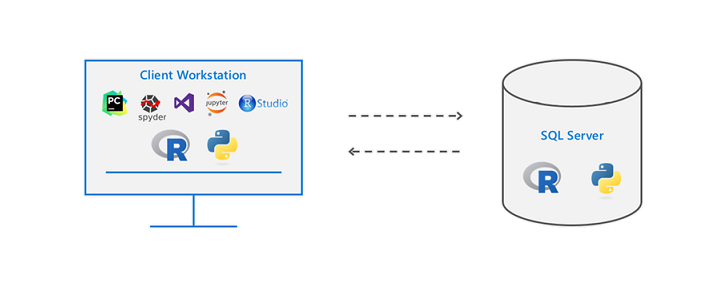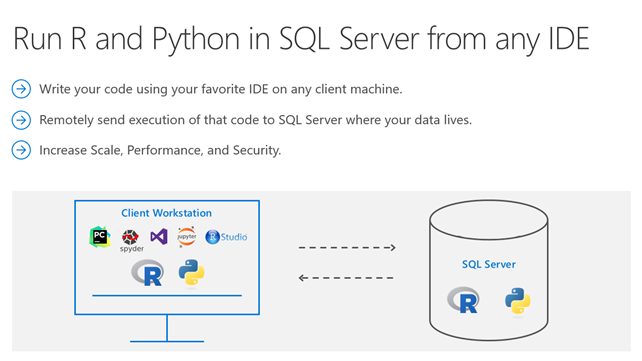
Sechs Eigenschaften einer modernen Business Intelligence
Völlig unabhängig von der Branche, in der Sie tätig sind, benötigen Sie Informationssysteme, die Ihre geschäftlichen Daten auswerten, um Ihnen Entscheidungsgrundlagen zu liefern. Diese Systeme werden gemeinläufig als sogenannte Business Intelligence (BI) bezeichnet. Tatsächlich leiden die meisten BI-Systeme an Mängeln, die abstellbar sind. Darüber hinaus kann moderne BI Entscheidungen teilweise automatisieren und umfassende Analysen bei hoher Flexibilität in der Nutzung ermöglichen.
![]() Read this article in English:
Read this article in English:
“Six properties of modern Business Intelligence”
Lassen Sie uns die sechs Eigenschaften besprechen, die moderne Business Intelligence auszeichnet, die Berücksichtigungen von technischen Kniffen im Detail bedeuten, jedoch immer im Kontext einer großen Vision für die eigene Unternehmen-BI stehen:
1. Einheitliche Datenbasis von hoher Qualität (Single Source of Truth)
Sicherlich kennt jeder Geschäftsführer die Situation, dass sich seine Manager nicht einig sind, wie viele Kosten und Umsätze tatsächlich im Detail entstehen und wie die Margen pro Kategorie genau aussehen. Und wenn doch, stehen diese Information oft erst Monate zu spät zur Verfügung.
In jedem Unternehmen sind täglich hunderte oder gar tausende Entscheidungen auf operative Ebene zu treffen, die bei guter Informationslage in der Masse sehr viel fundierter getroffen werden können und somit Umsätze steigern und Kosten sparen. Demgegenüber stehen jedoch viele Quellsysteme aus der unternehmensinternen IT-Systemlandschaft sowie weitere externe Datenquellen. Die Informationsbeschaffung und -konsolidierung nimmt oft ganze Mitarbeitergruppen in Anspruch und bietet viel Raum für menschliche Fehler.
Ein System, das zumindest die relevantesten Daten zur Geschäftssteuerung zur richtigen Zeit in guter Qualität in einer Trusted Data Zone als Single Source of Truth (SPOT) zur Verfügung stellt. SPOT ist das Kernstück moderner Business Intelligence.
Darüber hinaus dürfen auch weitere Daten über die BI verfügbar gemacht werden, die z. B. für qualifizierte Analysen und Data Scientists nützlich sein können. Die besonders vertrauenswürdige Zone ist jedoch für alle Entscheider diejenige, über die sich alle Entscheider unternehmensweit synchronisieren können.
2. Flexible Nutzung durch unterschiedliche Stakeholder
Auch wenn alle Mitarbeiter unternehmensweit auf zentrale, vertrauenswürdige Daten zugreifen können sollen, schließt das bei einer cleveren Architektur nicht aus, dass sowohl jede Abteilung ihre eigenen Sichten auf diese Daten erhält, als auch, dass sogar jeder einzelne, hierfür qualifizierte Mitarbeiter seine eigene Sicht auf Daten erhalten und sich diese sogar selbst erstellen kann.
Viele BI-Systeme scheitern an der unternehmensweiten Akzeptanz, da bestimmte Abteilungen oder fachlich-definierte Mitarbeitergruppen aus der BI weitgehend ausgeschlossen werden.
Moderne BI-Systeme ermöglichen Sichten und die dafür notwendige Datenintegration für alle Stakeholder im Unternehmen, die auf Informationen angewiesen sind und profitieren gleichermaßen von dem SPOT-Ansatz.
3. Effiziente Möglichkeiten zur Erweiterung (Time to Market)
Bei den Kernbenutzern eines BI-Systems stellt sich die Unzufriedenheit vor allem dann ein, wenn der Ausbau oder auch die teilweise Neugestaltung des Informationssystems einen langen Atem voraussetzt. Historisch gewachsene, falsch ausgelegte und nicht besonders wandlungsfähige BI-Systeme beschäftigen nicht selten eine ganze Mannschaft an IT-Mitarbeitern und Tickets mit Anfragen zu Änderungswünschen.
Gute BI versteht sich als Service für die Stakeholder mit kurzer Time to Market. Die richtige Ausgestaltung, Auswahl von Software und der Implementierung von Datenflüssen/-modellen sorgt für wesentlich kürzere Entwicklungs- und Implementierungszeiten für Verbesserungen und neue Features.
Des Weiteren ist nicht nur die Technik, sondern auch die Wahl der Organisationsform entscheidend, inklusive der Ausgestaltung der Rollen und Verantwortlichkeiten – von der technischen Systemanbindung über die Datenbereitstellung und -aufbereitung bis zur Analyse und dem Support für die Endbenutzer.
4. Integrierte Fähigkeiten für Data Science und AI
Business Intelligence und Data Science werden oftmals als getrennt voneinander betrachtet und geführt. Zum einen, weil Data Scientists vielfach nur ungern mit – aus ihrer Sicht – langweiligen Datenmodellen und vorbereiteten Daten arbeiten möchten. Und zum anderen, weil die BI in der Regel bereits als traditionelles System im Unternehmen etabliert ist, trotz der vielen Kinderkrankheiten, die BI noch heute hat.
Data Science, häufig auch als Advanced Analytics bezeichnet, befasst sich mit dem tiefen Eintauchen in Daten über explorative Statistik und Methoden des Data Mining (unüberwachtes maschinelles Lernen) sowie mit Predictive Analytics (überwachtes maschinelles Lernen). Deep Learning ist ein Teilbereich des maschinellen Lernens (Machine Learning) und wird ebenfalls für Data Mining oder Predictvie Analytics angewendet. Bei Machine Learning handelt es sich um einen Teilbereich der Artificial Intelligence (AI).
In der Zukunft werden BI und Data Science bzw. AI weiter zusammenwachsen, denn spätestens nach der Inbetriebnahme fließen die Prädiktionsergebnisse und auch deren Modelle wieder in die Business Intelligence zurück. Vermutlich wird sich die BI zur ABI (Artificial Business Intelligence) weiterentwickeln. Jedoch schon heute setzen viele Unternehmen Data Mining und Predictive Analytics im Unternehmen ein und setzen dabei auf einheitliche oder unterschiedliche Plattformen mit oder ohne Integration zur BI.
Moderne BI-Systeme bieten dabei auch Data Scientists eine Plattform, um auf qualitativ hochwertige sowie auf granularere Rohdaten zugreifen zu können.
5. Ausreichend hohe Performance
Vermutlich werden die meisten Leser dieser sechs Punkte schon einmal Erfahrung mit langsamer BI gemacht haben. So dauert das Laden eines täglich zu nutzenden Reports in vielen klassischen BI-Systemen mehrere Minuten. Wenn sich das Laden eines Dashboards mit einer kleinen Kaffee-Pause kombinieren lässt, mag das hin und wieder für bestimmte Berichte noch hinnehmbar sein. Spätestens jedoch bei der häufigen Nutzung sind lange Ladezeiten und unzuverlässige Reports nicht mehr hinnehmbar.
Ein Grund für mangelhafte Performance ist die Hardware, die sich unter Einsatz von Cloud-Systemen bereits beinahe linear skalierbar an höhere Datenmengen und mehr Analysekomplexität anpassen lässt. Der Einsatz von Cloud ermöglicht auch die modulartige Trennung von Speicher und Rechenleistung von den Daten und Applikationen und ist damit grundsätzlich zu empfehlen, jedoch nicht für alle Unternehmen unbedingt die richtige Wahl und muss zur Unternehmensphilosophie passen.
Tatsächlich ist die Performance nicht nur von der Hardware abhängig, auch die richtige Auswahl an Software und die richtige Wahl der Gestaltung von Datenmodellen und Datenflüssen spielt eine noch viel entscheidender Rolle. Denn während sich Hardware relativ einfach wechseln oder aufrüsten lässt, ist ein Wechsel der Architektur mit sehr viel mehr Aufwand und BI-Kompetenz verbunden. Dabei zwingen unpassende Datenmodelle oder Datenflüsse ganz sicher auch die neueste Hardware in maximaler Konfiguration in die Knie.
6. Kosteneffizienter Einsatz und Fazit
Professionelle Cloud-Systeme, die für BI-Systeme eingesetzt werden können, bieten Gesamtkostenrechner an, beispielsweise Microsoft Azure, Amazon Web Services und Google Cloud. Mit diesen Rechnern – unter Einweisung eines erfahrenen BI-Experten – können nicht nur Kosten für die Nutzung von Hardware abgeschätzt, sondern auch Ideen zur Kostenoptimierung kalkuliert werden. Dennoch ist die Cloud immer noch nicht für jedes Unternehmen die richtige Lösung und klassische Kalkulationen für On-Premise-Lösungen sind notwendig und zudem besser planbar als Kosten für die Cloud.
Kosteneffizienz lässt sich übrigens auch mit einer guten Auswahl der passenden Software steigern. Denn proprietäre Lösungen sind an unterschiedliche Lizenzmodelle gebunden und können nur über Anwendungsszenarien miteinander verglichen werden. Davon abgesehen gibt es jedoch auch gute Open Source Lösungen, die weitgehend kostenfrei genutzt werden dürfen und für viele Anwendungsfälle ohne Abstriche einsetzbar sind.
Die Total Cost of Ownership (TCO) gehören zum BI-Management mit dazu und sollten stets im Fokus sein. Falsch wäre es jedoch, die Kosten einer BI nur nach der Kosten für Hardware und Software zu bewerten. Ein wesentlicher Teil der Kosteneffizienz ist komplementär mit den Aspekten für die Performance des BI-Systems, denn suboptimale Architekturen arbeiten verschwenderisch und benötigen mehr und teurere Hardware als sauber abgestimmte Architekturen. Die Herstellung der zentralen Datenbereitstellung in adäquater Qualität kann viele unnötige Prozesse der Datenaufbereitung ersparen und viele flexible Analysemöglichkeiten auch redundante Systeme direkt unnötig machen und somit zu Einsparungen führen.
In jedem Fall ist ein BI für Unternehmen mit vielen operativen Prozessen grundsätzlich immer günstiger als kein BI zu haben. Heutzutage könnte für ein Unternehmen nichts teurer sein, als nur nach Bauchgefühl gesteuert zu werden, denn der Markt tut es nicht und bietet sehr viel Transparenz.
Dennoch sind bestehende BI-Architekturen hin und wieder zu hinterfragen. Bei genauerem Hinsehen mit BI-Expertise ist die Kosteneffizienz und Datentransparenz häufig möglich.





 Ross Perez is the Senior Director, Marketing EMEA at
Ross Perez is the Senior Director, Marketing EMEA at