by QuickLaTeX.com")
![\[ Y = sigmoid(X\theta) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-924f70586a4f97cd4aa0dceea3f2b047_l3.png "Rendered by QuickLaTeX.com")