Mit diesem Beitrag möchte ich darlegen, welche Grenzen uns in komplexen Umfeldern im Kontext Steuerung und Regelung auferlegt sind. Auf dieser Basis strebe ich dann nachgelagert eine Differenzierung in Bezug des Einsatzes von Data Science und Big Data, ab sofort mit Big Data Analytics bezeichnet, an. Aus meiner Sicht wird oft zu unreflektiert über Data Science und Künstliche Intelligenz diskutiert, was nicht zuletzt die Angst vor Maschinen schürt.
Basis meiner Ausführungen im ersten Part meines Beitrages ist der Kategorienfehler, der von uns Menschen immer wieder in Bezug auf Kompliziertheit und Komplexität vollführt wird. Deshalb werde ich am Anfang einige Worte über Kompliziertheit und Komplexität verlieren und dabei vor allem auf die markanten Unterschiede eingehen.
Kompliziertheit und Komplexität – der Versuch einer Versöhnung
Ich benutze oft die Begriffe „tot“ und „lebendig“ im Kontext von Kompliziertheit und Komplexität. Themenstellungen in „lebendigen“ Kontexten können niemals kompliziert sein. Sie sind immer komplex. Themenstellungen in „toten“ Kontexten sind stets kompliziert. Das möchte ich am Beispiel eines Uhrmachers erläutern, um zu verdeutlichen, dass auch Menschen in „toten“ Kontexten involviert sein können, obwohl sie selber lebendig sind. Deshalb die Begriffe „tot“ und „lebendig“ auch in Anführungszeichen.
Ein Uhrmacher baut eine Uhr zusammen. Dafür gibt es ein ganz klar vorgegebenes Rezept, welches vielleicht 300 Schritte beinhaltet, die in einer ganz bestimmten Reihenfolge abgearbeitet werden müssen. Werden diese Schritte befolgt, wird definitiv eine funktionierende Uhr heraus kommen. Ist der Uhrmacher geübt, hat er also genügend praktisches Wissen, ist diese Aufgabe für ihn einfach. Für mich als Ungelernten wird diese Übung schwierig sein, niemals komplex, denn ich kann ja einen Plan befolgen. Mit Übung bin ich vielleicht irgendwann so weit, dass ich diese Uhr zusammen gesetzt bekomme. Der Bauplan ist fix und ändert sich nicht. Man spricht hier von Monokontexturalität. Solche Tätigkeiten könnte man auch von Maschinen ausführen lassen, da klar definierte Abfolgen von Schritten programmierbar sind.
Nun stellen wir uns aber mal vor, dass eine Schraube fehlt. Ein Zahnrad kann nicht befestigt werden. Hier würde die Maschine einen Fehler melden, weil jetzt der Kontext verlassen wird. Das Fehlen der Schraube ist nicht Bestandteil des Kontextes, da es nicht Bestandteil des Planes und damit auch nicht Bestandteil des Programmcodes ist. Die Maschine weiß deshalb nicht, was zu tun ist. Der Uhrmacher ist in der Lage den Kontext zu wechseln. Er könnte nach anderen Möglichkeiten der Befestigung suchen oder theoretisch probieren, ob die Uhr auch ohne Zahnrad funktioniert oder er könnte ganz einfach eine Schraube bestellen und später den Vorgang fortsetzen. Der Uhrmacher kann polykontextural denken und handeln. In diesem Fall wird dann der komplizierte Kontext ein komplexer. Der Bauplan ist nicht mehr gültig, denn Bestellung einer Schraube war in diesem nicht enthalten. Deshalb meldet die Maschine einen Fehler. Der Bestellvorgang müsste von einem Menschen in Form von Programmcode voraus gedacht werden, so dass die Maschine diesen anstoßen könnte. Damit wäre diese Option dann wieder Bestandteil des monokontexturalen Bereiches, in dem die Maschine agieren kann.
Kommen wir in diesem Zusammenhang zum Messen und Wahrnehmen. Maschinen können messen. Messen passiert in monokontexturalen Umgebungen. Die Maschine kann messen, ob die Schraube festgezogen ist, die das Zahnrad hält: Die Schraube ist „fest“ oder „lose“. Im Falle des Fehlens der Schraube verlässt man die Ebene des Messens und geht in die Ebene der Wahrnehmung über. Die Maschine kann nicht wahrnehmen, der Uhrmacher schon. Beim Wahrnehmen muss man den Kontext erst einmal bestimmen, da dieser nicht per se gegeben sein kann. „Die Schraube fehlt“ setzt die Maschine in den Kontext „ENTWEDER fest ODER lose“ und dann ist Schluss. Die Maschine würde stetig zwischen „fest“ und „lose“ iterieren und niemals zum Ende gelangen. Eine endlose Schleife, die mit einem Fehler abgebrochen werden muss. Der Uhrmacher kann nach weiteren Möglichkeiten suchen, was gleichbedeutend mit dem Suchen nach einem weiteren Kontext ist. Er kann vielleicht eine neue Schraube suchen oder versuchen das Zahnrad irgendwie anders geartet zu befestigen.
In „toten“ Umgebungen ist der Mensch mit der Umwelt eins geworden. Er ist trivialisiert. Das ist nicht despektierlich gemeint. Diese Trivialisierung ist ausreichend, da ein Rezept in Form eines Algorithmus vorliegt, welcher zielführend ist. Wahrnehmen ist also nicht notwendig, da kein Kontextwechsel vorgenommen werden muss. Messen reicht aus.
In einer komplexen und damit „lebendigen“ Welt gilt das Motto „Sowohl-Als-Auch“, da hier stetig der Kontext gewechselt wird. Das bedeutet Widersprüchlichkeiten handhaben zu müssen. Komplizierte Umgebungen kennen ausschließlich ein „Entweder-Oder“. Damit existieren in komplizierten Umgebungen auch keine Widersprüche. Komplizierte Sachverhalte können vollständig in Programmcode oder Algorithmen geschrieben und damit vollständig formallogisch kontrolliert werden. Bei komplexen Umgebungen funktioniert das nicht, da unsere Zweiwertige Logik, auf die jeder Programmcode basieren muss, Widersprüche und damit Polykontexturalität ausschließen. Komplexität ist nicht kontrollier-, sondern bestenfalls handhabbar.
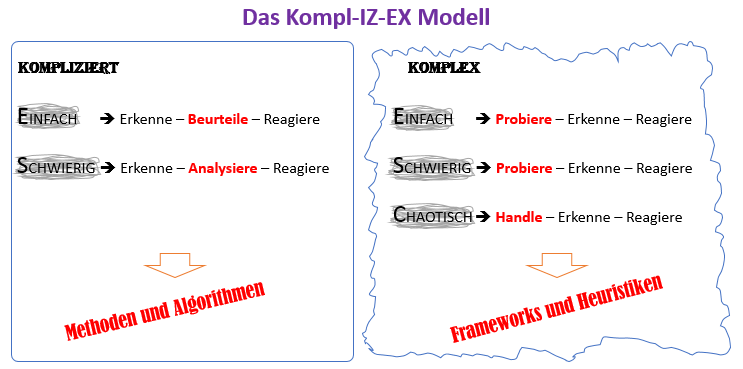
Diese Erkenntnisse möchte ich nun nutzen, um das bekannte Cynefin Modell von Dave Snowden zu erweitern, da dieses in der ursprünglichen Form zu Kategorienfehler zwischen Kompliziertheit und Komplexität verleitet. Nach dem Cynefin Modell werden die Kategorien „einfach“, „kompliziert“ und „komplex“ auf einer Ebene platziert. Das ist aus meiner Sicht nicht passfähig. Die Einstufung „einfach“ und damit auch „schwierig“, die es im Modell nicht gibt, existiert eine Ebene höher in beiden Kategorien, „kompliziert“ und „komplex“. „Einfach“ ist also nicht gleich „einfach“.
„Einfach“ in der Kategorie „kompliziert“ bedeutet, dass das ausreichende Wissen, sowohl praktisch als auch theoretisch, gegeben ist, um eine komplizierte Fragestellung zu lösen. Grundsätzlich ist ein Lösungsweg vorhanden, den man theoretisch kennen und praktisch anwenden muss. Wird eine komplizierte Fragestellung als „schwierig“ eingestuft, ist der vorliegende Lösungsweg nicht bekannt, aber grundsätzlich vorhanden. Er muss erlernt werden, sowohl praktisch als auch theoretisch. In der Kategorie „kompliziert“ rede ich also von Methoden oder Algorithmen, die an den bekannten Lösungsweg an-gelehnt sind.
Für „komplexe“ Fragestellungen kann per Definition kein Wissen existieren, welches in Form eines Rezeptes zu einem Lösungsweg geformt werden kann. Hier sind Erfahrung, Talent und Können essentiell, die Agilität im jeweiligen Kontext erhöhen. Je größer oder kleiner Erfahrung und Talent sind, spreche ich dann von den Wertungen „einfach“, „schwierig“ oder „chaotisch“. Da kein Rezept gegeben ist, kann man Lösungswege auch nicht vorweg in Form von Algorithmen programmieren. Hier sind Frameworks und Heuristiken angebracht, die genügend Freiraum für das eigene Denken und Fühlen lassen.
Die untere Abbildung stellt die Abhängigkeiten und damit die Erweiterung des Cynefin Modells dar.
Data Science und „lebendige“ Kontexte – der Versuch einer Versöhnung
Gerade beim Einsatz von Big Data Analytics sind wir dem im ersten Part angesprochenen Kategorienfehler erlegen, was mich letztlich zu einer differenzierten Sichtweise auf Big Data Analytics verleitet. Darauf komme ich nun zu sprechen.
In vielen Artikeln, Berichten und Büchern wird Big Data Analytics glorifiziert. Es gibt wenige Autoren, die eine differenzierte Betrachtung anstreben. Damit meine ich, klare Grenzen von Big Data Analytics, insbesondere in Bezug zum Einsatz auf Menschen, aufzuzeigen, um damit einen erfolgreichen Einsatz erst zu ermöglichen. Auch viele unserer Hirnforscher tragen einen erheblichen Anteil zum Manifestieren des Kategorienfehlers bei, da sie glauben, Wirkmechanismen zwischen der materiellen und der seelischen Welt erkundet zu haben. Unser Gehirn erzeugt aus dem Feuern von Neuronen, also aus Quantitäten, Qualitäten, wie „Ich liebe“ oder „Ich hasse“. Wie das funktioniert ist bislang unbekannt. Man kann nicht mit Algorithmen aus der komplizierten Welt Sachverhalte der komplexen Welt erklären. Die Algorithmen setzen auf der Zweiwertigen Logik auf und diese lässt keine Kontextwechsel zu. Ich habe diesen Fakt ja im ersten Teil eingehend an der Unterscheidung zwischen Kompliziertheit und Komplexität dargelegt.
Es gibt aber auch erfreulicherweise, leider noch zu wenige, Menschen, die diesen Fakt erkennen und thematisieren. Ich spreche hier stellvertretend Prof. Harald Walach an und zitiere aus seinem Artikel »Sowohl als auch« statt »Entweder-oder« – oder: wie man Kategorienfehler vermeidet.
„Die Wirklichkeit als Ganzes ist komplexer und lässt sich genau nicht mit solchen logischen Instrumenten komplett analysieren. … Weil unser Überleben als Art davon abhängig war, dass wir diesen logischen Operator so gut ausgeprägt haben ist die Gefahr groß dass wir nun alles so behandeln. … Mit Logik können wir nicht alle Probleme des Lebens lösen. … Geist und neuronale Entladungen sind Prozesse, die unterschiedlichen kategorialen Ebenen angehören, so ähnlich wie „blau“ und „laut“.
Aus diesen Überlegungen habe ich eine Big Data Analytics Matrix angefertigt, mit welcher man einen Einsatz von Big Data Analytics auf Menschen, also in „lebendige“ Kontexte, verorten kann.
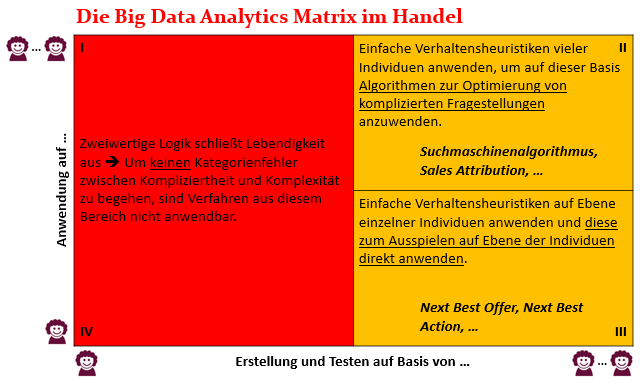
Die Matrix hat zwei Achsen. Die x-Achse stellt dar, auf welcher Basis, einzelne oder viele Menschen, Erkenntnisse direkt aus Daten und den darauf aufsetzenden Algorithmen gezogen werden sollen. Die y-Achse bildet ab, auf welcher Basis, einzelne oder viele Menschen, diese gewonnenen Erkenntnisse dann angewendet werden sollen. Um diese Unterteilung anschaulicher zu gestalten, habe ich in den jeweiligen Quadranten Beispiele eines möglichen Einsatzes von Big Data Analytics im Kontext Handel zugefügt.
An der Matrix erkennen wir, dass wir auf Basis von einzelnen Individuen keine Erkenntnisse maschinell über Algorithmen errechnen können. Tun wir das, begehen wir den von mir angesprochenen Kategorienfehler zwischen Kompliziertheit und Komplexität. In diesem Fall kennzeichne ich den gesamten linken roten Bereich der Matrix. Anwendungsfälle, die man gerne in diesen Bereich platzieren möchte, muss man über die anderen beiden gelben Quadranten der Matrix lösen.
Für das Lösen von Anwendungsfällen innerhalb der beiden gelben Quadranten kann man sich den Fakt zu Nutze machen, dass sich komplexe Vorgänge oft durch einfache Handlungsvorschriften beschreiben lassen. Achtung! Hier bitte nicht dem Versuch erlegen sein, „einfach“ und „einfach“ zu verwechseln. Ich habe im ersten Teil bereits ausgeführt, dass es sowohl in der Kategorie „kompliziert“, als auch in der Kategorie „komplex“, einfache Sachverhalte gibt, die aber nicht miteinander ob ihrer Schwierigkeitsstufe verglichen werden dürfen. Tut man es, dann, ja sie wissen schon: Kategorienfehler. Es ist ähnlich zu der Fragestellung: “Welche Farbe ist größer, blau oder rot?” Für Details hierzu verweise ich Sie gerne auf meinen Beitrag Komplexitäten entstehen aus Einfachheiten, sind aber schwer zu handhaben.
Möchten sie mehr zu der Big Data Analytics Matrix und den möglichen Einsätzen er-fahren, muss ich sie hier ebenfalls auf einen Beitrag von mir verweisen, da diese Ausführungen diesen Beitrag im Inhalt sprengen würden.
Mensch und Maschine – der Versuch einer Versöhnung
Wie Ihnen sicherlich bereits aufgefallen ist, enthält die Big Data Analytics Matrix keinen grünen Bereich. Den Grund dafür habe ich versucht, in diesem Beitrag aus meiner Sicht zu untermauern. Algorithmen, die stets monokontextural aufgebaut sein müssen, können nur mit größter Vorsicht im „lebendigen“ Kontext angewendet werden.
Erste Berührungspunkte in diesem Thema habe ich im Jahre 1999 mit dem Schreiben meiner Diplomarbeit erlangt. Die Firma, in welcher ich meine Arbeit verfasst habe, hat eine Maschine entwickelt, die aufgenommene Bilder aus Blitzgeräten im Straßenverkehr automatisch durchzieht, archiviert und daraus Mahnschreiben generiert. Ein Problem dabei war das Erkennen der Nummernschilder, vor allem wenn diese verschmutzt waren. Hier kam ich ins Spiel. Ich habe im Rahmen meiner Diplomarbeit ein Lernverfahren für ein Künstlich Neuronales Netz (KNN) programmiert, welches genau für diese Bilderkennung eingesetzt wurde. Dieses Lernverfahren setzte auf der Backpropagation auf und funktionierte auch sehr gut. Das Modell lag im grünen Bereich, da nichts in Bezug auf den Menschen optimiert werden sollte. Es ging einzig und allein um Bilderkennung, also einem „toten“ Kontext.
Diese Begebenheit war der Startpunkt für mich, kritisch die Strömungen rund um die Künstliche Intelligenz, vor allem im Kontext der Modellierung von Lebendigkeit, zu erforschen. Einige Erkenntnisse habe ich in diesem Beitrag formuliert.






 scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”
scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”