Conversion Rate Optimization: Understanding the Sales Funnel
Are you capturing the attention of consumers or prospects with your content? Do they trust you enough to give you their contact information? Will they come back and buy from you again? Knowing how the sales funnel works and what you can do to improve it will take you down the road of success.
Business 101
As a business owner, your goal is to turn a prospect (meaning a prospective buyer) into a loyal customer. Nobody wants to lose a possible customer after putting a lot of effort into the attempt of establishing a relationship. Once you understand the different stages of the sales funnel, it will be easier to find cracks and holes within. The following sections unpack how sales funnel management can help you optimize your conversion rate and build a successful long-term relationship with your customers and website users.
The Sales Funnel
The sales funnel describes the path a customer takes on the way to buying a product or service. It visualizes the typical journey they go through and in which stage of the buying decision prospects are at the moment. As one of the core concepts in digital marketing, sales funnel management can help you to understand your audience and prevent them from dropping out before a sale is made. It is about giving every potential customer the treatment they are looking for. If you don’t understand your sales funnel, you can’t optimize it. What matters most when it comes to a sales funnel is website optimization.
Prospects move from the top of the funnel to the bottom as they become more familiar with what you have to offer. The sales funnel narrows as visitors move through it, and the number of people in your funnel will continue to decrease the closer you get to sealing the deal. It starts at the top with all the prospects who landed on your website one way or another, while the narrow bottom represents loyal customers.
The 4 Stages of the Sales Funnel
Moving people through the funnel can be a challenge. A stratagem to keep in mind is that your goal should be to solve the “problems” of your customers, or potentially make them aware of a problem they didn’t even know existed. Start by creating content that attracts your prospect’s attention, followed by offering an irresistible solution to the problem. All you have to do then is watch the magic happen.
Truthfully, that is easier said than done, but if you follow the four stages of a prospective customer’s mindset, you will reach your goal sooner than later. The different stages can be easily explained using the AIDA (Awareness, Interest, Decision, Action) strategy. To understand what moves a buying decision, we have to take a closer look at each stage and the approach it requires.
Awareness
To end up with a strong bond with your prospect, you have to gain attention first. Depending on how they found you (organic search results, recommendations, advertisements, or just pure luck), people will put different amounts of trust in your business. If you are lucky and all circumstances fall perfectly into place, a prospect turns into a customer immediately. More often though, the awareness stage does exactly what it sounds like; it creates awareness of your business and your products or services. At this point, all you are trying to do is lead prospects into the next stage, which will make them return for more.
Interest
Once a potential customer is aware of you, you need to build their interest. In this stage potential customers are interested in what you have to offer and are doing research or comparison. It is the perfect time to show off authority in your field and support them with helpful content that does not yet try to sell to them. Make sure your message stays consistent throughout the whole process and do not try to push too hard from the beginning. The interest stage should only lead them to be able to make an informed decision.
Decision
For the most part, the majority of people do not like making decisions and, therefore, getting a prospect to make a buying decision is not an easy feat. At this stage, you have to bring on your A-game and make them an offer they can’t refuse. Whether this means offering free premium shipping, a discount code, or a free month of your services is totally up to you; you just have to make sure that your potential customer wants to take advantage of it. Showcasing positive reviews or social proof is another powerful way that you can get people to take action.
Action
Now your prospect turns into a customer. When he or she purchases your product or takes advantage of your service, that customer becomes part of your business’s ecosystem. But just because they reached the final stage of the sales funnel and the AIDA principle doesn’t mean your work is all said and done. Starting to build a long-term relationship with someone who already trusts your company is easier than starting the sales funnel all over again with a new prospect.
Sales Funnel Management
At this point, you should understand why sales funnel management is so important. Even the best prospects can get lost along the way if expectations aren’t met. It takes time to build a sales funnel that represents what your audience is looking for. The best way to optimize a sales funnel is to start with the results and work your way up. Another point of interest is the timing when people move from one point to the next within the funnel. This can help you find out where, when, and why you’re losing potential customers.
Too slow: New leads are nine times more likely to convert if someone follows up within the first five minutes. On the other hand, a lead is 21 times less likely to turn into a sale after 30 minutes have passed. To react within tight response times like that, you need to implement sales funnel management automation.
Too impatient: It can be tempting to dump a lead that isn’t converting right away and move on to the next. You should ask yourself the question if you are patient enough and if you are following up as much as you should. A marketing automation funnel also helps to stay in touch with the prospect over time.
Too fast: Instead of asking people to buy from you right away, you should cultivate them over time. If you adjust your sales approach to the different stages, you don’t just avoid chasing them away; you also find out what is working and what is a waste of your time.
How can you optimize your conversion rate?
There are countless ways you can improve your conversion rate and turn a “no, thank you” into a “yes, please.” In sales, a no often simply means “not until later” or “try again, I’m just not totally convinced yet.” Any time you encounter problems like that, you can use one or multiple of the following, mostly automated sales techniques, to reach your goals.
Target your Audience
To lead people into your sales funnel, you have to put the right content in front of your prospects. How and where you do that depends on your target audience. Be creative with your content, but make sure it mimics your offer and the call-to-action you are using. Customer relationship management (CRM) can help you track interactions with current and future customers.
Build a Landing Page
A landing page offers content that addresses a specific problem, ideally with a single call-to-action, and should steer your visitor towards becoming a customer. A/B testing your landing pages will help you figure out what your audience responds to best and what language, imagery, or layouts can help you improve conversion rates. Experienced hosting companies like 101domain can help you along the way. Additionally, you can use pay-per-click campaigns to drive traffic to your landing page and contact forms to gain subscribers to a mailing list.
Targeting Soft Conversions
When considering which page to use as a landing page, you can increase your conversion rate by bringing leads to an on-site resource to gain a “soft conversion.”
To illustrate the importance of a good landing page and soft conversions, consider the following data:
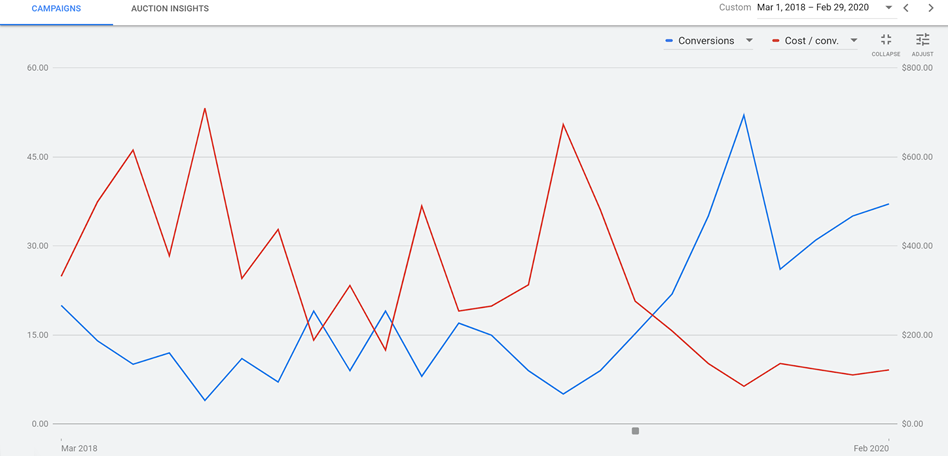
RED: Cost per conversion BLUE: Number of conversions X-AXIS: Time (Screenshot supplied by Howard Ahmanson)
The initial strategy represented in this graph was to take visitors directly to a sales page. This resulted in a very low number of conversions, about a rate of 1%,, which in turn drove the cost per conversion way up. Later, the landing page was switched to an on-site resource, such as a form fill of “get the free retirement planning guide.” This prompted a few soft conversions, or in other words email addresses. Upon doing this, the average number of conversions per month increased from about 10 to between 30 and 45, which in turn dropped the total cost per conversion from a median of about $400 to about $100. This is an approximately 300% increase in conversions at 50% of the cost.
But how does increased conversions translate in terms of sales numbers? To see an example of this, consider the data from the Ken Tamplin Vocal Academy:
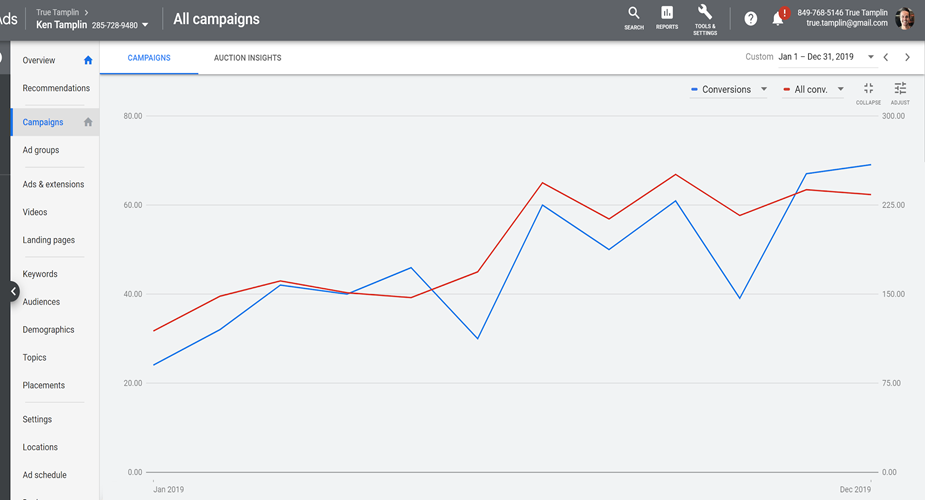
RED: Total conversion, including soft conversions
BLUE: Sales conversions
X-AXIS: Time
When running ads for Ken, the initial strategy was to bring prospects directly to a sales page. Later, this was switched out for a “Yes! I want Ken’s free lessons!” page.
This led to an increase in the number of soft conversions, which led to a tightly correlated increase in sales. There was an increase from around 30 conversions per month up to over 225, which is an increase of 750%.
Create an Email Drip Campaign
Email drip campaigns are used to send a pre-written set of emails to subscribers or customers over time. You can use those campaigns to educate the receiver as well as make them aware of sales or offers. Last but not least, don’t forget about existing customers. This technique is ideal for building up loyalty and making them feel like part of the family.


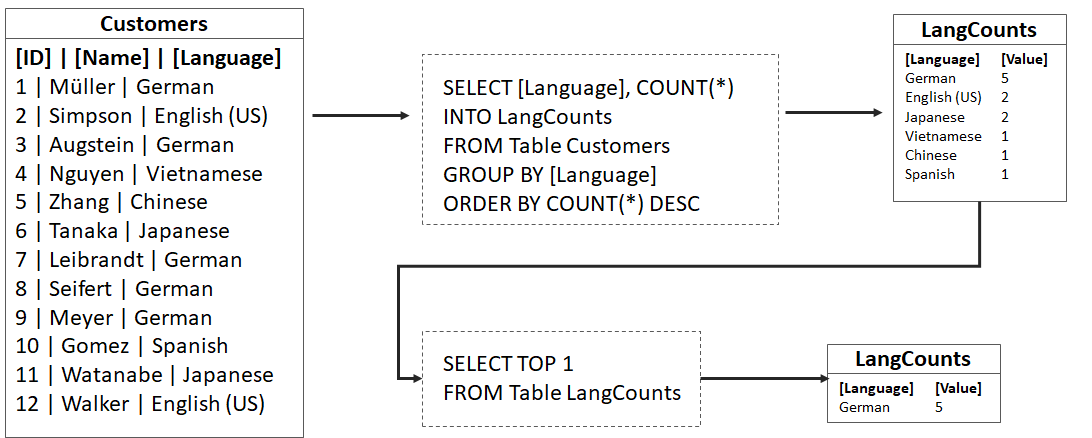
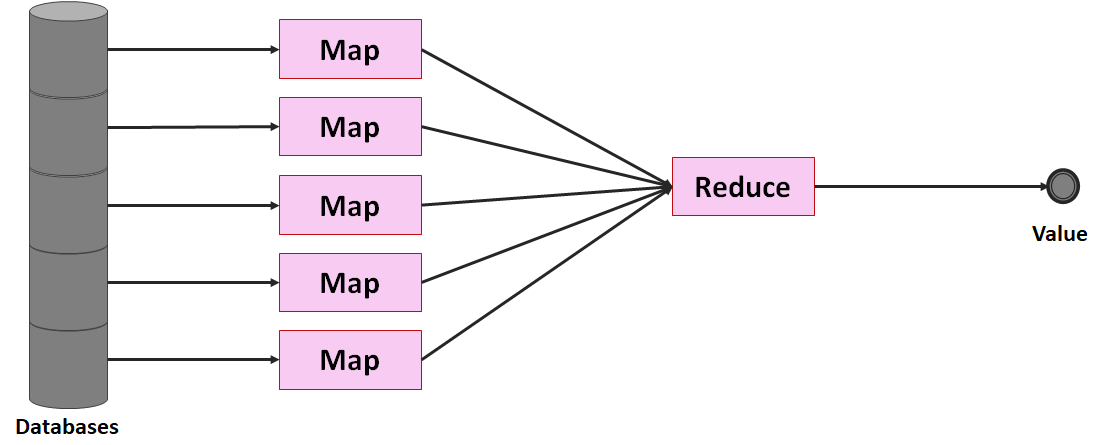
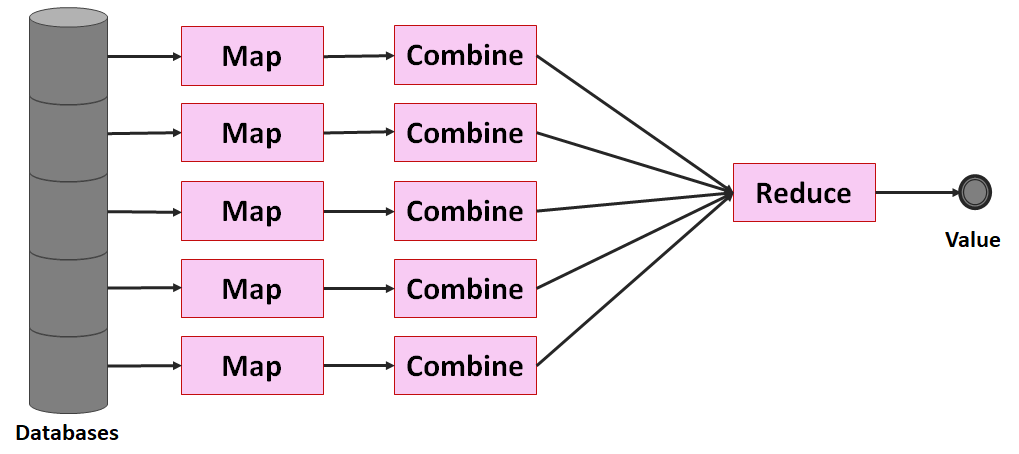
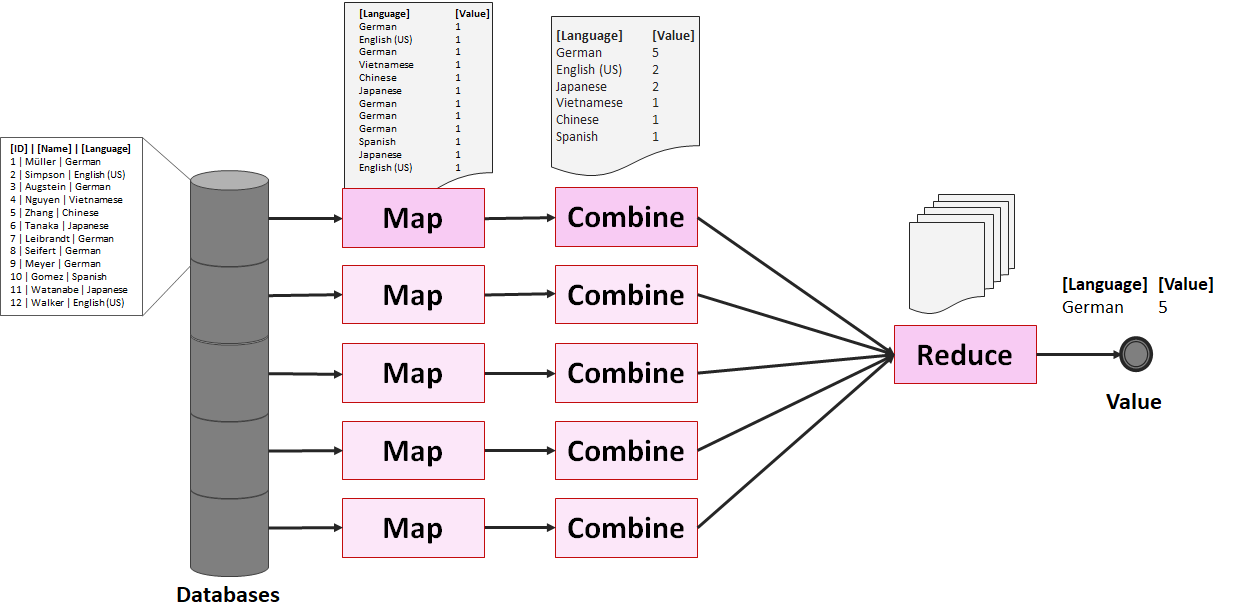
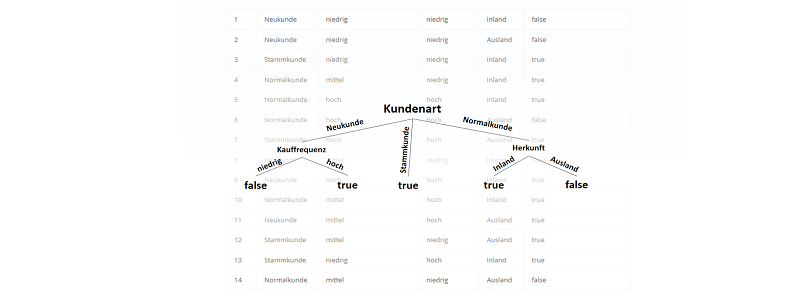
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

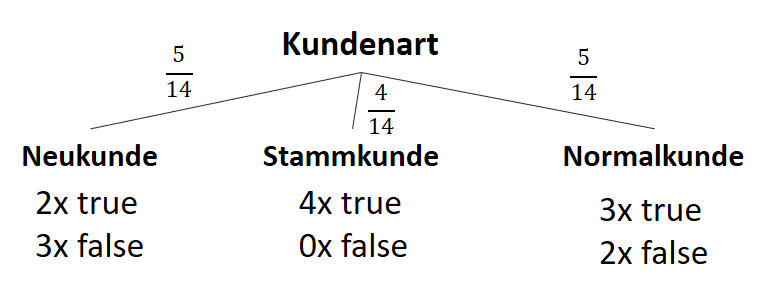



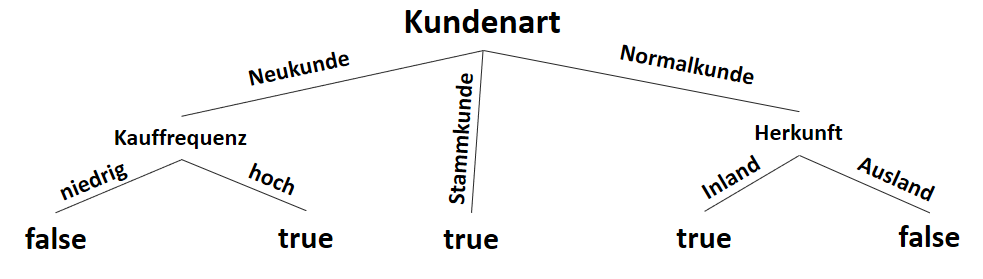
![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.svg "Rendered by QuickLaTeX.com")
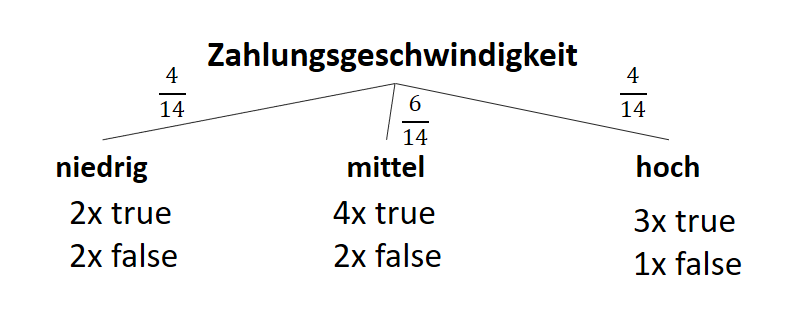



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.svg "Rendered by QuickLaTeX.com")
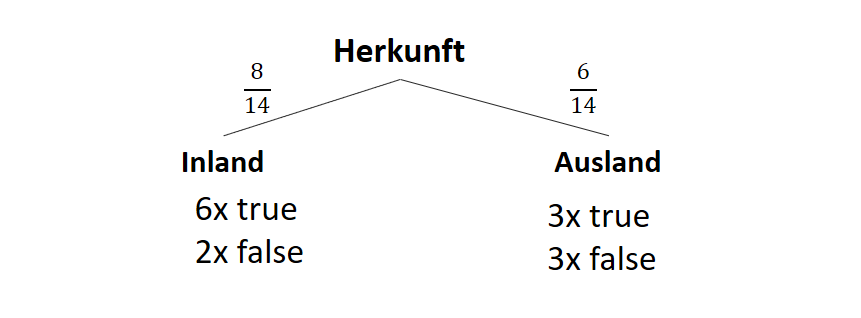


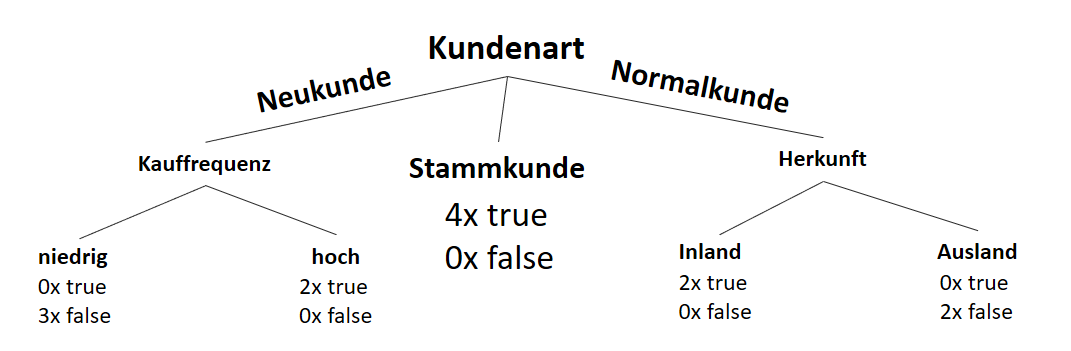
![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.svg "Rendered by QuickLaTeX.com")
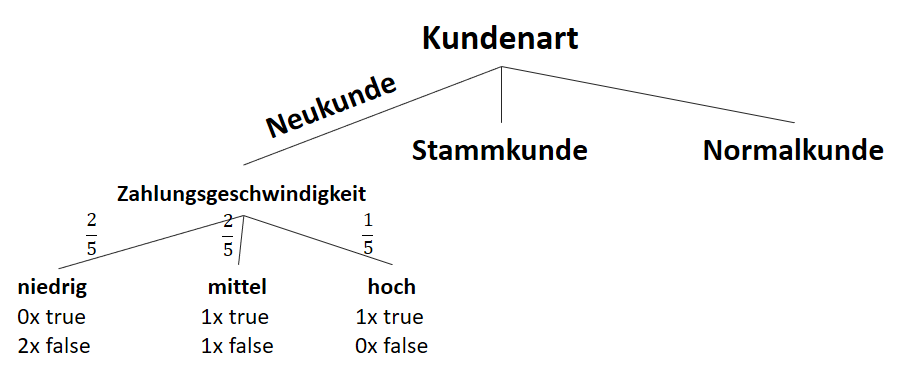



![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.svg "Rendered by QuickLaTeX.com")
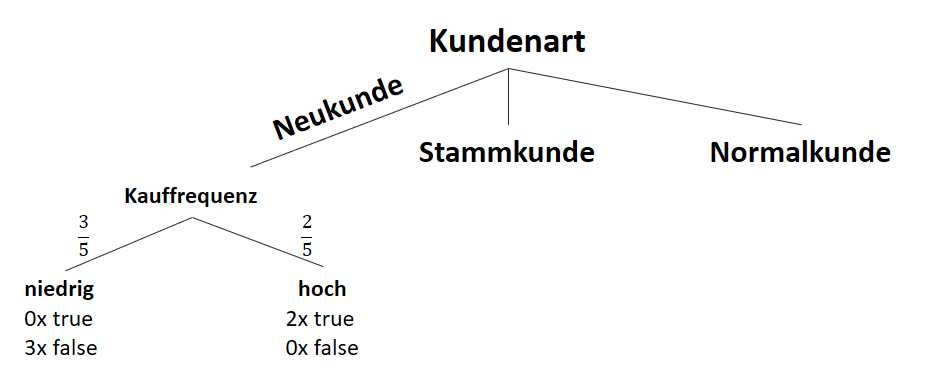
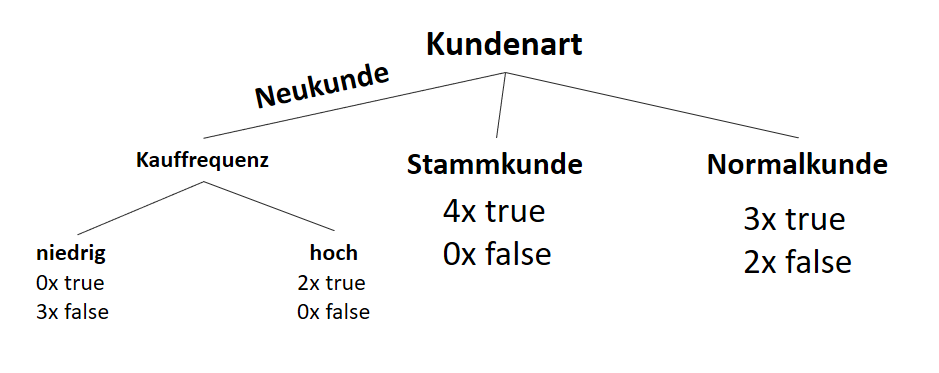
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.svg "Rendered by QuickLaTeX.com")



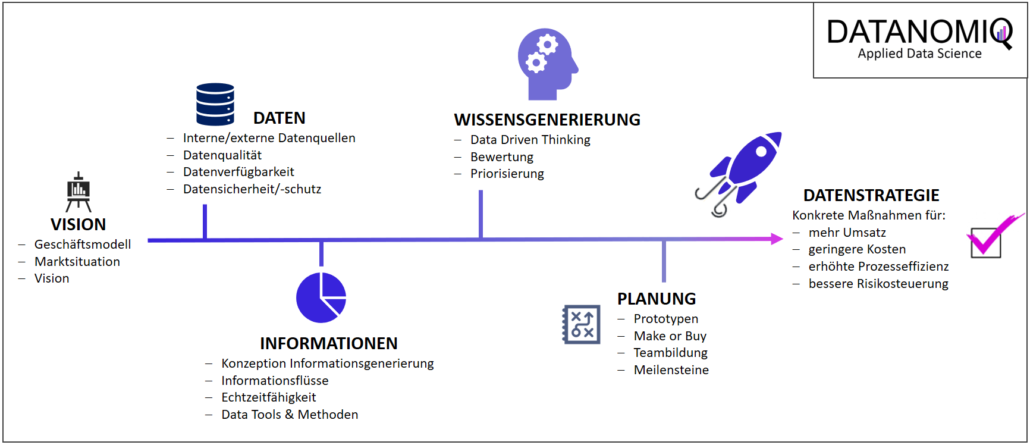
 Mein Vortrag zur Datenstrategie am Data Leader Day 2017
Mein Vortrag zur Datenstrategie am Data Leader Day 2017