Applying Data Science Techniques in Python to Evaluate Ionospheric Perturbations from Earthquakes
Multi-GNSS (Galileo, GPS, and GLONASS) Vertical Total Electron Content Estimates: Applying Data Science techniques in Python to Evaluate Ionospheric Perturbations from Earthquakes
1 Introduction
Today, Global Navigation Satellite System (GNSS) observations are routinely used to study the physical processes that occur within the Earth’s upper atmosphere. Due to the experienced satellite signal propagation effects the total electron content (TEC) in the ionosphere can be estimated and the derived Global Ionosphere Maps (GIMs) provide an important contribution to monitoring space weather. While large TEC variations are mainly associated with solar activity, small ionospheric perturbations can also be induced by physical processes such as acoustic, gravity and Rayleigh waves, often generated by large earthquakes.
In this study Ionospheric perturbations caused by four earthquake events have been observed and are subsequently used as case studies in order to validate an in-house software developed using the Python programming language. The Python libraries primarily utlised are Pandas, Scikit-Learn, Matplotlib, SciPy, NumPy, Basemap, and ObsPy. A combination of Machine Learning and Data Analysis techniques have been applied. This in-house software can parse both receiver independent exchange format (RINEX) versions 2 and 3 raw data, with particular emphasis on multi-GNSS observables from GPS, GLONASS and Galileo. BDS (BeiDou) compatibility is to be added in the near future.
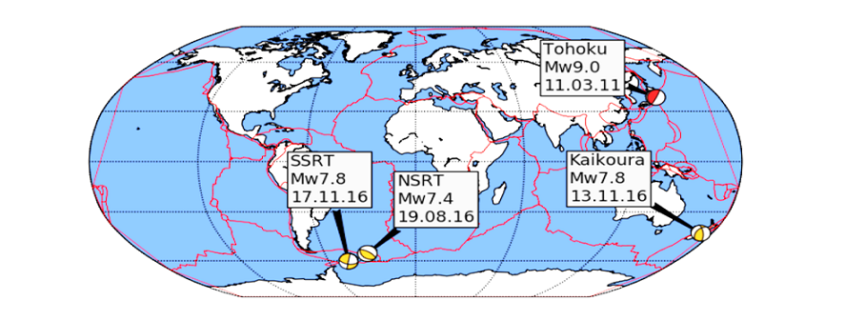
Several case studies focus on four recent earthquakes measuring above a moment magnitude (MW) of 7.0 and include: the 11 March 2011 MW 9.1 Tohoku, Japan, earthquake that also generated a tsunami; the 17 November 2013 MW 7.8 South Scotia Ridge Transform (SSRT), Scotia Sea earthquake; the 19 August 2016 MW 7.4 North Scotia Ridge Transform (NSRT) earthquake; and the 13 November 2016 MW 7.8 Kaikoura, New Zealand, earthquake.
Ionospheric disturbances generated by all four earthquakes have been observed by looking at the estimated vertical TEC (VTEC) and residual VTEC values. The results generated from these case studies are similar to those of published studies and validate the integrity of the in-house software.
2 Data Cleaning and Data Processing Methodology
Determining the absolute VTEC values are useful in order to understand the background ionospheric conditions when looking at the TEC perturbations, however small-scale variations in electron density are of primary interest. Quality checking processed GNSS data, applying carrier phase leveling to the measurements, and comparing the TEC perturbations with a polynomial fit creating residual plots are discussed in this section.
Time delay and phase advance observables can be measured from dual-frequency GNSS receivers to produce TEC data. Using data retrieved from the Center of Orbit Determination in Europe (CODE) site (ftp://ftp.unibe.ch/aiub/CODE), the differential code biases are subtracted from the ionospheric observables.
2.1 Determining VTEC: Thin Shell Mapping Function
The ionospheric shell height, H, used in ionosphere modeling has been open to debate for many years and typically ranges from 300 – 400 km, which corresponds to the maximum electron density within the ionosphere. The mapping function compensates for the increased path length traversed by the signal within the ionosphere. Figure 1 demonstrates the impact of varying the IPP height on the TEC values.
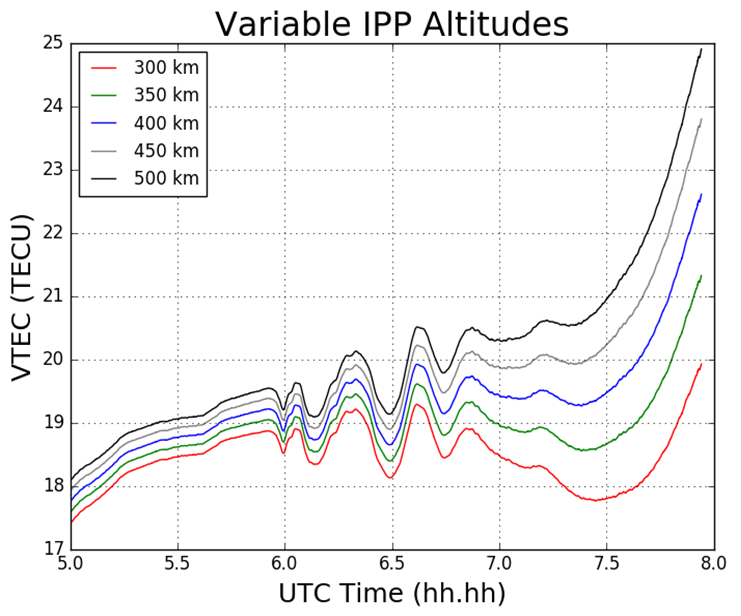
Figure 1 Impact on TEC values from varying IPP heights. The height of the thin shell, H, is increased in 50km increments from 300 to 500 km.
2.2 Phase Smoothing
For dual-frequency GNSS users TEC values can be retrieved with the use of dual-frequency measurements by applying calculations. Calculation of TEC for pseudorange measurements in practice produces a noisy outcome and so the relative phase delay between two carrier frequencies – which produces a more precise representation of TEC fluctuations – is preferred. To circumvent the effect of pseudorange noise on TEC data, GNSS pseudorange measurements can be smoothed by carrier phase measurements, with the use of the carrier phase smoothing technique, which is often referred to as carrier phase leveling.
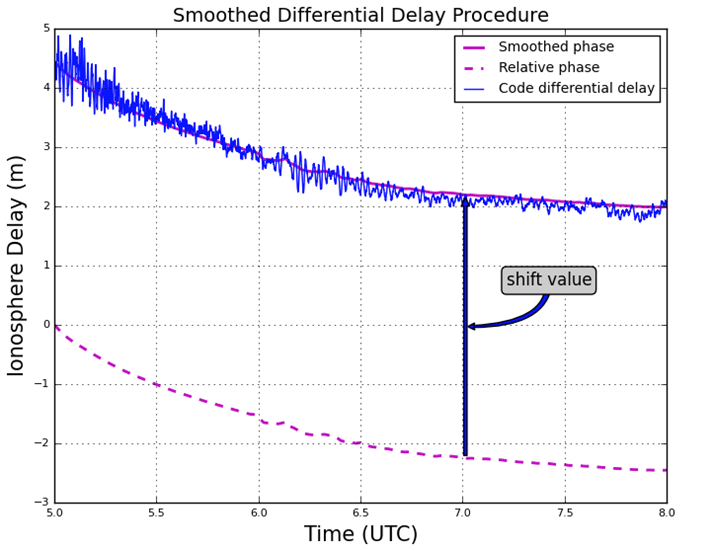
Figure 2 Phase smoothed code differential delay
2.3 Residual Determination
For the purpose of this study the monitoring of small-scale variations in ionospheric electron density from the ionospheric observables are of particular interest. Longer period variations can be associated with diurnal alterations, and changes in the receiver- satellite elevation angles. In order to remove these longer period variations in the TEC time series as well as to monitor more closely the small-scale variations in ionospheric electron density, a higher-order polynomial is fitted to the TEC time series. This higher-order polynomial fit is then subtracted from the observed TEC values resulting in the residuals. The variation of TEC due to the TID perturbation are thus represented by the residuals. For this report the polynomial order applied was typically greater than 4, and was chosen to emulate the nature of the arc for that particular time series. The order number selected is dependent on the nature of arcs displayed upon calculating the VTEC values after an initial inspection of the VTEC plots.
3 Results
3.1 Tohoku Earthquake
For this particular report, the sampled data focused on what was retrieved from the IGS station, MIZU, located at Mizusawa, Japan. The MIZU site is 39N 08′ 06.61″ and 141E 07′ 58.18″. The location of the data collection site, MIZU, and the earthquake epicenter can be seen in Figure 3.
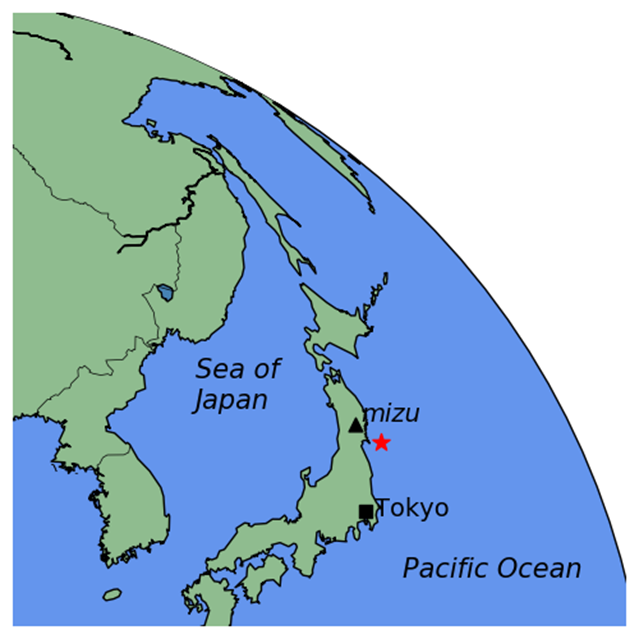
Figure 3 MIZU IGS station and Tohoku earthquake epicenter [generated using the Python library, Basemap]
Figure 4 displays the ionospheric delay in terms of vertical TEC (VTEC), in units of TECU (1 TECU = 1016 el m-2). The plot is split into two smaller subplots, the upper section displaying the ionospheric delay (VTEC) in units of TECU, the lower displaying the residuals. The vertical grey-dashed lined corresponds to the epoch of the earthquake at 05:46:23 UT (2:46:23 PM local time) on March 11 2011. In the upper section of the plot, the blue line corresponds to the absolute VTEC value calculated from the observations, in this case L1 and L2 on GPS, whereby the carrier phase leveling technique was applied to the data set. The VTEC values are mapped from the STEC values which are calculated from the LOS between MIZU and the GPS satellite PRN18 (on Figure 4 denoted G18). For this particular data set as seen in Figure 4, a polynomial fit of five degrees was applied, which corresponds to the red-dashed line. As an alternative to polynomial fitting, band-pass filtering can be employed when TEC perturbations are desired. However for the scope of this report polynomial fitting to the time series of TEC data was the only method used. In the lower section of Figure 4 the residuals are plotted. The residuals are simply the phase smoothed delay values (the blue line) minus the polynomial fit line (the red-dashed line). All ionosphere delay plots follow the same layout pattern and all time data is represented in UT (UT = GPS – 15 leap seconds, whereby 15 leap seconds correspond to the amount of leap seconds at the time of the seismic event). The time series shown for the ionosphere delay plots are given in terms of decimal of the hour, so that the format follows hh.hh.
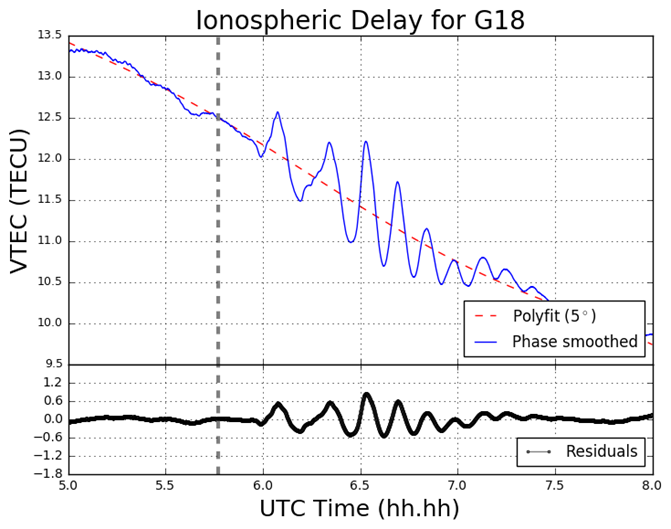
Figure 4 VTEC and residual plot for G18 at MIZU on March 11 2011
3.2 South Georgia Earthquake
In the South Georgia Island region located in the North Scotia Ridge Transform (NSRT) plate boundary between the South American and Scotia plates on 19 August 2016, a magnitude of 7.4 MW earthquake struck at 7:32:22 UT. This subsection analyses the data retrieved from KEPA and KRSA. As well as computing the GPS and GLONASS TEC values, four Galileo satellites (E08, E14, E26, E28) are also analysed. Figure 5 demonstrates the TEC perturbations as computed for the Galileo L1 and L5 carrier frequencies.
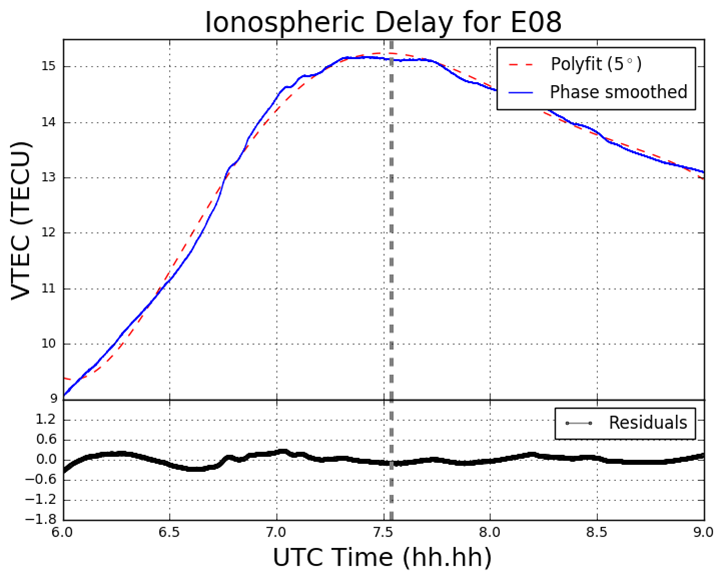
Figure 5 VTEC and residual plots at KRSA on 19 August 2016. The plots are from the perspective of the GNSS receiver at KRSA, for four Galileo satellites (a) E08; (b) E14; (c) E24; (d) E26. The y-axes and x-axes in all plots do not conform with one another but are adjusted to fit the data. The y-axes for the residual section of each plot is consistent with one another.
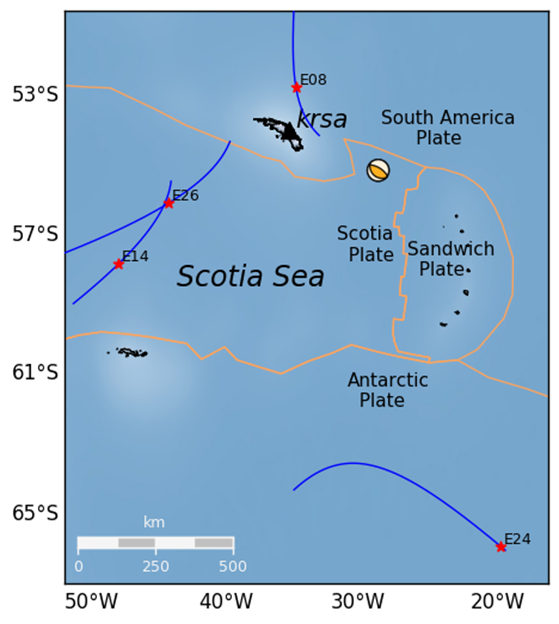
Figure 6 Geometry of the Galileo (E08, E14, E24 and E26) satellites’ projected ground track whereby the IPP is set to 300km altitude. The orange lines correspond to tectonic plate boundaries.
4 Conclusion
The proximity of the MIZU site and magnitude of the Tohoku event has provided a remarkable – albeit a poignant – opportunity to analyse the ocean-ionospheric coupling aftermath of a deep submarine seismic event. The Tohoku event has also enabled the observation of the origin and nature of the TIDs generated by both a major earthquake and tsunami in close proximity to the epicenter. Further, the Python software developed is more than capable of providing this functionality, by drawing on its mathematical packages, such as NumPy, Pandas, SciPy, and Matplotlib, as well as employing the cartographic toolkit provided from the Basemap package, and finally by utilizing the focal mechanism generation library, Obspy.
Pre-seismic cursors have been investigated in the past and strongly advocated in particular by Kosuke Heki. The topic of pre-seismic ionospheric disturbances remains somewhat controversial. A potential future study area could be the utilization of the Python program – along with algorithmic amendments – to verify the existence of this phenomenon. Such work would heavily involve the use of Scikit-Learn in order to ascertain the existence of any pre-cursors.
Finally, the code developed is still retained privately and as of yet not launched to any particular platform, such as GitHub. More detailed information on this report can be obtained here:

Download as PDF


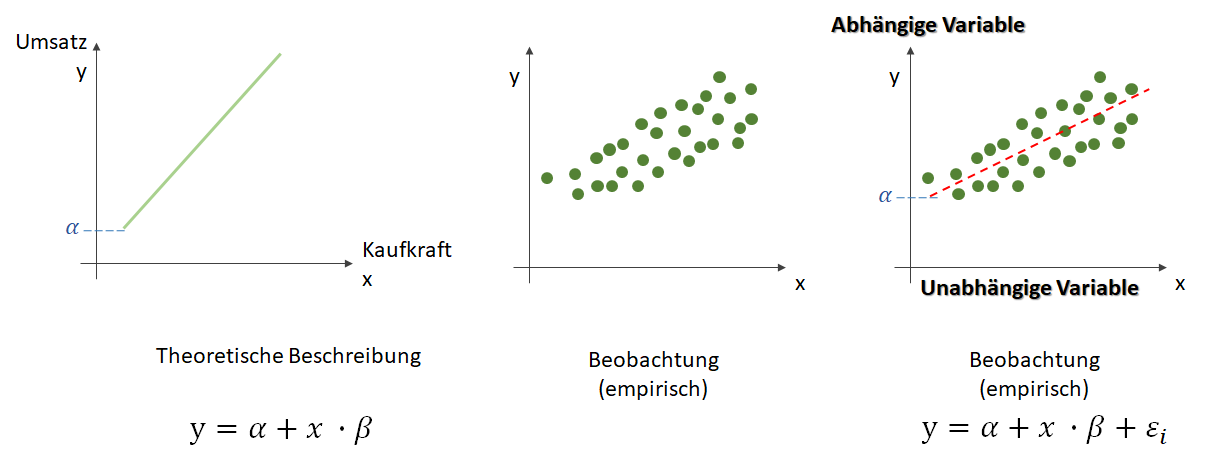
 , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  der Zielwert (abhängige Variable) und
der Zielwert (abhängige Variable) und  der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable
der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable  (Alpha) ist der
(Alpha) ist der  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung. ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.svg "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.svg "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.svg "Rendered by QuickLaTeX.com")
 .
.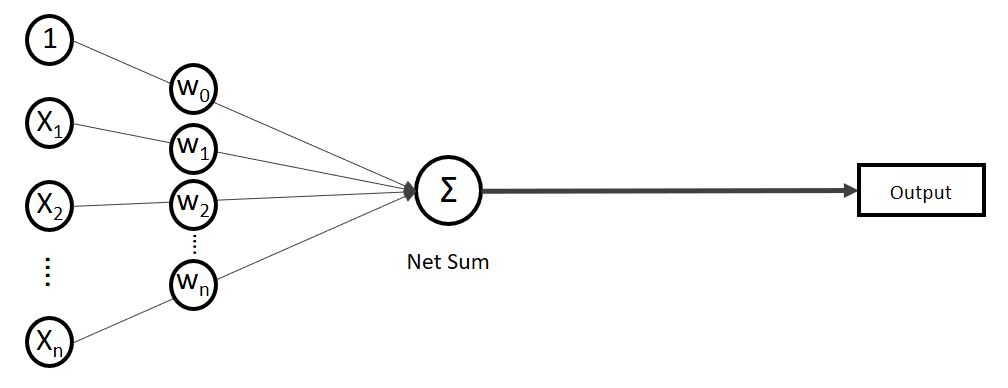
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
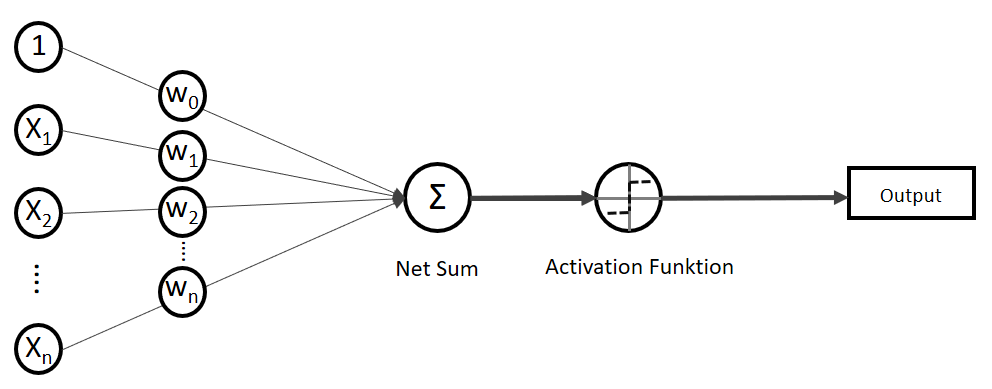
 (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 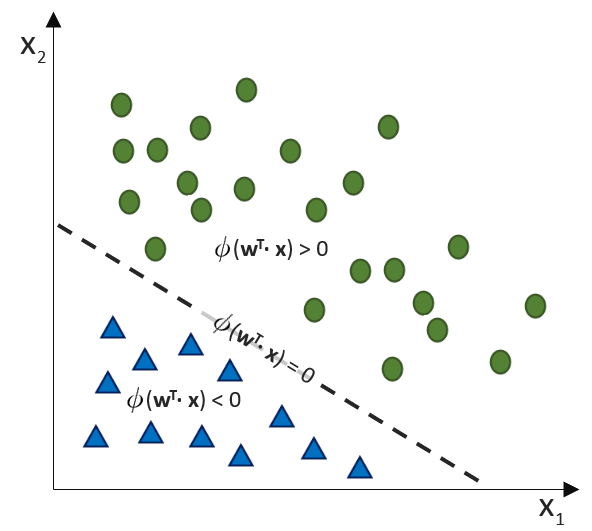
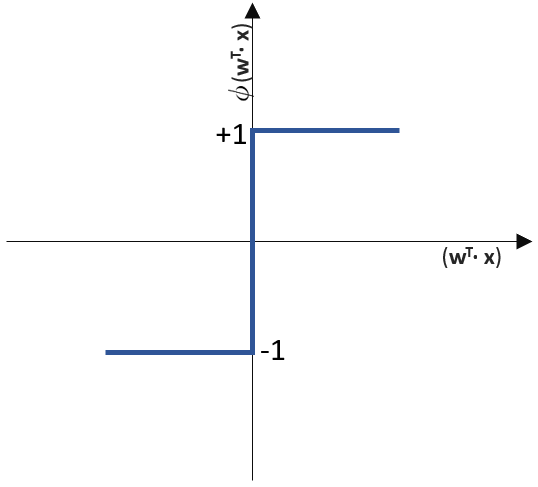
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.svg "Rendered by QuickLaTeX.com")

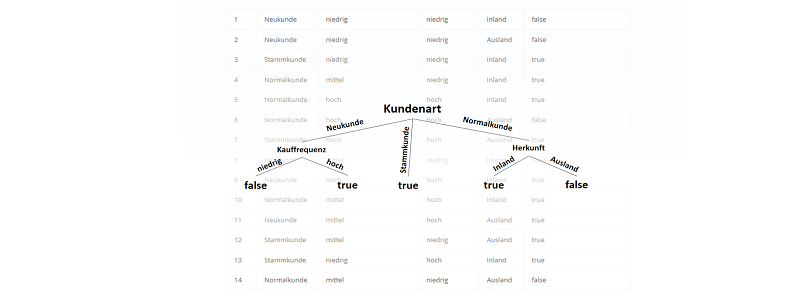
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

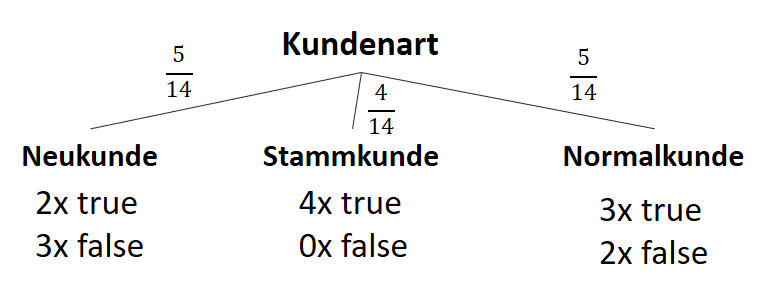



![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.svg "Rendered by QuickLaTeX.com")
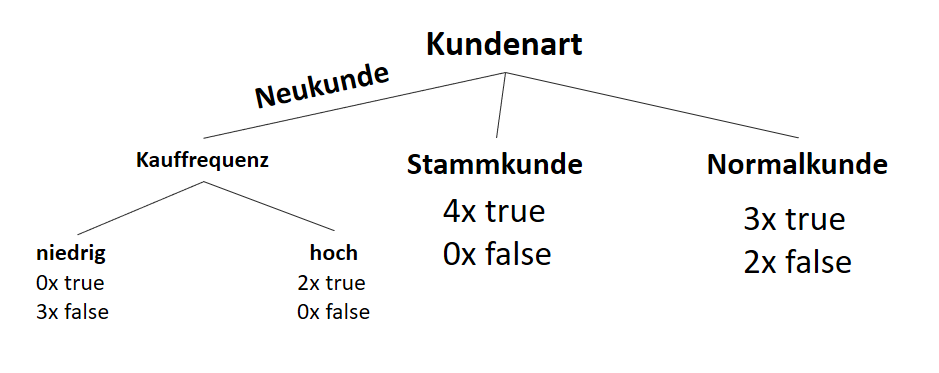
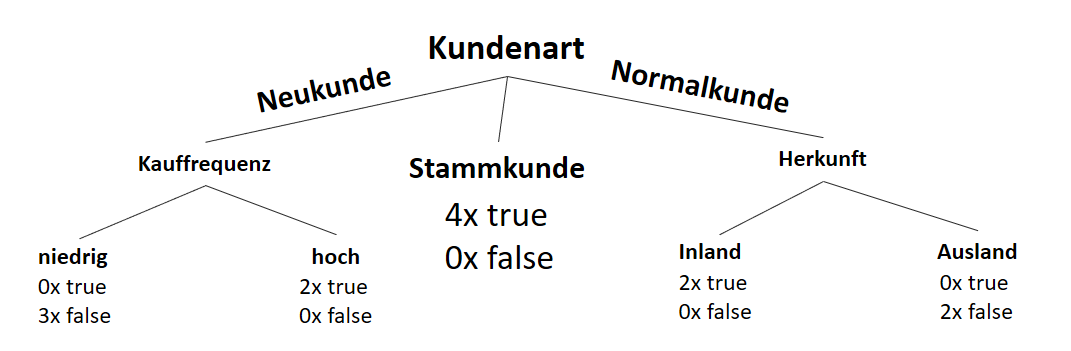
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.svg "Rendered by QuickLaTeX.com")
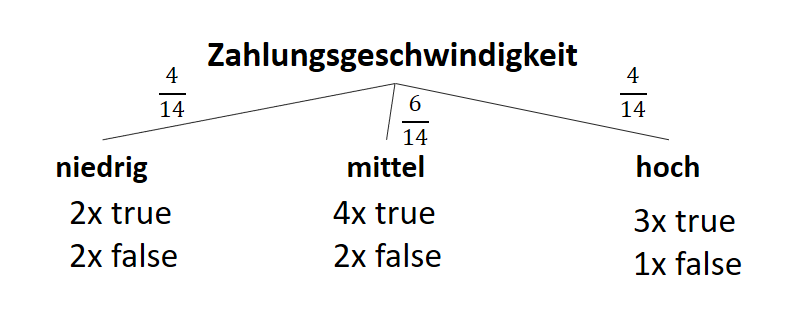



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.svg "Rendered by QuickLaTeX.com")
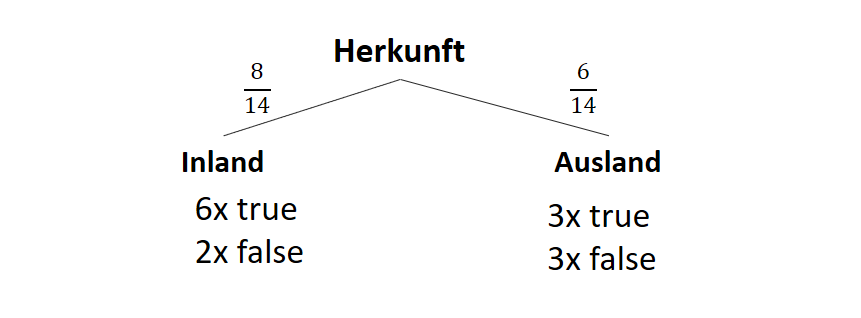


![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.svg "Rendered by QuickLaTeX.com")
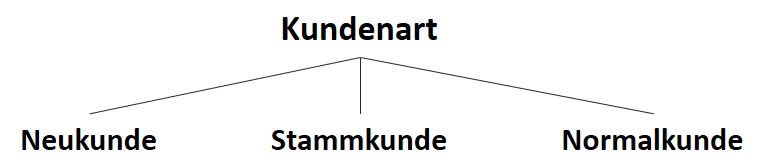
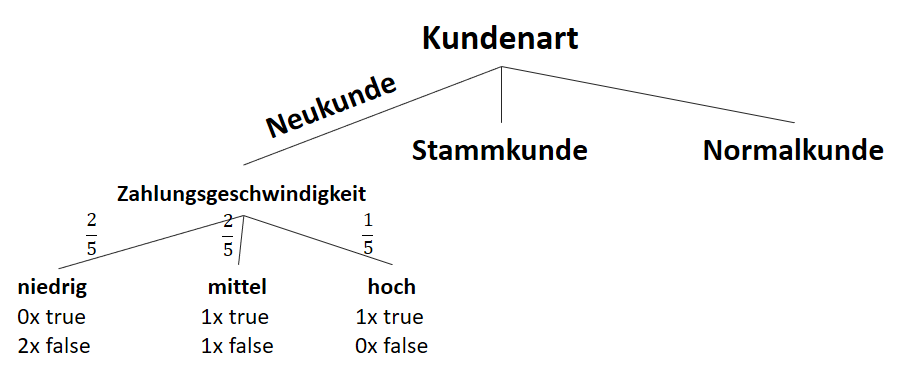



![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.svg "Rendered by QuickLaTeX.com")
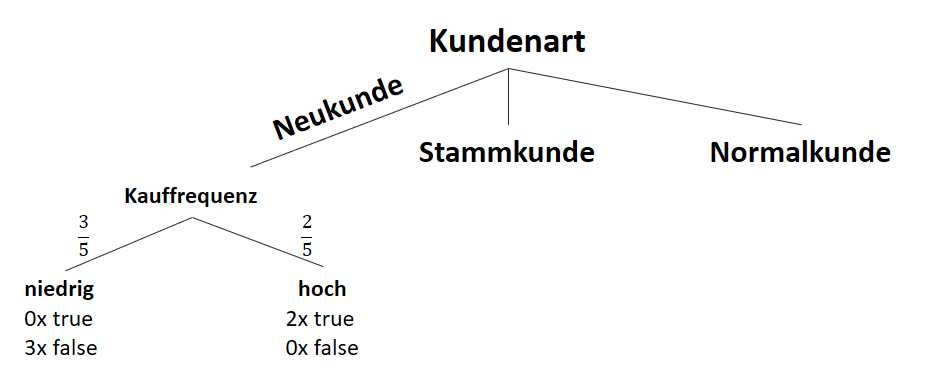
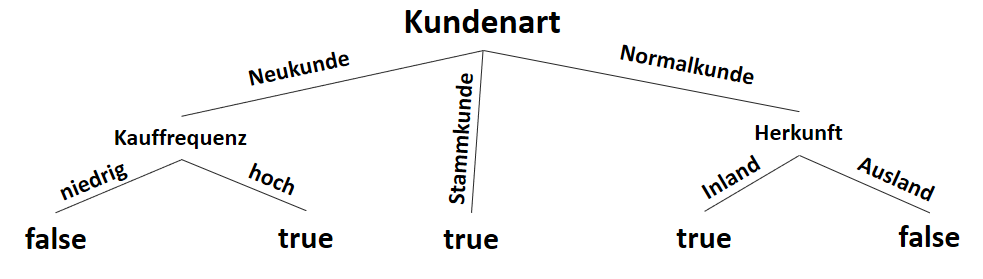
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.svg "Rendered by QuickLaTeX.com")