Artikelserie: BI Tools im Vergleich – Datengrundlage
Dieser Artikel wird als Fortsetzung des ersten Artikels, einer Artikelserie zu BI Tools, die Datengrundlage erläutern.
Als Datengrundlage sollen die Trainingsdaten – AdventureWorks 2017 – von Microsoft dienen und Ziel soll es sein, ein möglichst gleiches Dashboard in jedem dieser Tools zu erstellen.
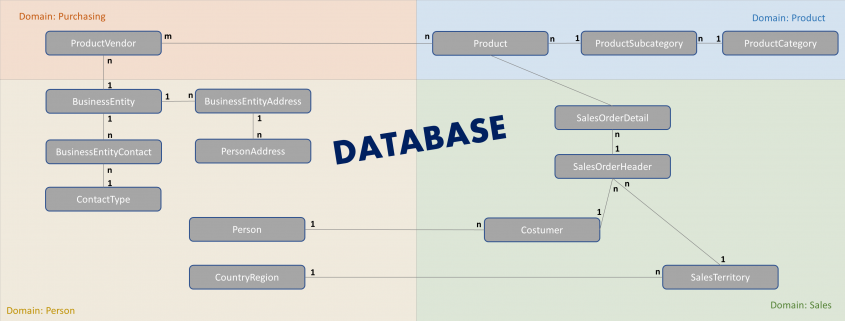
Bei der Datenbasis handelt es sich bereits um ein relationales Datenbankmodel mit strukturierten Daten, welches als Datei-Typ .bak zur Verfügung steht. Die Daten sind bereits bereinigt und normalisiert, sowie bestehen auch bereits Beziehungen zwischen den Tabellen. Demnach fallen sowohl aufwendige Datenbereinigungen weg, als auch der Aufbau eines relationalen Datenmodells im Dashboard. In den meisten Tools ist beides möglich, wenn auch nicht das optimale Programm. Vor allem sollte vermieden werden Datenbereinigungen in BI Tools vorzunehmen. Alle Tools bieten einem die Möglichkeit strukturierte und unstrukturierte Daten aus verschiedensten Datenquellen zu importieren. Die Datenquelle wird SQL Server von Microsoft sein, da die .bak Datei nicht direkt in die meisten Dashboards geladen werden kann und zudem auf Grund der Datenmenge ein kompletter Import auch nicht ratsam ist. Aus Gründen der Performance sollten nur die für das Dashboard relevanten Daten importiert werden. Für den Vergleich werden 15 von insgesamt 71 Tabellen importiert, um Visualisierungen für wesentliche Geschäftskennzahlen aufzubauen. Die obere Grafik zeigt das Entity-Relationship-Modell (ERM) zu den relevanten Tabellen. Die Datengrundlage eignet sich sehr gut für tiefer gehende Analysen und bietet zugleich ein großes Potential für sehr ausgefallene Visualisierungen. Im Fokus dieser Artikelserie soll aber nicht die Komplexität der Grafiken, sondern die allgemeine Handhabbarkeit stehen. Allgemein besteht die Gefahr, dass die Kernaussagen eines Reports in den Hintergrund rücken bei der Verwendung von zu komplexen Visualisierungen, welche lediglich der Ästhetik dienlich sind.
Eine Beschränkung soll gelten: So soll eine Manipulation von Daten lediglich in den Dashboards selbst vorgenommen werden. Bedeutet das keine Tabellen in SQL Server geändert oder Views erstellt werden. Gehen wir einfach Mal davon aus, dass der Data Engineer Haare auf den Zähnen hat und die Zuarbeit in jeglicher Art und Weise verwehrt wird.
Also ganz nach dem Motto: Help yourself! 
Daten zum Üben gibt es etliche. Einfach Mal Github, Kaggle oder andere Open Data Quellen anzapfen. Falls ihr Lust habt, dann probiert euch doch selber einmal an den Dashboards. Ihr solltet ein wenig Zeit mitbringen, aber wenn man erstmal drin ist macht es viel Spaß und es gibt immer etwas neues zu entdecken! Das erste Dashboard und somit die Fortsetzung dieser Artikelserie wird Power BI als Grundlage haben.
Hier ein paar Links um euch startklar zu machen, falls das Interesse in euch geweckt wurde.







 gif
gif