I. Einführung in TensorFlow: Einleitung und Inhalt
1. Einleitung und Inhalt
Früher oder später wird jede Person, welche sich mit den Themen Daten, KI, Machine Learning und Deep Learning auseinander setzt, mit TensorFlow in Kontakt geraten. Für diejenigen wird der Zeitpunkt kommen, an dem sie sich damit befassen möchten/müssen/wollen.
Und genau für euch ist diese Artikelserie ausgelegt. Gemeinsam wollen wir die ersten Schritte in die Welt von Deep Learning und neuronalen Netzen mit TensorFlow wagen und unsere eigenen Beispiele realisieren. Dabei möchten wir uns auf das Wesentlichste konzentrieren und die Thematik Schritt für Schritt in 4 Artikeln angehen, welche wie folgt aufgebaut sind:
- In diesem und damit ersten Artikel wollen wir uns erst einmal darauf konzentrieren, was TensorFlow ist und wofür es genutzt wird.
- Im zweiten Artikel befassen wir uns mit der grundlegenden Handhabung von TensorFlow und gehen den theoretischen Ablauf durch.
- Im dritten Artikel wollen wir dann näher auf die Praxis eingehen und ein Perzeptron – ein einfaches künstliches Neuron – entwickeln. Dabei werden wir die Grundlagen anwenden, die wir im zweiten Artikel erschlossen haben.
Wenn ihr die Praxisbeispiele in den Artikeln 3 & 4 aktiv mit bestreiten wollt, dann ist es vorteilhaft, wenn ihr bereits mit Python gearbeitet habt und die Grundlagen dieser Programmiersprache beherrscht. Jedoch werden alle Handlungen und alle Zeilen sehr genau kommentiert, so dass es leicht verständlich bleibt.
Neben den Programmierfähigkeiten ist es hilfreich, wenn ihr euch mit der Funktionsweise von neuronalen Netzen auskennt, da wir im späteren Verlauf diese modellieren wollen. Jedoch gehen wir vor der Programmierung kurz auf die Theorie ein und werden das Wichtigste nochmal erwähnen.
Zu guter Letzt benötigen wir für unseren Theorie-Teil ein Mindestmaß an Mathematik um die Grundlagen der neuronalen Netze zu verstehen. Aber auch hier sind die Anforderungen nicht hoch und wir sind vollkommen gut damit bedient, wenn wir unser Wissen aus dem Abitur noch nicht ganz vergessen haben.
2. Ziele dieser Artikelserie
Diese Artikelserie ist speziell an Personen gerichtet, welche einen ersten Schritt in die große und interessante Welt von Deep Learning wagen möchten, die am Anfang nicht mit zu vielen Details überschüttet werden wollen und lieber an kleine und verdaulichen Häppchen testen wollen, ob dies das Richtige für sie ist. Unser Ziel wird sein, dass wir ein Grundverständnis für TensorFlow entwickeln und die Grundlagen zur Nutzung beherrschen, um mit diesen erste Modelle zu erstellen.
3. Was ist TensorFlow?
Viele von euch haben bestimmt von TensorFlow in Verbindung mit Deep Learning bzw. neuronalen Netzen gehört. Allgemein betrachtet ist TensorFlow ein Software-Framework zur numerischen Berechnung von Datenflussgraphen mit dem Fokus maschinelle Lernalgorithmen zu beschreiben. Kurz gesagt: Es ist ein Tool um Deep Learning Modelle zu realisieren.
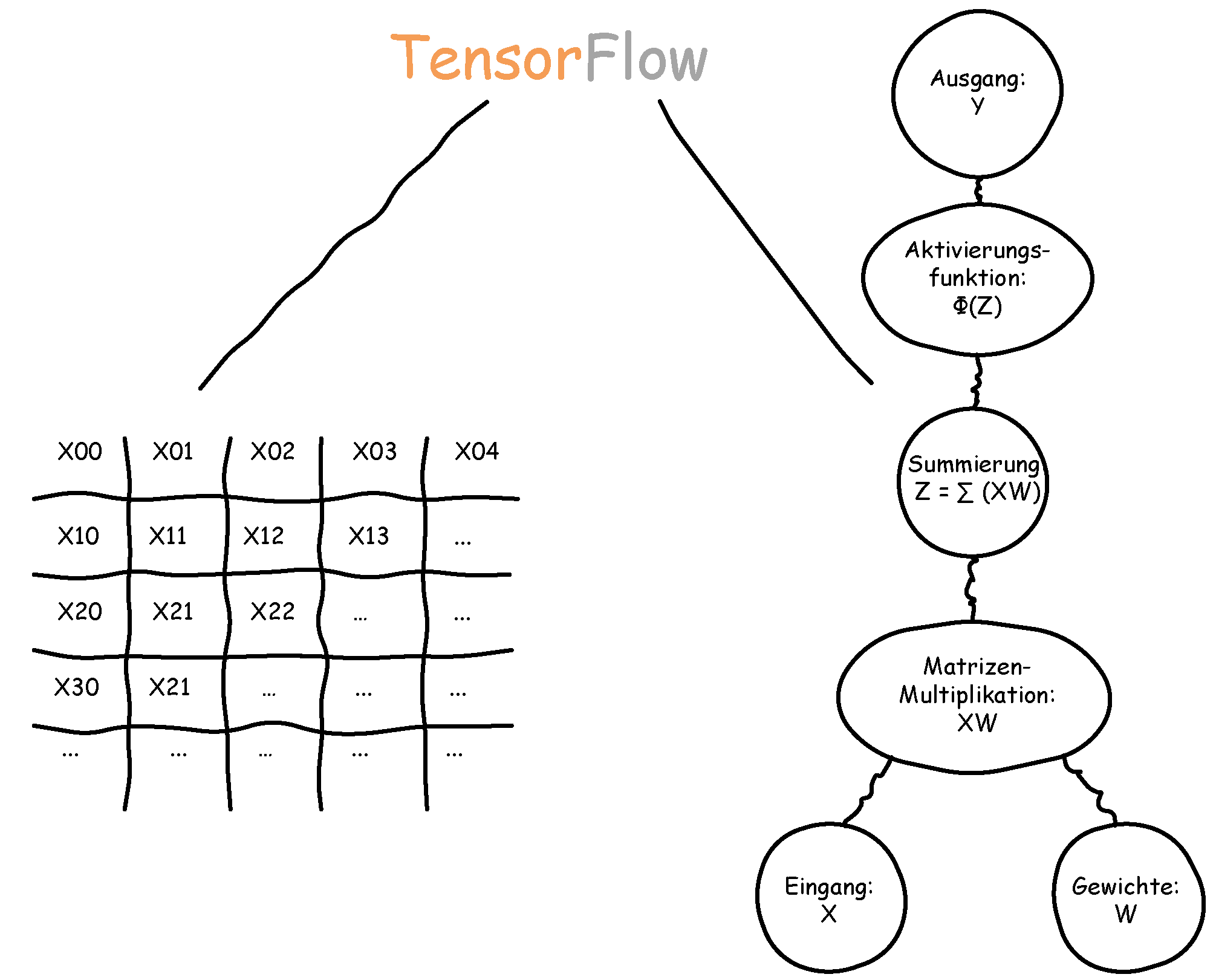
Zusatz: Python ist eine Programmiersprache in der wir viele Paradigmen (objektorientiert, funktional, etc.) verwenden können. Viele Tutorials im Bereich Data Science nutzen das imperative Paradigma; wir befehlen Python also Was gemacht und Wie es ausgeführt werden soll. TensorFlow ist dahingehend anders, da es eine datenstrom-orientierte Programmierung nutzt. In dieser Form der Programmierung wird ein Datenfluss-Berechnungsgraph (kurz: Datenflussgraph) erzeugt, welcher durch die Zusammensetzung von Kanten und Knoten charakterisiert wird. Die Kanten enthalten Daten und können diese an Knoten weiterleiten. In den Knoten werden Operationen wie z. B. Addition, Multiplikation oder auch verschiedenste Variationen von Funktionen ausgeführt. Bekannte Programme mit datenstrom-orientierten Paradigmen sind Simulink, LabView oder Knime.
Für das Verständnis von TensorFlow verrät uns der Name bereits erste Informationen über die Funktionsweise. In neuronalen Netzen bzw. in Deep-Learning-Netzen können Eingangssignale, Gewichte oder Bias verschiedene Erscheinungsformen haben; von Skalaren, zweidimensionalen Tabellen bis hin zu mehrdimensionalen Matrizen kann alles dabei sein. Diese Erscheinungsformen werden in Deep-Learning-Anwendungen allgemein als Tensoren bezeichnet, welche durch ein Datenflussgraph ‘fließen’. [1]
4. Warum TensorFlow?
Wer in die Welt der KI einsteigen und Deep Learning lernen will, hat heutzutage die Qual der Wahl. Neben TensorFlow gibt es eine Vielzahl von Alternativen wie Keras, Theano, Pytorch, Torch, Caffe, Caffe2, Mxnet und vielen anderen. Warum also TensorFlow?
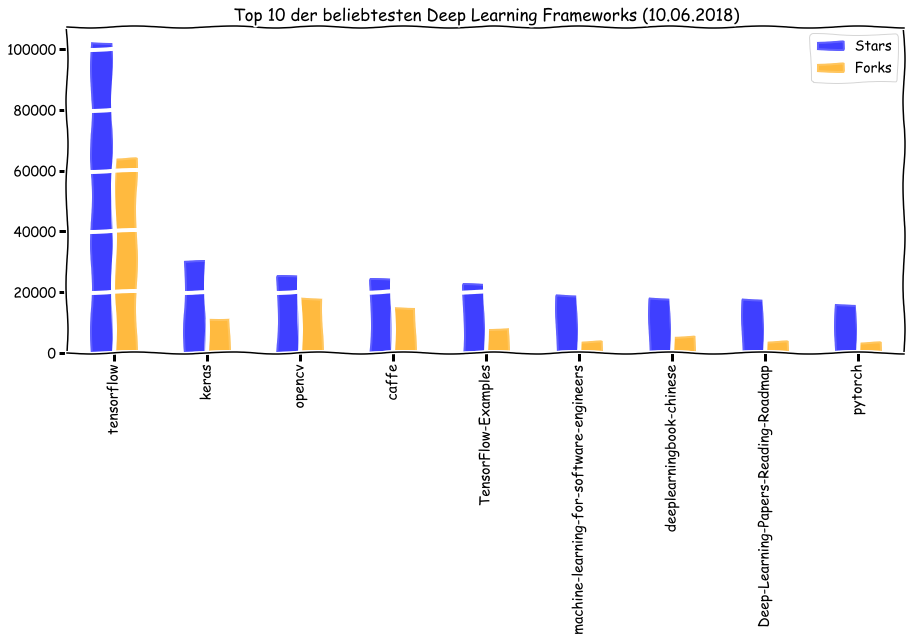
Das wohl wichtigste Argument besteht darin, dass TensorFlow eine der besten Dokumentationen hat. Google – Herausgeber von TensorFlow – hat TensorFlow stets mit neuen Updates beliefert. Sicherlich aus genau diesen Gründen ist es das meistgenutzte Framework. Zumindest erscheint es so, wenn wir die Stars&Forks auf Github betrachten. [3] Das hat zur Folge, dass neben der offiziellen Dokumentation auch viele Tutorials und Bücher existieren, was die Doku nur noch besser macht.
Natürlich haben alle Frameworks ihre Vor- und Nachteile. Gerade Pytorch von Facebook erfreut sich derzeit großer Beliebtheit, da die Berechnungsgraphen dynamischer Natur sind und damit einige Vorteile gegenüber TensorFlow aufweisen.[2] Auch Keras wäre für den Einstieg eine gute Alternative, da diese Bibliothek großen Wert auf eine einsteiger- und nutzerfreundliche Handhabung legt. Keras kann man sich als eine Art Bedienoberfläche über unsere Frameworks vorstellen, welche vorgefertigte neuronale Netze bereitstellt und uns einen Großteil der Arbeit abnimmt.
Möchte man jedoch ein detailreiches und individuelles Modell bauen und die Theorie dahinter nachvollziehen können, dann ist TensorFlow der beste Einstieg in Deep Learning! Es wird einige Schwierigkeiten bei der Gestaltung unserer Modelle geben, aber durch die gute Dokumentation, der großen Community und der Vielzahl an Beispielen, werden wir gewiss eine Lösung für aufkommende Problemstellungen finden.
5. Zusammenfassung und Ausblick
Fassen wir das Ganze nochmal zusammen: TensorFlow ist ein Framework, welches auf der datenstrom-orientierten Programmierung basiert und speziell für die Implementierung von Machine/Deep Learning-Anwendungen ausgelegt ist. Dabei fließen unsere Daten durch eine mehr oder weniger komplexe Anordnung von Berechnungen, welche uns am Ende ein Ergebnis liefert.
Die wichtigsten Argumente zur Wahl von TensorFlow als Einstieg in die Welt des Deep Learnings bestehen darin, dass TensorFlow ausgezeichnet dokumentiert ist, eine große Community besitzt und relativ einfach zu lesen ist. Außerdem hat es eine Schnittstelle zu Python, welches durch die meisten Anwender im Bereich der Datenanalyse bereits genutzt wird.
Wenn ihr es bis hier hin geschafft habt und immer noch motiviert seid den Einstieg mit TensorFlow zu wagen, dann seid gespannt auf den nächsten Artikel. In diesem werden wir dann auf die Funktionsweise von TensorFlow eingehen und einfache Berechnungsgraphen aufbauen, um ein Grundverständnis von TensorFlow zu bekommen. Bleibt also gespannt!
Quellen
[1] Hope, Tom (2018): Einführung in TensorFlow: DEEP-LEARNING-SYSTEME PROGRAMMIEREN, TRAINIEREN, SKALIEREN UND DEPLOYEN, 1. Auflage
[2] https://www.marutitech.com/top-8-deep-learning-frameworks/
[3] https://github.com/mbadry1/Top-Deep-Learning
[4] https://www.bigdata-insider.de/was-ist-keras-a-726546/
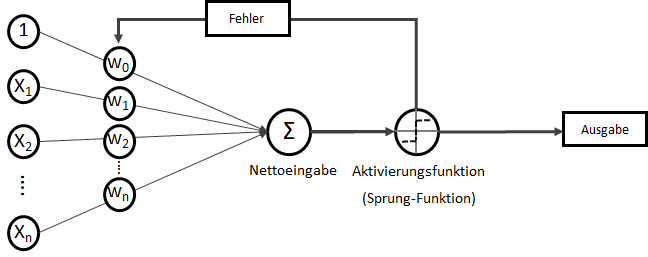
 . Wobei für
. Wobei für  als Bias-Input stets gilt:
als Bias-Input stets gilt:  . Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.
. Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.![\[ x = \begin{bmatrix} x_0\\ x_1\\ x_2\\ x_3\\ \vdots\\ x_n \end{bmatrix} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3a7aa03dea498a7231e3e497e3e5673d_l3.svg "Rendered by QuickLaTeX.com")

![\[ w = \begin{bmatrix} w_0\\ w_1\\ w_2\\ w_3\\ \vdots\\ w_n \end{bmatrix} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-c70ad1733451ddc4512b23f2c739f80e_l3.svg "Rendered by QuickLaTeX.com")
 bilden. Hier zeigt sich
bilden. Hier zeigt sich  mit
mit  als Y-Achsenschnitt wenn
als Y-Achsenschnitt wenn  .
.![\[ z = w_0 \cdot x_0 + w_1 \cdot x_1 + \dots + w_n \cdot x_n \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3638f2ae3b558db6c95e18057b1b9898_l3.svg "Rendered by QuickLaTeX.com")
 überschreitet, liefert die Sprungfunktion
überschreitet, liefert die Sprungfunktion  mit der Eingabe
mit der Eingabe 
 .
.![\[ z = w^T \cdot x \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-fc9f71e279d7fd0095c17065743df909_l3.svg "Rendered by QuickLaTeX.com")
 steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt.
steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt. und
und  mit beispielhaften Inhalten:
mit beispielhaften Inhalten:![\[ x = \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-97145f06e658d2f10086bd8c80293749_l3.svg "Rendered by QuickLaTeX.com")
![\[ w = \begin{bmatrix} 1\\ 2\\ 5\\ 12 \end{bmatrix} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-6cd08615346cc16d7e8c23bac32c19b9_l3.svg "Rendered by QuickLaTeX.com")
![\[ z = w^T \cdot x = \big[1\text{ }2\text{ }5\text{ }12\big] \cdot \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} = 1 \cdot 5 + 2 \cdot 12 + 5 \cdot 30 + 12 \cdot 2 = 203 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-70a3e9e9243199e97c549d1d9b0f44c0_l3.svg "Rendered by QuickLaTeX.com")

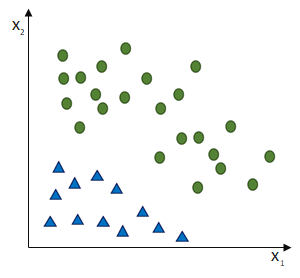



 entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
 blenden wir hier einfach mal aus. Bitte einfach von
blenden wir hier einfach mal aus. Bitte einfach von  ausgehen.
ausgehen.







 ist und das SLP irrtümlicherweise die Klasse
ist und das SLP irrtümlicherweise die Klasse  ausgewiesen hat, obwohl die korrekte Klasse
ausgewiesen hat, obwohl die korrekte Klasse  wäre. (Und die Schrittweite lassen wir bei
wäre. (Und die Schrittweite lassen wir bei  )
)
 verringert sich entsprechend
verringert sich entsprechend  und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration (
und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration ( ) wieder die Klasse +1 korrekt sei, den Schwellwert
) wieder die Klasse +1 korrekt sei, den Schwellwert  zu unterschreiten und auf eben diese korrekte Klasse zu stoßen.
zu unterschreiten und auf eben diese korrekte Klasse zu stoßen. . So würde beispielsweise ein neues
. So würde beispielsweise ein neues  (bei Iteration
(bei Iteration  ) zu einer irrtümlichen Klassifikation
) zu einer irrtümlichen Klassifikation  (
( ) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf (
) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf ( ) an
) an 
 und
und 
 funktioniert.
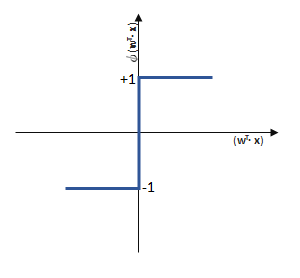
funktioniert. springt, wenn z > 0 ist, ansonsten aber
springt, wenn z > 0 ist, ansonsten aber  bleibt.
bleibt.
 ,
,
 ,
,
 ,
,
 ,
, ,
, ,
,

 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit  und somit
und somit  und somit
und somit 



 Alice Albrecht ist Research Engineer bei
Alice Albrecht ist Research Engineer bei 







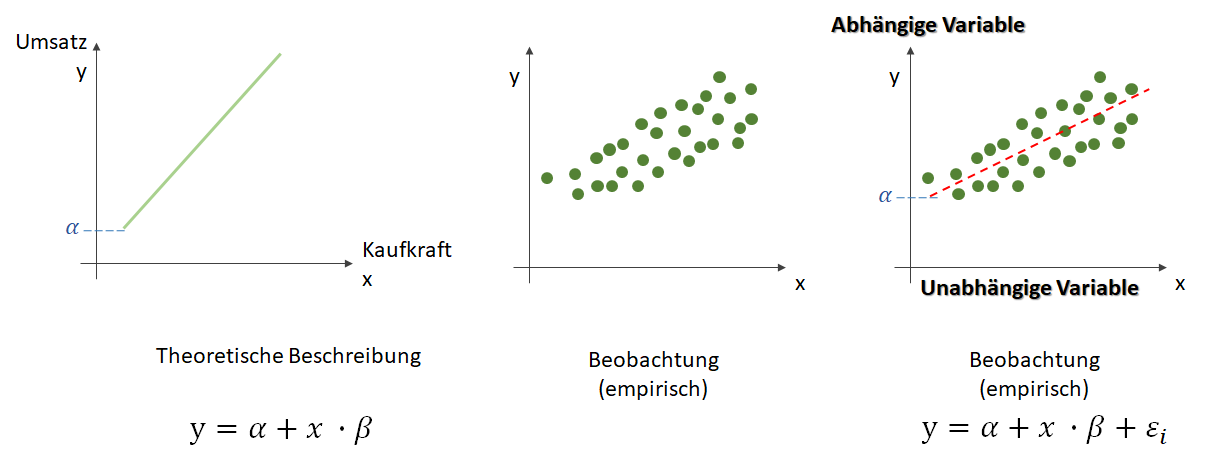
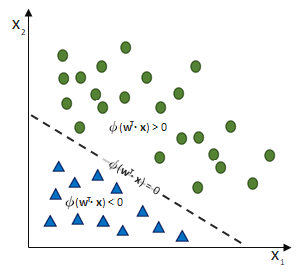
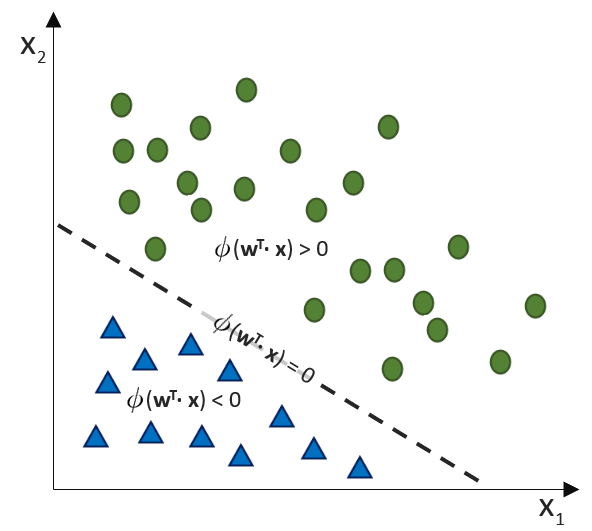
 , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  (Alpha) ist der
(Alpha) ist der  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung. ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.svg "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.svg "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.svg "Rendered by QuickLaTeX.com")
 .
.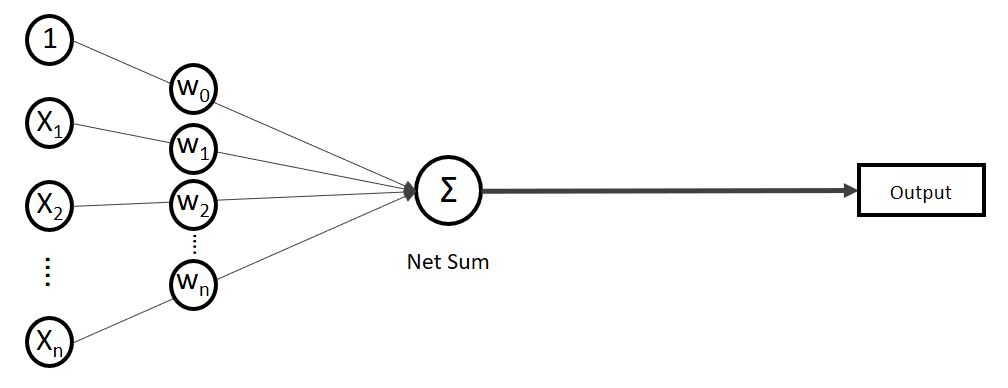
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
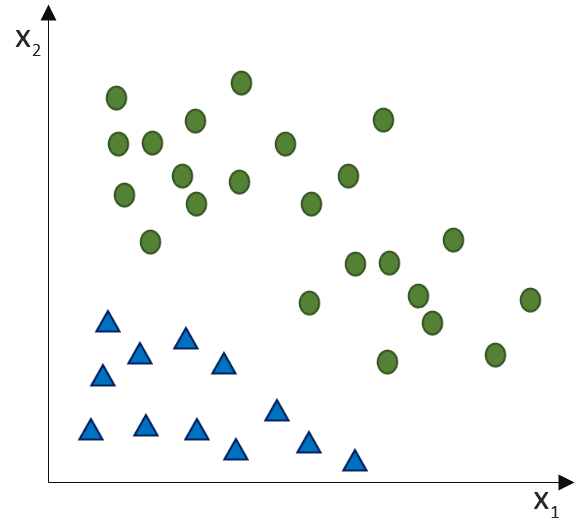
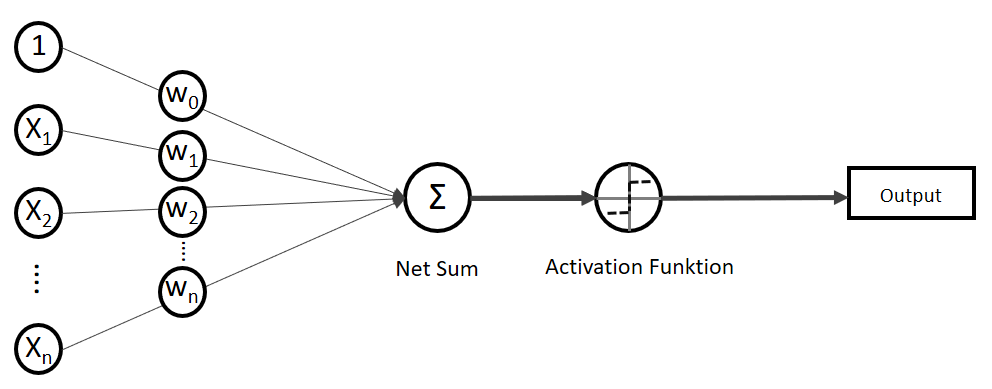
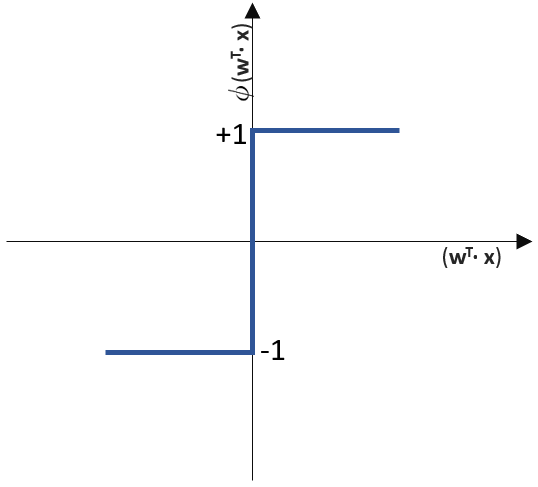
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.svg "Rendered by QuickLaTeX.com")