Interview – The Importance of Machine Learning for the Data Driven Business
To become more data-driven, organizations must mature their analytics and automate more of their decision making processes for innovation and differentiation. Data science seems like the right approach, yet is a new and fast moving field that seems to have as many dead ends as it has high ways to value. Cloudera Fast Forward Labs, led by Hilary Mason, shows companies the way.
 Alice Albrecht is a research engineer at Cloudera Fast Forward Labs. She spends her days researching the latest and greatest in machine learning and artificial intelligence and bringing that knowledge to working prototypes and delivering concrete advice for clients. Prior to joining Fast Forward Labs, Alice worked in both finance and technology companies as a practicing data scientist, data science leader, and – most recently – a data product manager. In addition to teaching machines to do cool things, Alice is passionate about mentoring and helping others grow in their careers. Alice holds a PhD from Yale in cognitive neuroscience where she studied how humans summarize sensory information from the world around them and the neural substrates that underlie those summaries.
Alice Albrecht is a research engineer at Cloudera Fast Forward Labs. She spends her days researching the latest and greatest in machine learning and artificial intelligence and bringing that knowledge to working prototypes and delivering concrete advice for clients. Prior to joining Fast Forward Labs, Alice worked in both finance and technology companies as a practicing data scientist, data science leader, and – most recently – a data product manager. In addition to teaching machines to do cool things, Alice is passionate about mentoring and helping others grow in their careers. Alice holds a PhD from Yale in cognitive neuroscience where she studied how humans summarize sensory information from the world around them and the neural substrates that underlie those summaries.
![]() Read this article in German:
Read this article in German:
“Interview – Die Bedeutung von Machine Learning für das Data Driven Business“
Data Science Blog: Ms. Albrecht, you are a well-known keynote speaker for data science and artificial intelligence. While data science has arrived business already, deep learning seems to be the new trend. Is artificial intelligence for business already normal business or is it an overrated hype?
I’d say it isn’t either of those two options. Data science is now widely adopted but companies still struggle to integrate this new discipline into their existing businesses. As for deep learning, it really depends on the company that’s looking into using this technique. I wouldn’t say that deep learning is by any means part of business as usual- nor should it be. It’s a tool like any other and building a capacity for using a tool without clearly defined business needs is a recipe for disaster.
Data Science Blog: Just to make sure what we are talking about: What are the differences and overlaps between data analytics, data science, machine learning, deep learning and artificial intelligence?
Here at Cloudera Fast Forward Labs, we like to think of data analytics as collecting data and counting things (mostly for quick charts and reports). Data science solves business problems by counting cleverly and predicting things with the data that’s collected. Machine learning is about solving problems with new kinds of feedback loops that improve with more data. Deep learning is a particular type of machine learning and is not itself a separate concept or type of tool. Artificial intelligence taps into something more complicated than what we’re seeing today – it’s much broader than training machines to repetitively do very specialized tasks or solve very narrow problems.
Data Science Blog: And how can we add the context to big data?
From a theoretical perspective, data science has been around for decades. The building blocks for modern day machine learning, deep learning and artificial intelligence are based on mathematical theorems that go back to the 1940’s and 1950’s. The challenge was that at the time, compute power and data storage capacity were simply too expensive for the approaches to be implemented. Today that’s all changed.. Not only has the cost of data storage dropped considerably, open source technology like Apache Hadoop has made it possible to store any volume of data at costs approaching zero. Compute power, even highly specialised chip architectures, are now also available on demand and only for the time organisations need them through public and private cloud solutions. The decreased cost of both data storage and compute power, together with a growing list of tools and resources readily available via the open source community allows companies of any size to benefit from data (no matter that size of that data).
Data Science Blog: What are the challenges for organizations in getting started with data science?
I see two big challenges when getting started with data science. One is ensuring that you have organizational alignment around exactly what type of work data scientists will deliver (and timing for those projects). The second hurdle is around ensuring that you have the right data in place before you start hiring data scientists. This can be tricky if you don’t have in-house expertise in this area, so sometimes it’s better to hire a data engineer or a data strategist (or director of data science) before you ever get started building out a data science team.
Data Science Blog: There are many discussions about how to build a data-driven business. Is it just about using data science to get a better understanding of customer behavior?
No, being data driven doesn’t just mean better understanding your customers (though that is one way that data science can help in an organization). Aside from building an organization that relies on data and analytics to help them make decisions (about customer behavior or otherwise), being a data-driven business means that data is powering your core products.
Data Science Blog: The number of technologies, tools and frameworks is increasing. For organizations this also means increasing complexity. Do companies need to stay always up-to-date or could it be an advice to wait and imitate pioneers later?
While it’s not critical (or advisable) for organizations to adopt every new advancement that comes along, it is critical for them to stay abreast of emerging frameworks. If a business waits to see what others are doing, and therefore don’t invest in understanding how new advancements can affect their particular business, they’ve likely already missed the boat.
Data Science Blog: Global players have big budgets just for doing research and setting up data labs. Middle-sized companies need to see the break even point soon. How can we accelerate the value generation of data science?
Having a team that is highly focused on a specific set of projects that are well-scoped and aligned to the business makes all the difference. Data science and machine learning don’t have to sacrifice doing research and being innovative in order to produce value. The biggest difference is that smaller teams will have to be more aware of how their choice of project fits into emerging frameworks and their particular acute and near term business needs.
Data Science Blog: How does Cloudera Fast Forward Labs help other organizations to accelerate their start with machine learning?
We advise organizations, based on their particular needs, on what the latest advancements are in machine learning and data science, how to build and structure their data teams to develop the capabilities they need to meet their goals, and how to quickly implement custom forward-looking solutions using their own data and in-house expertise.
Data Science Blog: Finally, a question for our younger readers who are looking for a career as a data expert: What makes a good data scientist? Do you like to work with introverted coding nerds or the data loving business experts?
A good data scientists should be deeply curious and have a love for the ways in which data can lead to new discoveries and power the next generation of products. We expect the people who thrive in this field to come from a variety of backgrounds and experiences.




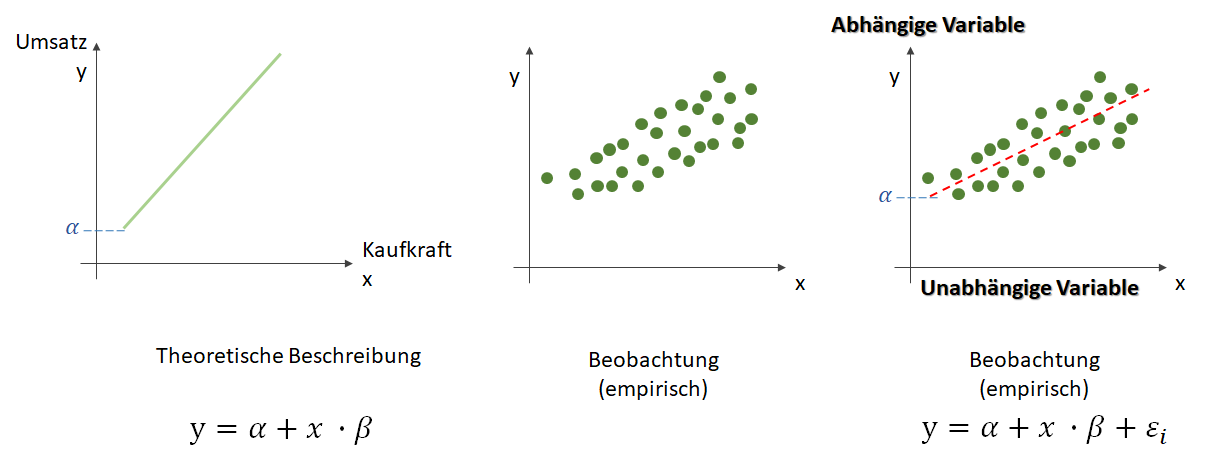
 , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  der Zielwert (abhängige Variable) und
der Zielwert (abhängige Variable) und  der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable
der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable  (Alpha) ist der
(Alpha) ist der  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung. ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.svg "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.svg "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.svg "Rendered by QuickLaTeX.com")
 .
.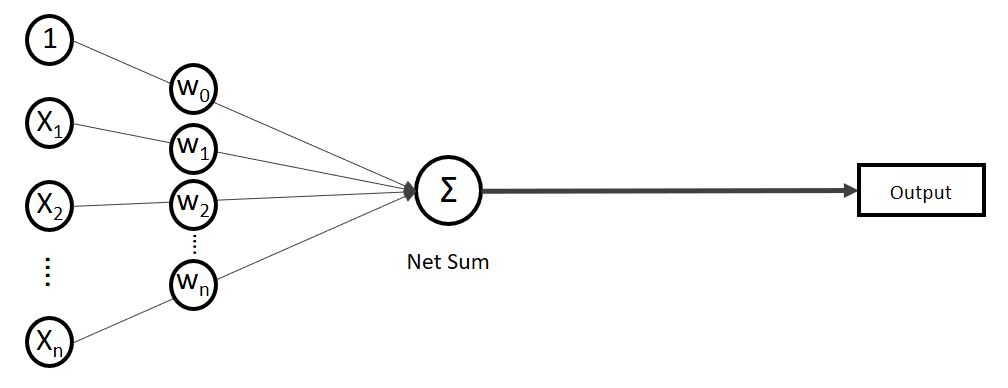
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
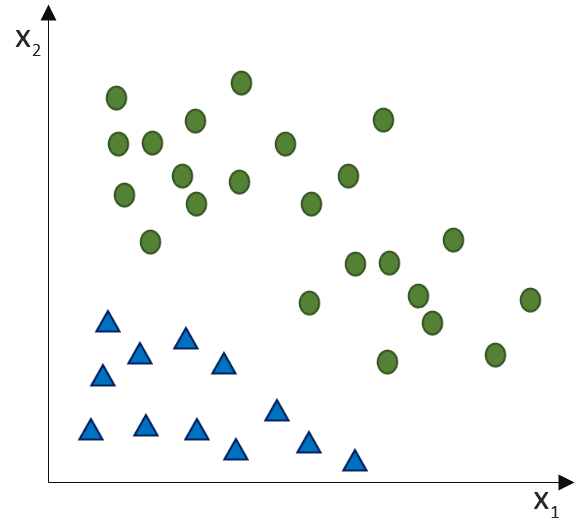
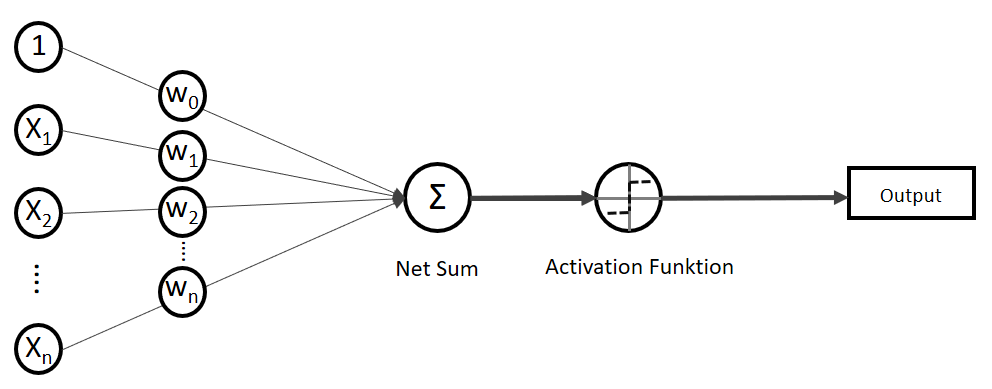
 (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 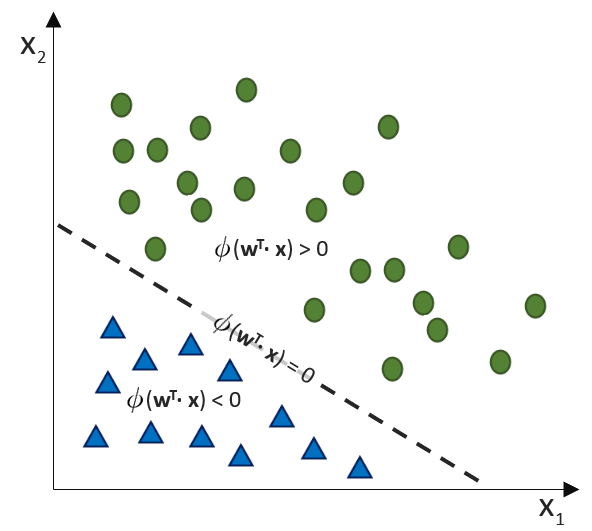
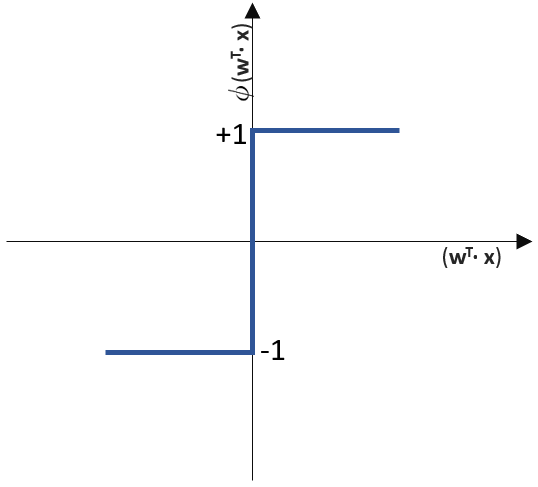
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.svg "Rendered by QuickLaTeX.com")
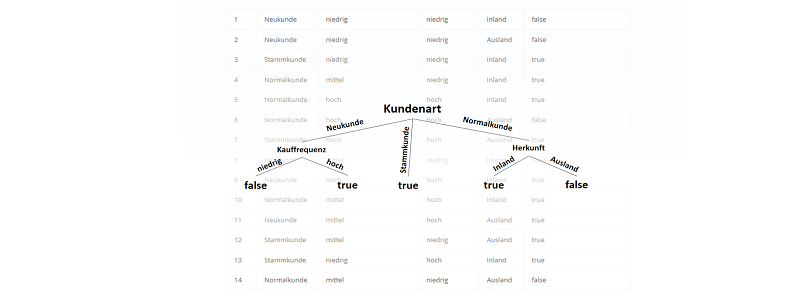
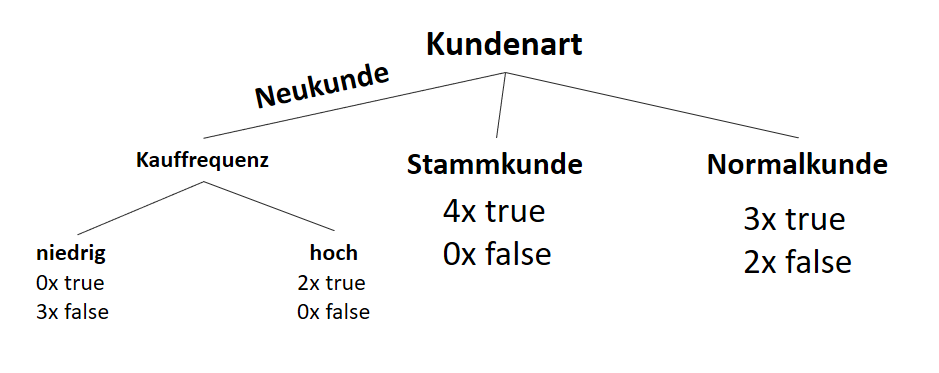
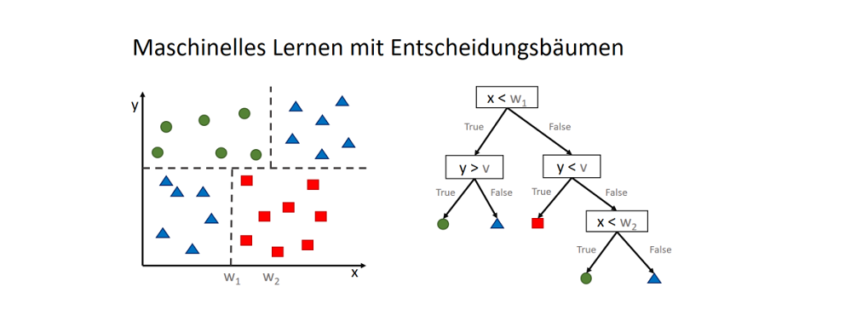
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

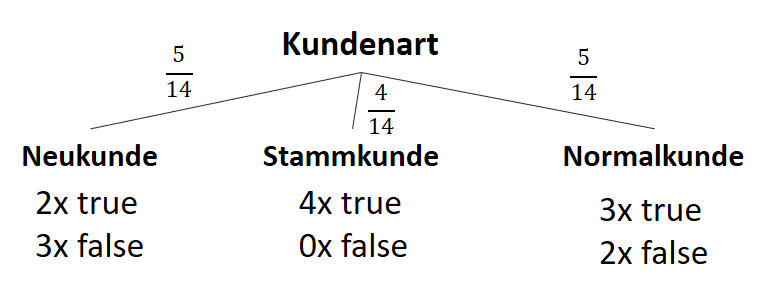



![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.svg "Rendered by QuickLaTeX.com")
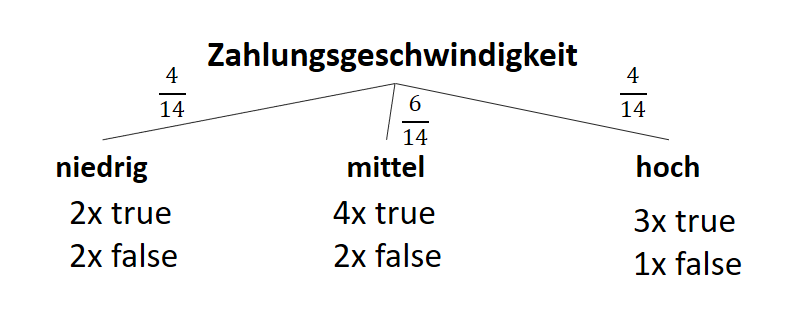



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.svg "Rendered by QuickLaTeX.com")
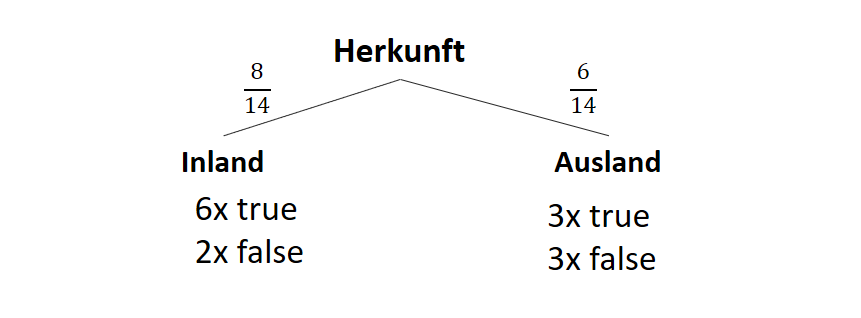


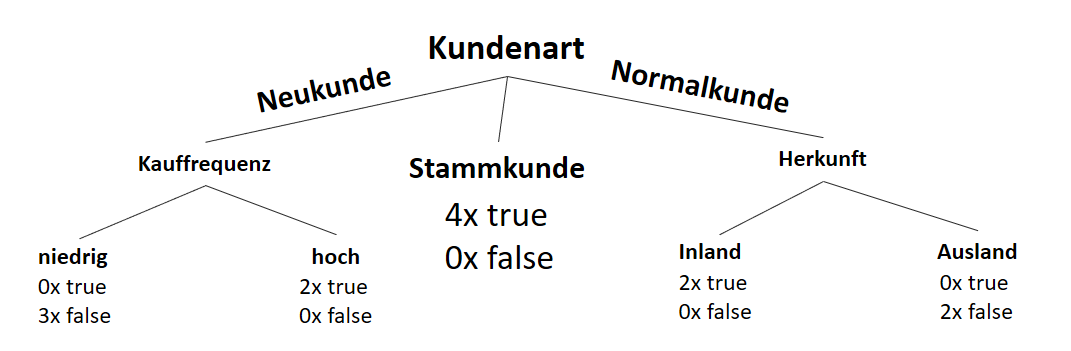
![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.svg "Rendered by QuickLaTeX.com")
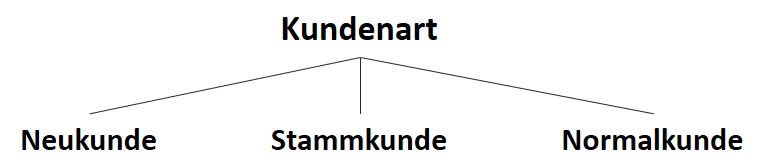
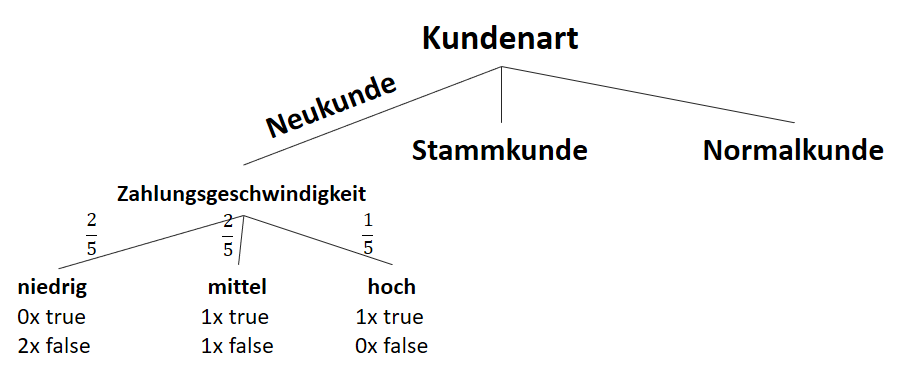



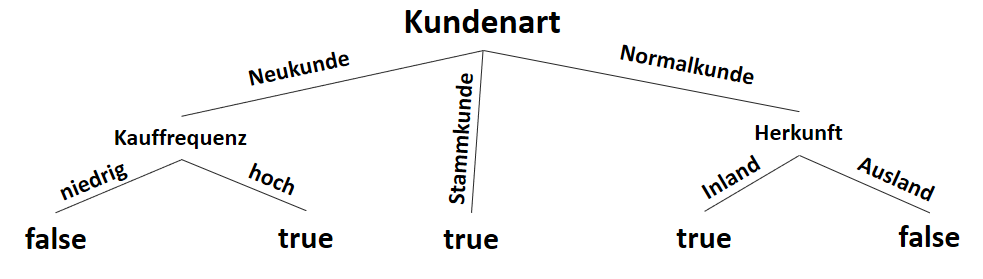
![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.svg "Rendered by QuickLaTeX.com")
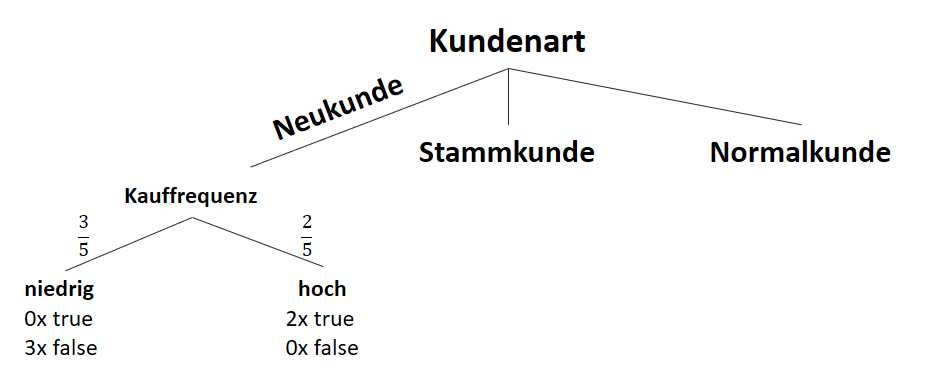
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.svg "Rendered by QuickLaTeX.com")