Eine Hadoop Architektur mit Enterprise Sicherheitsniveau
Dies ist Teil 3 von 3 der Artikelserie zum Thema Eine Hadoop-Architektur mit Enterprise Sicherheitsniveau.
Die ideale Lösung
Man denkt, dass die Integration einer sehr alten Technologie, wie ActiveDirectory oder LDAP zusammen mit einem etablierten und ausgereiften Framework wie Hadoop reibungslos funktionieren würde. Leider sind solche Annahmen in der IT Welt zu gut um wahr zu sein. Zum Glück gibt es bereits erste Erfahrungsberichte von Unternehmen, die ihre Hadoop Infrastruktur an ein zentrales IMS gekoppelt haben.
Da die meisten Unternehmen Active Directory als IMS benutzen, werden die im Folgenden dargestellte Bilder und Architekturen dies ebenfalls tun. Die vorgeschlagene Architektur ist jedoch derartig flexibel und technologieunabhängig, dass man das Active Directory auf den Bildern problemlos gegen LDAP austauschen könnte. Vielmehr ist die Integration eines Hadoop Clusters mit LDAP einfacher, da beide Technologien nativ zu Linux sind.
Schritt Eins – Integration von Hadoop mit Active Directory
Der erste Schritt, um Hadoop in dasActive Directory zu integrieren, ist ein sogenannter One-Way Trust von der Linux Welt hin zur Windows Welt . Dabei ist das Vertrauen des Authentisierungsmechanismuses von Hadoop zum Active Directory gemeint. Alle Identity Management Systeme bieten diese Funktionalität an, um sich gegenseitig vertrauen zu können und User aus anderen Domänen (Realms) zu akzeptieren. Das ermöglicht z.B. globalen Firmen mit vielen Standorten und unterschiedlichen IT Infrastrukturen und Identity Management Systemen diese zu verwalten und miteinander kommunizieren zu lassen.
Das Key Distribution Center (KDC) von Kerberos ist das Herz des Kerberos Systems im Hadoop. Hier werden die User und ihre Passwörter oder Keytabs geschützt und verwaltet. Dabei brauchen wir lediglich den One Way Trust von KDC zu Active Directory. Allerdings gibt es eine vielversprechendere Technologie, die FreeIPA. Diese hat laut Wikipedia das Ziel, ein einfach zu verwaltendes Identity,-Policy-and-Audit-System (IPA) zur Verfügung zu stellen. Seit der Version 3.0.0 kann sich FreeIPA in das Active Directory integrieren. Die aussagekräftigen Vorteile von FreeIPA sind folgende:
- Reibungslose Integration mit Active Directory
- Es wird zusammen mit der Technologie SSSD geliefert, die das temporäre Speichern von Rechten und Passwörtern erlaubt. Das erlaubt auch offline den Zugriff auf Fähigkeiten und Unabhängigkeit vom zentralen IPA, dem unterliegenden System.
- Integrierte Kerberos und Single Sign On (SSO) Funktionalitäten.
Wir lassen dann FreeIPA die Verwaltung von Kerberos und die primäre Authentisierung unseres Clusters übernehmen. Sowohl das Active Directory, als auch FreeIPA erlauben eine kinderleichte Umsetzung des One Way Trusts mithilfe von Web Tools. Im Prinzip muss man beim One Way Trust lediglich die öffentlichen Zertifikate jedes Tools mit denen der anderen bekannt machen.
Schritt Zwei – Synchronisation der Rechte & Rollen von Active Directory
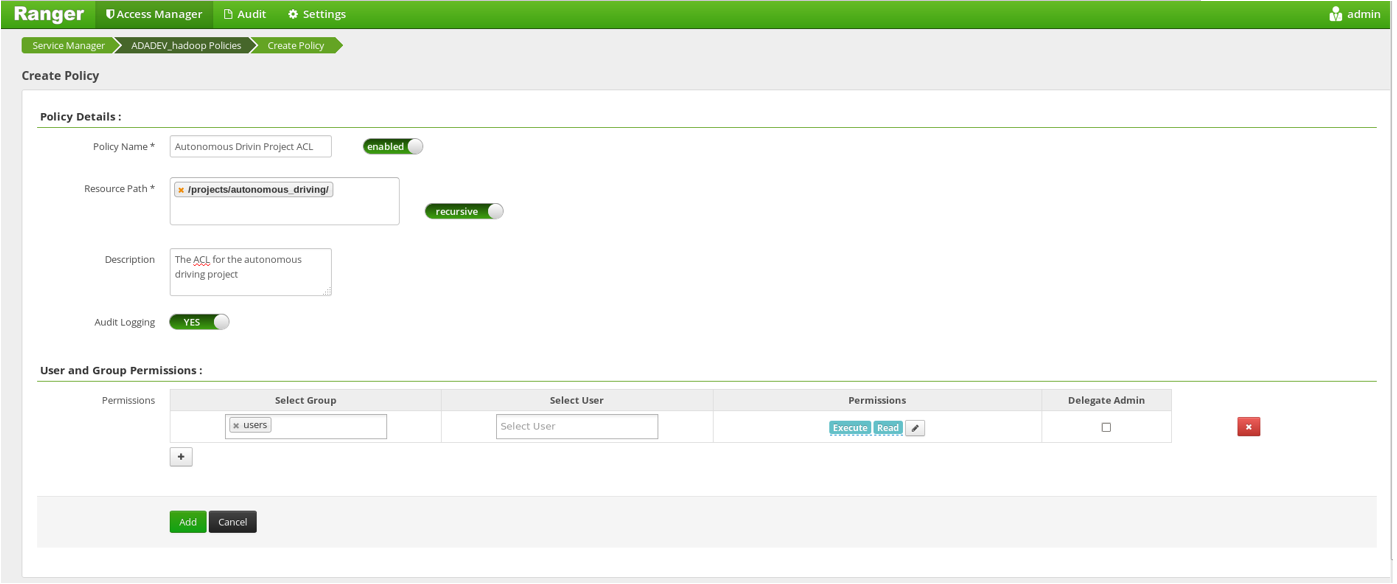
Jetzt sind alle User, die sich im Active Directory befinden, unserem Hadoop Cluster bekannt. Ein User kann sich mithilfe des kinit Kommandos und nach Eingabe seines Usernames und Passwortes einloggen. Aber man braucht auch die im Active Directory definierten Rollen und Gruppen, um eine Autorisierung mithilfe von Ranger oder Sentry zu ermöglichen. Ohne die Provisionierung der Rollen haben wir bei der Autorisierung ein ähnliches Problem, wie es bei der Authentisierung aufgetreten ist. Man müsste die Rollen selber verwalten, was nicht ideal ist.
Zum Glück gibt es verschiedene Ansätze um eine regelforme Synchronisierung der Gruppen von Active Directory in Ranger oder Sentry zu implementieren. Ranger kommt mit einem LDAP Plugin namens uxugsync, das sowohl mit LDAP als auch mit dem Active Directory kommunizieren kann. Leider hat die aktuelle Version dieses Plugins einige Nachteile:
- Leistungsprobleme, weil es defaultsmäßig versucht, den ganzen Hierarchiebaum von Active Directory zu synchronisieren. Das kann zu einem großen Problem für große Firmen werden, die mehrere tausend User haben. Außerdem müssen nicht alle User Zugriff auf Hadoop haben.
- Man kann bestimmte User syncen lassen, indem man ihren Gruppename im Gruppenfeld vom Plugin einträgt. Nachteil dabei ist, dass diese Abfrage nicht rekursiv funktioniert und alle Gruppe die im Ranger sein sollen einzeln abgefragt werden müssen, Das wiederum skaliert nicht sonderlich gut.
- Massive und regelmäßige Abfragen des Plugins können sogar zu einem DDoS Angriff auf den zentralen Active Directory führen.
Eine bessere Lösung wäre es, wenn wir die schönen Features des SSSD Deamons (der wie oben beschrieben zusammen mit FreeIPA kommt) ausnutzen könnten. Mithilfe von SSSD werden alle User und ihre entsprechenden Gruppen dem unterliegenden Linux Betriebssystem bekannt gemacht. Das bedeutet, dass man ein einfaches Script schreiben könnte, das die User und ihre Gruppen vom System direkt abfragt und zu Ranger oder Sentry über ihre entsprechende REST APIs überträgt. Dabei schont man sowohl das Active Directory vor regelmäßigen und aufwändigen Abfragen und schafft sogar ein schnelleres Mapping der Rollen zwischen Hadoop und Betriebssystem, auch wenn Active Directory nicht erreichbar ist. Es gibt derzeit Pläne, ein solches Plugin in den nächsten Versionen von Ranger mitzuliefern.
Schritt Drei – Anlegen und Verwaltung von technischen Usern
Unser System hat jedoch neben personalisierten Usern, die echten Personen in einem Unternehmen entsprechen, auch technische User. Die technischen Users (Nicht Personalisierte Accounts – NPA), sind die Linux User mit denen die Hadoop Dienste gestartet werden. Dabei hat HDFS, Ambari usw. jeweils seinen eigenen User mit demselben Namen. Rein theoretisch könnten diese User auch im Active Directory einen Platz finden.
Meiner Meinung nach gehören diese User aber nicht dorthin. Erstens, weil sie keine echten User sind und zweitens, weil die Verwaltung solcher User nach Upgrades oder Neuinstallation des Clusters schwierig sein kann. Außerdem müssen solche User nicht den gleichen Sicherheitspolicies unterliegen, wie die normalen User. Am besten sollten sie kein Passwort besetzen, sondern lediglich ein Kerberos Keytab, das sich nach jedem Upgrade oder Neuinstallierung des Clusters neu generiert und in FreeIPA angelegt ist. Deswegen neige ich eher dazu, die NPAs in IPA anzulegen und zu verwalten.
High Level Architektur
Das folgende Bild fasst die Architektur zusammen. Hadoop Dienste, die üblicherweise in einer explorativen Umgebung benutzt werden, wie Hive und HBase, werden mit dargestellt. Es ist wichtig zu beachten, dass jegliche Technologie, die ein Ausführungsengine für YARN anbietet, wie Spark oder Storm, von dieser Architektur ebenfalls profitiert. Da solche Technologien nicht direkt mit den unterliegenden Daten interagieren, sondern diese immer über YARN und die entsprechenden Datanodes erhalten, benötigen sie auch keine besondere Darstellung oder Behandlung. Der Datenzugriff aus diesen 3rd Party Technologien respektiert die im Ranger definierten ACLs und Rollen des jeweiligen Users, der sie angestoßen hat.

Architektur in einer Mehrclusterumgebung
Wir haben schon das Argument untermauert, warum unsere technischen User direkt im IPA liegen sollten. Das kann jedoch insofern Probleme verursachen, wenn man mit mehreren Clustern arbeitet, die alle die gleichen Namen für ihre technischen User haben. Man merkt sofort, dass es sich hier um eine Namenskollision handelt. Es gibt zwei Lösungsansätze hierfür:
- Man fügt den Namen Präfixen, die als kurze Beschreibungen der jeweiligen Umgebung dienen, wie z.B. ada, proj1, proj2 hinzu. Dadurch haben die User unterschiedliche Namen, wie proj1_hdfs für die proj1 Umgebung und ada_hdfs für die ada Umgebung. Man kann diese Lösung auch bei Kerberos KDCs benutzen, die in jeder Umgebung dediziert sind und die technischen User der jeweiligen Umgebung beibehalten.
- Man benutzt einen separaten Realm für jede Umgebung und damit auch eine separate IPA Instanz. Hier gibt es wiederum zwei verschiedene Ansätze. Ich muss jedoch zugeben, dass ich die Zweite nie ausprobiert habe und daher für ihre Durchführbarkeit nicht garantieren kann:
- Man bindet jede Umgebung einzeln über ihre FreeIPA per One Way Trust an das zentrale Active Directory. Das hat natürlich den Nachteil einer uneinheitlichen User Management Infrastruktur für alle Umgebungen, da Jede ihre eigene IPA Infrastruktur verwaltet und wartet.
- Man baut einen Hierarchiebaum von unterschiedlichen IPA Instanzen, so wie man es bei Forests von Active Directory Instanzen macht.
Das folgende Bild stellt den letzten Ansatz dar. Im Prinzip haben wir hier einen hierarchischen IPA Cluster mit mehreren One Way Trusts von den lokalen IPA Instanzen zu der zentralen IPA.

Zusammenfassung
Wie Sie vielleicht von der gesamten Diskussion her abgeleitet haben, ist die Umsetzung einer unternehmerisch-konformen und personenbasierten Sicherheitsarchitektur innerhalb von Hadoop keine einfache Sache. Man muss mit unterschiedlichen Architekturen und Ansätzen spielen, bevor man einen relativ vernünftigen oder sogar idealen Zustand erreicht hat. Die Berücksichtigung der jeweiligen IT Architektur spielt dabei eine sehr große Rolle. Ich hoffe, ich konnte die wichtigsten Merkmalen einer solchen Architektur und die Punkte, die ein Architekt besonders beachten muss, klar darstellen.
Als Zusammenfassung habe ich Ihnen am Ende eine Art Shoppingliste aller Komponenten zusammengestellt, die wichtig für den personalisierten Zugriff im Hadoop sind:
- Kerberos – Authentisierung
- FreeIPA – Authentisierung, Integration mit Active Directory
- Active Directory oder LDAP
- Ranger oder Sentry
- Plugin für Rollen/Gruppen Mapping zwischen AD und dem Betriebssystem
- Optional SSSD für schnellere Abfrage der Gruppen und Rollen des Betriebssystems