Interview – Bedeutung von Data Science für Deutschland
Klaas Wilhelm Bollhoefer ist Chief Data Scientist bei The unbelievable Machine Company (*um), einem Full-Service Dienstleister für Cloud Computing und Big Data aus Berlin. Er übersetzt Business-Anforderungen in kundenspezifische Big Data Lösungen und agiert an der Schnittstelle von Business, IT, Künstlicher Intelligenz und Design. Er ist Community Manager diverser Fachgruppen sowie Mitglied in Beiräten und Jurys zahlreiche r internationaler Big Data Veranstaltungen. Vor seiner Tätigkeit als Chief Data Scientist hatte Herr Bollhöfer bei Pixelpark den Bereich “Beratung und Konzeption” aus der Taufe gehoben und über mehrere Jahre verantwortet, sowie selbständig als strategischer Berater gearbeitet. Er hat Medientechnik, Visual Communication und Philosophie in Köln und Melbourne studiert, hielt Lehraufträge zu Project Governance & Social Data an der TU Berlin, HTW Berlin, der Uni Siegen und der FH Köln inne und schreibt ab und an für diverse Fachpublikationen.
r internationaler Big Data Veranstaltungen. Vor seiner Tätigkeit als Chief Data Scientist hatte Herr Bollhöfer bei Pixelpark den Bereich “Beratung und Konzeption” aus der Taufe gehoben und über mehrere Jahre verantwortet, sowie selbständig als strategischer Berater gearbeitet. Er hat Medientechnik, Visual Communication und Philosophie in Köln und Melbourne studiert, hielt Lehraufträge zu Project Governance & Social Data an der TU Berlin, HTW Berlin, der Uni Siegen und der FH Köln inne und schreibt ab und an für diverse Fachpublikationen.
Data Science Blog: Herr Bollhoefer, welcher Weg hat Sie ins Data Science von The unbelievable Machine (*um) geführt?
Bollhoefer: Das war alles andere als eine gradlinige Geschichte. Ich kannte Ravin Mehta, Gründer und Geschäftsführer von *um noch von der Pixelpark AG, bei der ich von 2000 bis 2009 in verschiedenen Positionen tätig war. Das nächste was Ravin vorhatte, nachdem er in den Cloud-Markt mit *um sehr erfolgreich eingestiegen war, war Big Data. Als ich ihn fragte, was Big Data denn genau sei, meinte er, dass wüsste (damals) noch niemand so genau!
Das war vor etwa vier Jahren und es war die Chance für mich, in dieses neue Thema einzusteigen und zudem eine tolle Gelegenheit – denn eigentlich bin ich ja Ingenieur – für mich, Mathematik wieder aufzufrischen. Ich war der erste Mitarbeiter für Data Science bei *um, habe das Dienstleistungsportfolio maßgeblich mitaufgebaut und konnte mich daher als Chief Data Scientist positionieren. Ich bin allerdings kein Spezialist, sondern Generalist über alles, was man dem Data Science so zuschreiben kann.
Data Science Blog: Welche Branchen profitieren durch Big Data und Data Science gegenwärtig und in naher Zukunft am meisten?
Bollhoefer: Branchen, die schon seit längerer Zeit direkt von Big Data und Data Science profitieren, sind die sogenannten Digital Pure Player, also vorwiegend junge Unternehmen, deren Geschäftsmodelle rein auf digitaler Kommunikation aufbauen sowie eCommerce-Unternehmen. Unter den Fachbereichen profitieren vor allem das Marketing und unter den Geschäftsmodellen ganz besonders das Advertising von Big Data Analytics. Der Begriff Customer Analytics ist längst etabliert.
Zu den Newcomern gehören die Branchen, auf die Deutschland besonders stolz ist: Sowohl die OEMs, als auch die größeren Zulieferer der Automobilbranche setzen mittlerweile vermehrt auf Big Data Analytics, wobei das Supply Chain Management mit Blick auf Logistik und Warenwirtschaft aktuell ganz klar im Vordergrund steht. Es ist hier für uns bereits viel Bewegung spürbar, aber noch lange nicht das Maximum ausgeschöpft. Zumindest ist für viele dieser Unternehmen der Einstieg gefunden.
Auch aus der klassischen Produktion entsteht im Kontext von Industrie 4.0 gerade Nachfrage nach Data Science, wenn auch etwas langsamer als erhofft. Die Potenziale durch die Vernetzung von Produktionsmaschinen sind noch nicht annähernd ausgeschöpft.
Branchen, die meiner Erfahrung nach noch nicht genügend aktiv geworden sind, sind die Chemie- und Pharma-Industrie. Auch Banken und Versicherungen, die ja nicht mit realen Werten, sondern nur mit Daten arbeiten, stehen – abgesehen von einigen Ausnahmen – überraschenderweise noch nicht in den Startlöchern, trotz großer Potenziale.


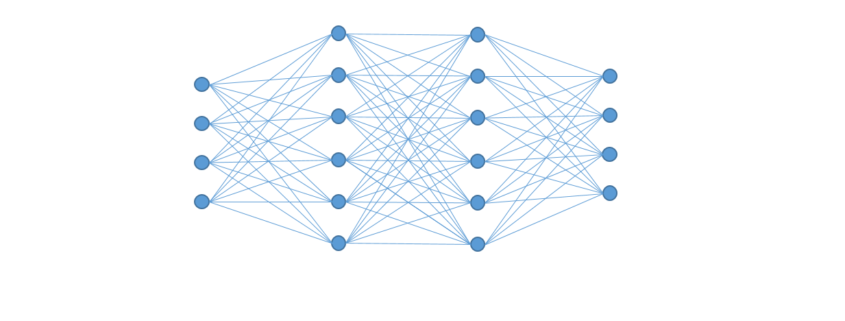


 (Theta) multipliziert und die Ergebnisse aufsummiert. Das Zwischenergebnis ist die Aktivierungsstärke z:
(Theta) multipliziert und die Ergebnisse aufsummiert. Das Zwischenergebnis ist die Aktivierungsstärke z:![\[ z = X_0 \cdot \theta_0 + X_1 \cdot \theta_1 + X_2 \cdot \theta_2 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-49288c71db69e864888f642613627b1b_l3.png "Rendered by QuickLaTeX.com")

![\[ sigmoid(z) = \frac{1}{1+e^{-z}} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-d02636a1d3140b9e8e9dc48a1c5c395a_l3.png "Rendered by QuickLaTeX.com")
![\[ Y = sigmoid(X\theta) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-924f70586a4f97cd4aa0dceea3f2b047_l3.png "Rendered by QuickLaTeX.com")