OLAP-Würfel
Der OLAP-Würfel
Alles ist relativ! So auch die Anforderungen an Datenbanksysteme. Je nachdem welche Arbeitskollegen/innen dazu gefragt werden, können unterschiedliche Wünschen und Anforderungen an Datenbanksysteme dabei zu Tage kommen.
Die optimale Ausrichtung des Datenbanksystems auf seine spezielle Anwendung hin, setzt den Grundstein für eine performante und effizientes Informationssystem und sollte daher wohl überlegt sein. Eine klassische Unterscheidung für die Anwendung von Datenbanksystemen lässt sich hierbei zwischen OLTP (Online Transaction Processing) und OLAP (Online Analytical Processing) machen.
OLTP-Datenbanksysteme zeichnen sich insbesondere durch die direkte Verarbeitung bei hohem Durchsatz von Transaktionen, sowie den parallelen Zugriff auf Informationen aus und werden daher vor allem für die Erfassung von operativen Geschäftsfällen eingesetzt. Im Gegensatz zu OLTP-Systemen steht bei OLAP-Systemen die analytische Verarbeitung von großen Datenbeständen im Vordergrund. Die folgende Grafik veranschaulicht das Zusammenwirken von OLTP und OLAP.
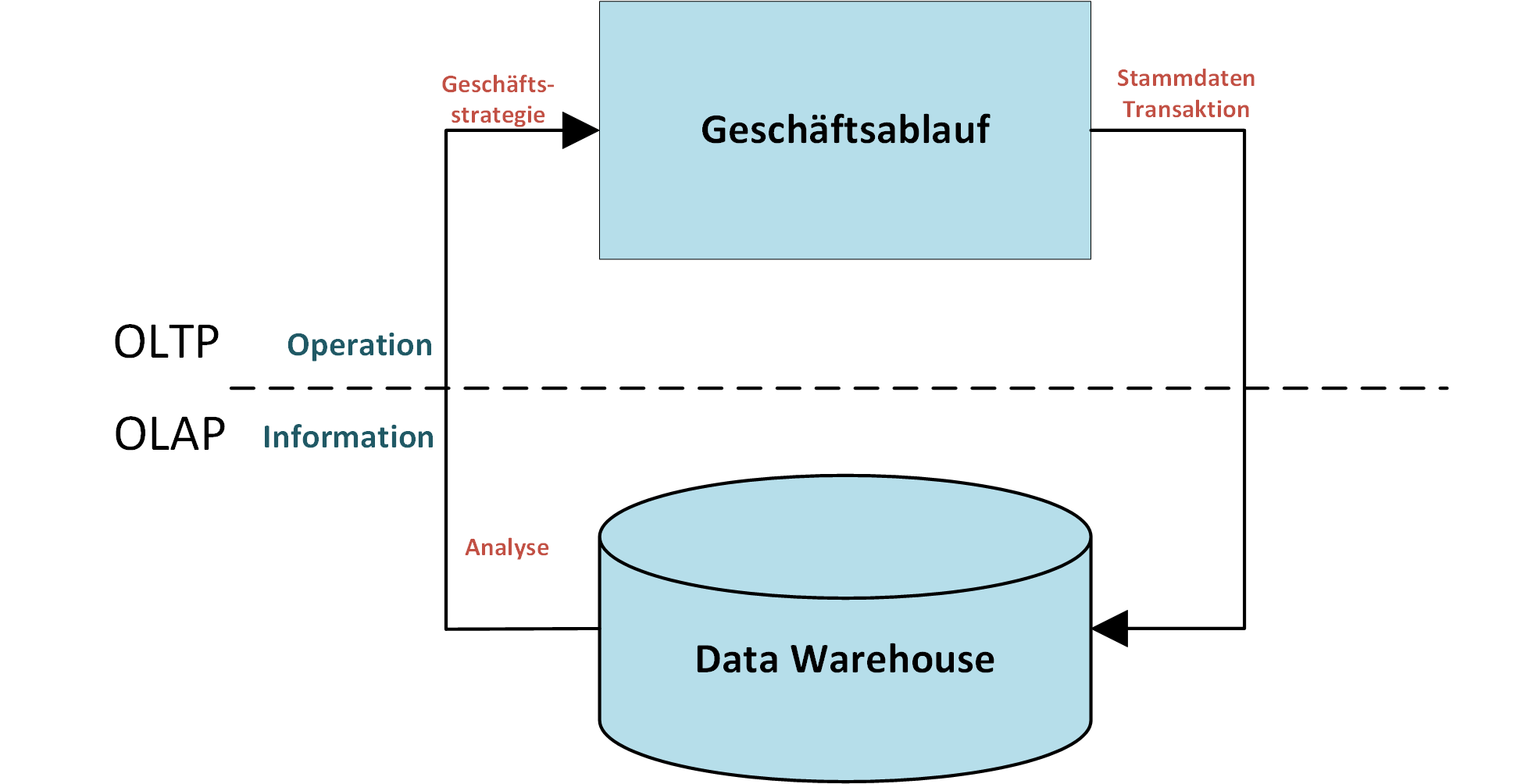
Da OLAP-Systeme eine mehrdimensionale und subjektbezogen Datenstruktur aufweisen, können statistisch-analytische Verarbeitungen auf diese Datenmengen effizient angewandt werden. Basierend auf dem Sternen-Schema, werden in diesem Zusammenhang häufig sogenannte OLAP-Würfel (engl. „Cube“) verwendet, welcher die Grundlage für multidimensionale Analysen bildet. Im Folgenden werden wir den OLAP-Würfel etwas näher beleuchten.
Aufbau des OLAP-Würfels
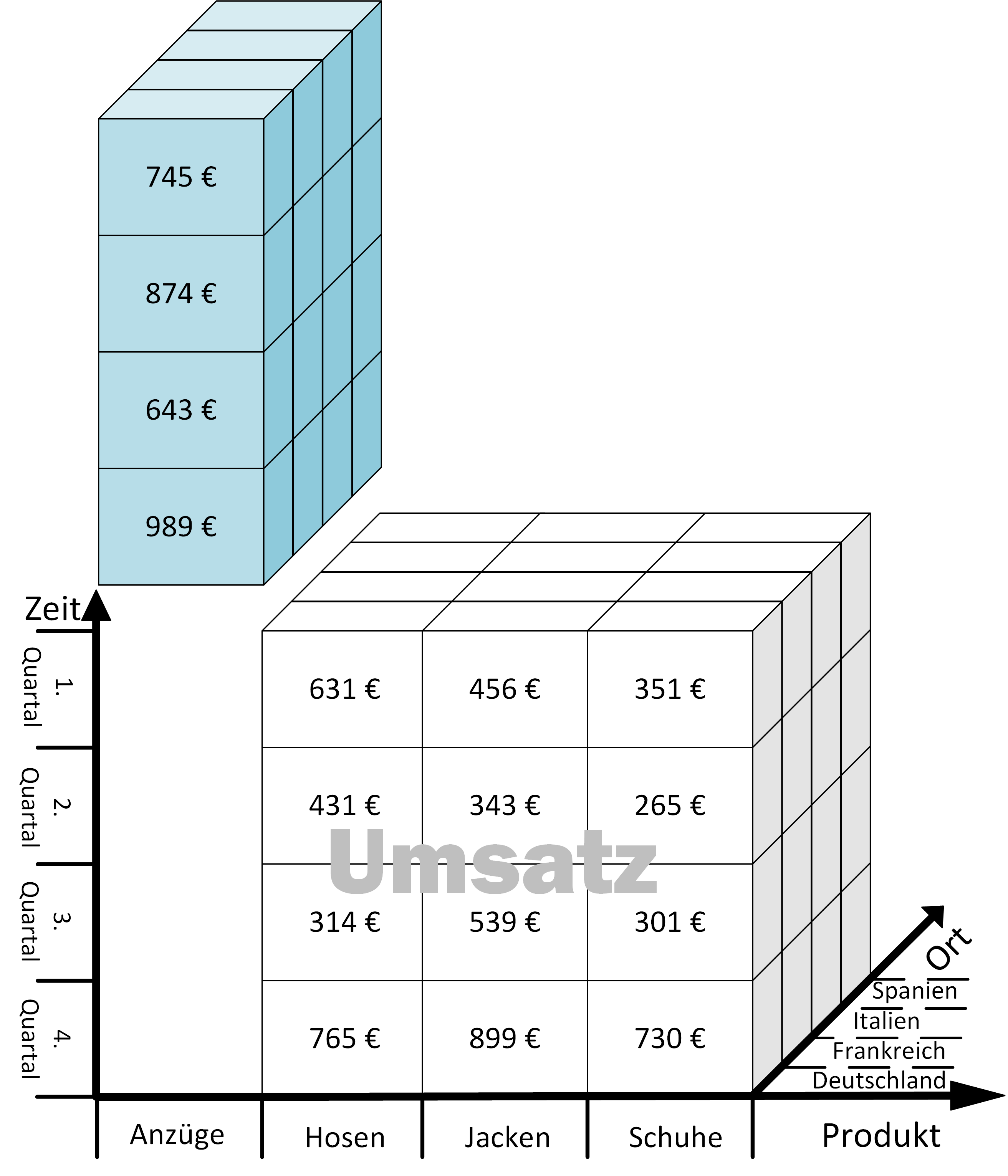
Der OLAP-Würfel ist eine Zusammensetzung aus multidimensionale Datenarrays. Die logische Anordnung der Daten über mehrere Dimensionen erlaubt dem Benutzer verschiedene Ansichten auf die Daten in gleicher Weise zu erlangen. Der Begriff „Würfel“ („Cube“) referenziert hierbei auf die Darstellung eines OLAP-Würfels mit drei Dimensionen. OLAP-Würfel mit mehr als drei Dimensionen werden daher auch „Hypercubes“ genannt.
Die Achsen des Würfels entsprechen den Dimensionen, also den Attributen/ Eigenschaften des Würfels, welche den Würfel aufspannen. Typische Dimensionen sind: Produkt, Ort und Zeit.
Die Zellen im Schnittpunkt der Koordinaten entsprechen den Kennzahlen auch Maßzahlen (engl. „measures“) genannt. Die Kennzahlen stehen im Mittelpunkt der Datenanalyse und können sowohl Basisgrößen (atomare Werte) als auch abgeleitete Zahlen (berechnete Werte) sein. Oftmals handelt es sich bei den Kennzahlen um numerische Werte wie z.B.: Umsatz, Kosten und Gewinn.
Hierarchien beschreiben eine logische Struktur einzelner Elemente in den Dimensionen und nehmen dabei meist ein hierarchisches Schema an z.B.: Tag -> Monat -> Jahr ->TOP. Die Werte der jeweils übergeordneten Elemente ergeben sich meistens aus einer Konsolidierung aller untergeordneten Elemente. Das größte Element „TOP“ steht dabei für „alles“ und fasst somit die gesamten Elemente der Dimension zusammen.

Je nachdem in welcher Detailstufe, auch Granularität genannt, die Kennzahlen der einzelnen Dimensionen vorliegen, können verschiedene Würfel-Operationen für Daten bis auf der kleinsten Ebenen ausgeführt werden wie z.B.: einzelne Transaktionen in einer Geschäftsstellen für einen bestimmten Tag betrachten. Bei der Wahl der Granularität ist jedoch unbedingt der Zweck sowie die Leistungsfähigkeit der Datenbank mit zu Berücksichtigen.
Operationen des OLAP-Würfels
Für die Auswertung von OLAP-Würfeln haben sich spezielle Operationsbezeichnungen durchgesetzt, welche im Folgenden mit grafischen Beispielen vorgestellt werden.
Die Slice Operation wird durch die Selektion bzw. Einschränkung einer Dimension auf ein Dimensionselement erwirkt. In dem hier aufgezeigten Beispiel wird durch das Selektieren auf die Produktsparte „Anzüge“,die entsprechende Scheibe aus dem Würfel „herausgeschnitten“.
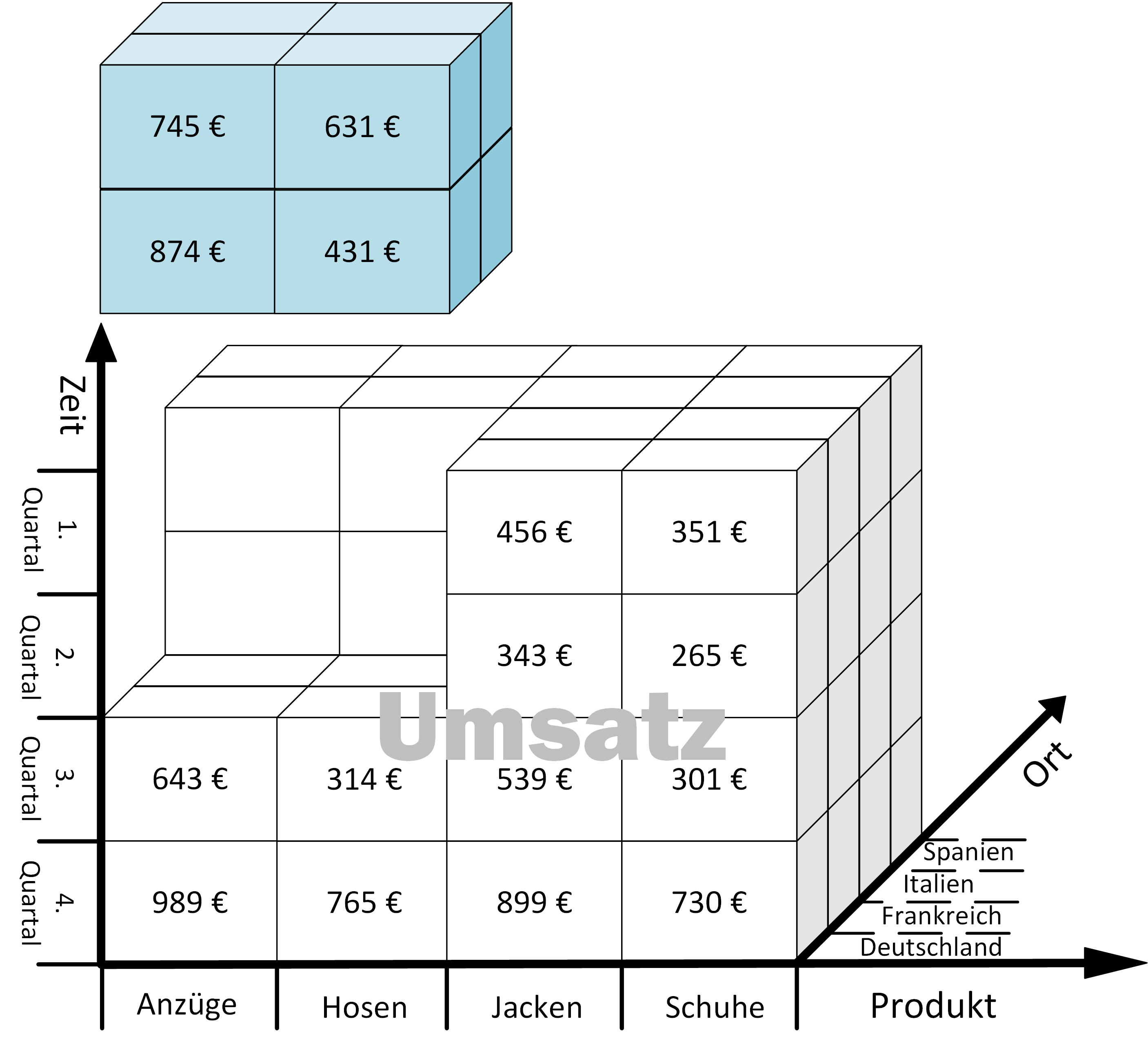
Bei der Dice-Operation wird der Würfel auf mehreren Dimensionen, durch eine Menge von Dimensionselementen eingeschränkt. Als Resultat ergibt sich ein neuer verkleinerter, mehrdimensionaler Datenraum. Das Beispiel zeigt, wie der Würfel auf die Zeit-Dimensionselemente: „Q1 „und „Q2“ sowie die Produkt- Dimensionselemente: „Anzüge“ und „Hosen“ beschränkt wird.
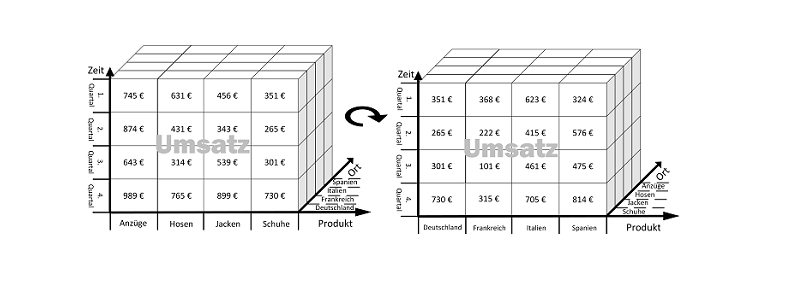
Mit der Pivotiting/Rotation-Operation wird der Würfel um die eigene Achse rotiert. Diese Operation ermöglicht dem Benutzer unterschiedliche Sichten auf die Daten zu erhalten, da neue Kombinationen von Dimensionen sichtbar werden.
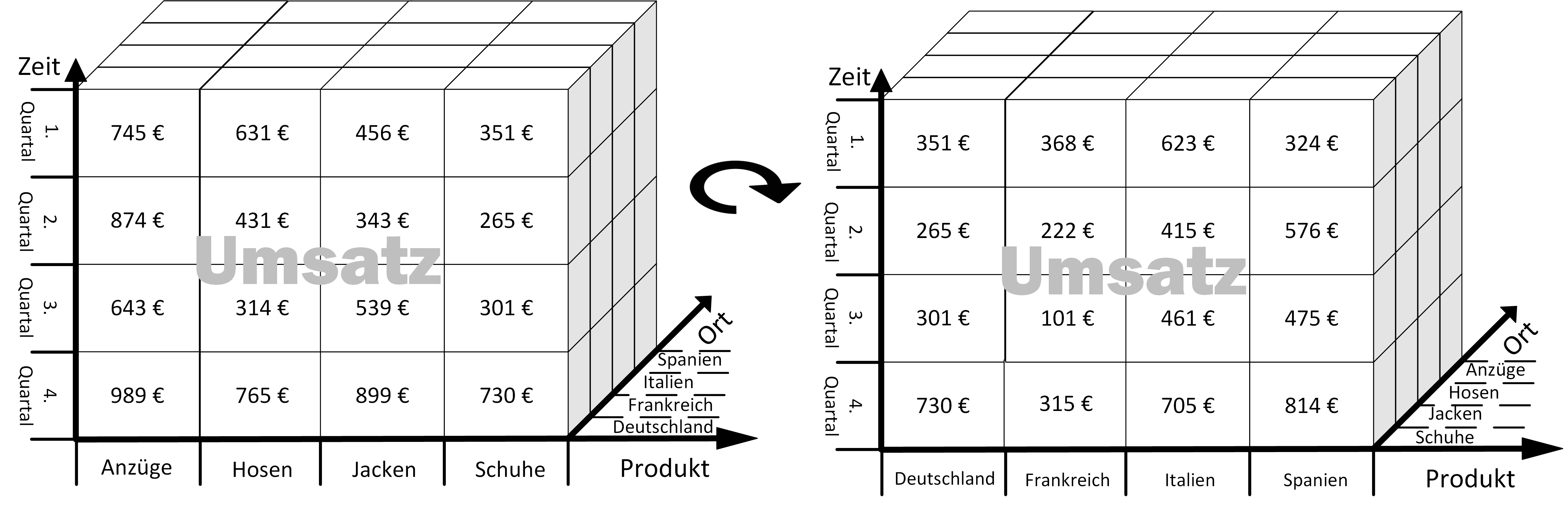
Im abgebildeten Beispiel wird der Datenwürfel nach rechts und um die Zeitachse gedreht. Die dadurch sichtbar gewordene Kombination von Ländern und Zeit ermöglicht dem Benutzer eine neue Sicht auf den Datenwürfel.
Die Operationen: Drill-down oder Drill-up werden benutzt, um durch die Hierarchien der Dimensionen zu navigieren. Je nach Anwendung verdichten sich die Daten bei der Drill-up Operation, während die Drill-down Operation einen höheren Detailgrad ermöglicht.
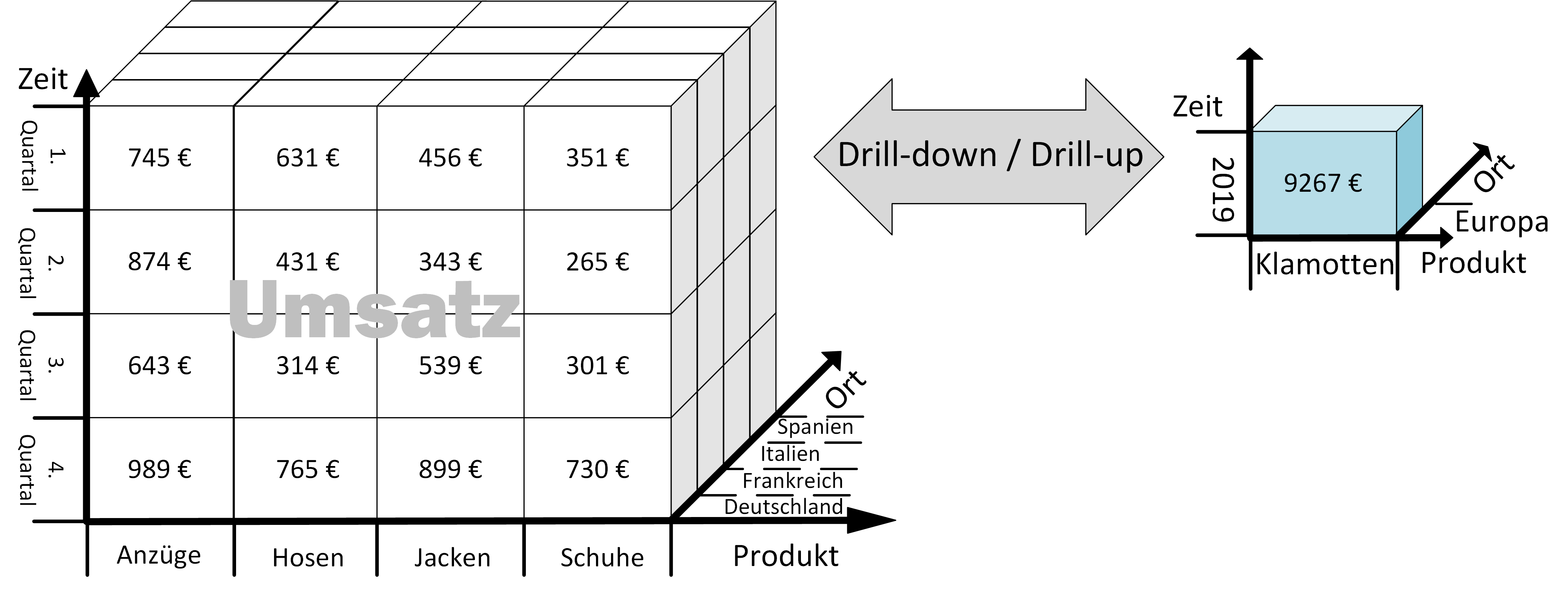
Beispiel werden die Dimensionen auf die jeweils höchste Klassifikationsstufe verdichtet. Das Ergebnis zeigt das TOP-Element der aggregierten Daten, mit einem Wert von 9267 €.
Technische Umsetzung
In den meisten Fällen werden OLAP-Systeme oberhalb des Data Warehouses platziert und nutzen dieses als Datenquelle. Für die Datenspeicherung wird vor allem zwischen den klassischen Konzepten „MOLAP“ und „ROLAP“ unterschieden. Die folgende Gegenüberstellung, zeigt die wesentlichen Unterschiede der beiden Konzepte auf.
ROLAP |
MOLAP |
|
Bedeutung |
Relationales-OLAP | Multidimensionales-OLAP |
Datenspeicherung |
Daten liegen in relationalen Datenbanken vor. | Daten werden in multidimensionalen Datenbanken als Datenwürfel gespeichert |
Daten Form |
Relationale Tabellen | Multidimensionale Arrays |
Datenvolumen |
Hohes Datenvolumen und hohe Nutzerzahl | Mittleres Datenvolum, da Detaildaten in komprimiertem Format vorliegen |
Technologie |
Benötigt Komplexe SQL Abfragen, um Daten zu beziehen | Vorberechneter Datenwürfel hält Aggregationen vor |
Skalierbarkeit |
Beliebig | Eingeschränkt |
Antwortgeschwindigkeit |
Langsam | Schnell |
Fazit
OLAP Würfel können effizient dafür genutzt werden, Informationen in logische Strukturen zu speichern. Die Dimensionierung sowie der Aufbau von logischen Hierarchien, erlauben dem Benutzer ein intuitives Navigieren und Betrachten des Datenbestandes. Durch die Vorberechnung der Aggregationen bei MOLAP-Systemen, können sehr komplexe Analyseabfragen mit hoher Geschwindigkeit und unabhängig von der Datenquelle durchgeführt werden. Für die betriebliche Datenanalyse ist die Nutzung des Datenwürfels insbesondere für fortgeschrittene Datenanalyse, daher eine enorme Bereicherung.






 scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”
scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”