OLAP Technology in Business Intelligence
Data in Business Intelligence
Business processes traditionally comprise three stages of data management: collecting, analyzing, and reporting. First, data should be gathered from all the sources through ETL tools (Extract, Transform, Load). After this, there are often issues occurring connected with data consistency hence the data should be cleaned and structured using the function of metadata. Once the data are provided to the end-user in a readable and transparent way it is ready to be analyzed. There are multiple applications ensuring data analysis including Data Mining, OLAP, BI. In order to carry out in-depth and coherent analysis, the best approach is to initially determine KPI as these are the criteria to assess the progress in relation to the goals set.
OLAP definition
OLAP tool belongs to Business Intelligence concept intended for big data management and is short for Online Analytical Processing. OLAP conducts multidimensional data analysis and enables end-users to perform complicated calculations, trend analysis, ‘what-if’ scenarios and the like. Furthermore, owing to OLAP it’s possible to conduct planning and forecasting, budgeting and financial reporting, analysis, and data modeling which contributes to successful decision making in business.
OLAP Structure
An OLAP cube is composed of dimensions containing aggregated information referred to and measures which include numerical data. Dimensions are arranged in hierarchies which in their turn are indicators to determine the rate of granularity; the rate is called a level. The most common dimensions are location, product, and time. The lowest granularity level of a time dimension may be hours while the highest one can present years. This way when there is a query to be responded the measures contribute to filter out the data and select the right object inside the dimension. In the center of the cube there is a star or a snowflake schema which all the dimensions refer to.
OLAP main characteristics
Here are the main features characterizing the OLAP tool”:
– The data in OLAP is structured as a multidimensional cube.
– The cube structure allows users to see the information from various angles given location, products, demographics, time, etc.
– Rapid data access and analysis due to precalculated aggregations.
– Simple and intuitive interface.
– OLAP doesn’t require IT skills or SQL knowledge (as some other business intelligence software tools). Hence its operation eases the burden of IT department.
– The tool supports complex custom calculations
– The OLAP databases maintain historical data and are updated not constantly but regularly.
– The cube design and building process is the pivotal step on the way to successful data processing.
OLAP requirements
When the OLAP technology was invented there were twelve rules generated to follow so that it complies with the concept of online data processing:
Multidimensional
Not only the OLAP view has to be multidimensional but the data should as well be stored in this way of structure in order to provide the multidimensional analysis.
Transparent
The architecture has to be transparent to let the user see and understand the functionality and the client server of the application.
Accessible
The end user must have an opportunity to access the information in its consistent view without any issues related to the sources where the data come from or the way the data are maintained in OLAP.
Consistent Reporting
The data are regularly upgraded and its volume grows progressively although the user shouldn’t see problems changes in the process of scheduled reporting regarding that.
Client-Server
OLAP application has to manage client-server architecture as it manages vast volumes of data often requiring a core server for storage and maintenance.
Common Dimensionality
The main feature of the dimension structure in OLAP must be the same for all the dimensions to keep the data consistent, accurate, valid, complete, etc. Thus the dimensions have to possess common operation capabilities and be equal in structure.
Dynamic Sparse Matrix Handling
A usual OLAP application must manage to deal with sparse matrices and shouldn’t let the cube expand excessively as a usual OLAP cube is relatively sparse.
Multi-User
OLAP technology is originally supposed to provide an opportunity to access the data for multiple users simultaneously. The process of data management must at the same time be ensured with security and integrity.
Unrestricted Cross-dimensional Operations
A typical OLAP application is meant to handle all calculations and operations (such as slice-and-dice, drill up-down, drill through etc.) without the participation of the user. Commonly the tool delivers a language to exploit while requiring specified information.
Intuitive Data Manipulation
All OLAP operations which handle dimensions, measures, hierarchies, levels etc. have to be user-friendly and easily adopted without requiring additional technical skills. An average employee is considered to cope with the data navigation and management through clear displaying and handy operations.
Flexible Reporting
The main function – reporting must be flexible with a view to organizing all the rows, columns, and page setup containing a requisite number of dimensions and hierarchies from the data. As a result, the user has to gain a report comprising all the needed members and the relations between them.
Unlimited Dimensions and Aggregation Levels
When the technology was designed it was intended to be able to contain up to twenty dimensions in the cube. Each dimension had to provide as many aggregation levels inside a hierarchy as required. The idea was to manage great volumes of data keeping end-users absolutely aware of the performance of the organization.
Advantages of OLAP
Speed
Before OLAP was invented and introduced to the market there hadn’t been a tool to rapidly run the queries and it had taken long to retrieve the required information from the data. Thus the main advantage of the OLAP application is its speed gained due to precomputation of the data aggregations.
MDX designer and ad-hoc reports
MDX Designer is aimed at creating interactive ad-hoc reports. The reports provide a better understanding of the business processes and the organization’s performance in the market.
Visualization
OLAP provides its users with sophisticated data analytics allowing them to see data from different perspectives. There are numerous formats to visualize the requisite data: pie charts, graphs, heat maps, reports, pyramids, etc. Moreover, OLAP includes a number of operations to handle data: rotate, drill up and down, slice and dice, etc. Besides, there’s also an opportunity to apply a ‘what-if’ scenario due to a write-back option. All mentioned above can significantly contribute to decision-making process regarding the ongoing situation.
Flexibility
OLAP table displayed is flexible with column and row labels depending on the requirements of the user. Moreover, the reporting generated is available in multiple dimensions.







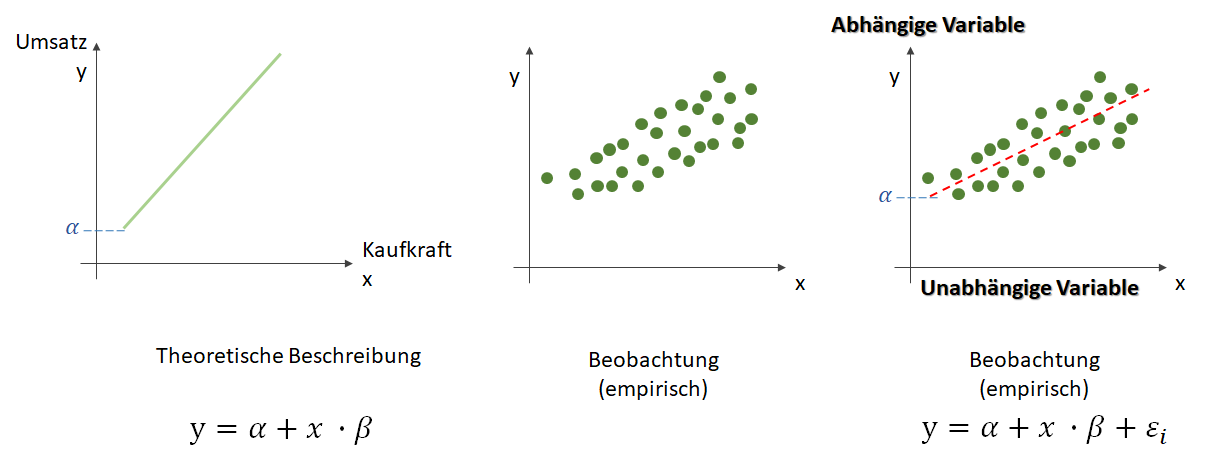
 , die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist
, die unsere Punktwolke – mit der wir uns zutrauen, Vorhersagen über die abhängige Variable vornehmen zu können – möglichst gut beschreibt. Dabei ist  der Zielwert (abhängige Variable) und
der Zielwert (abhängige Variable) und  der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable
der Eingabewert. Wir arbeiten also in einer zwei-dimensionalen Welt. Variablen, die die Funktion mathematisch definieren, werden oft als griechische Buchstaben darsgestellt. Die Variable  (Alpha) ist der
(Alpha) ist der  . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  (Beta) beschreibt die Steigung.
(Beta) beschreibt die Steigung. ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.svg "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.svg "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.svg "Rendered by QuickLaTeX.com")
 .
.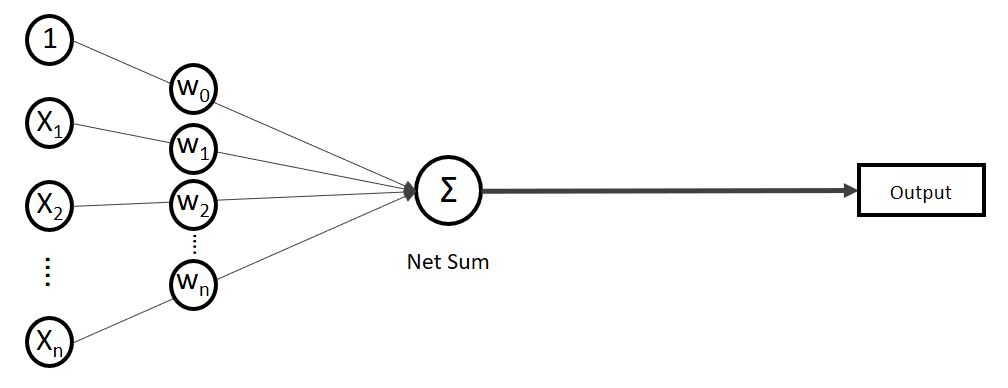
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
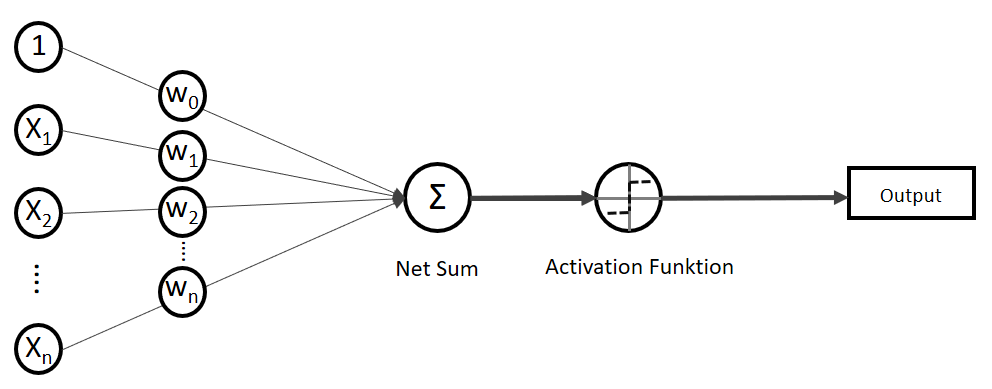
 (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 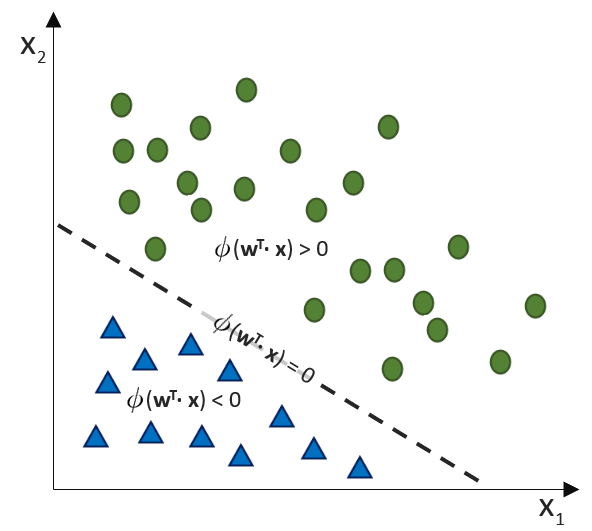
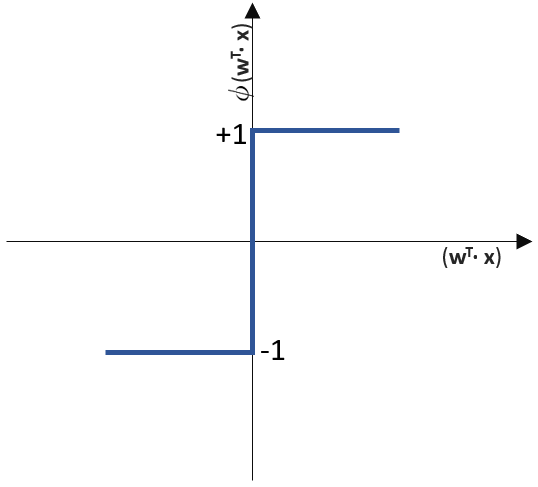
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.svg "Rendered by QuickLaTeX.com")

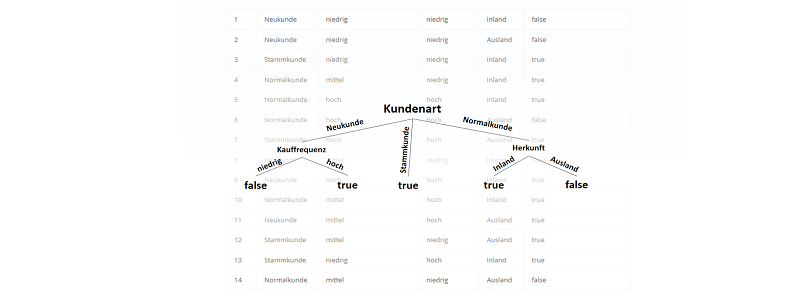
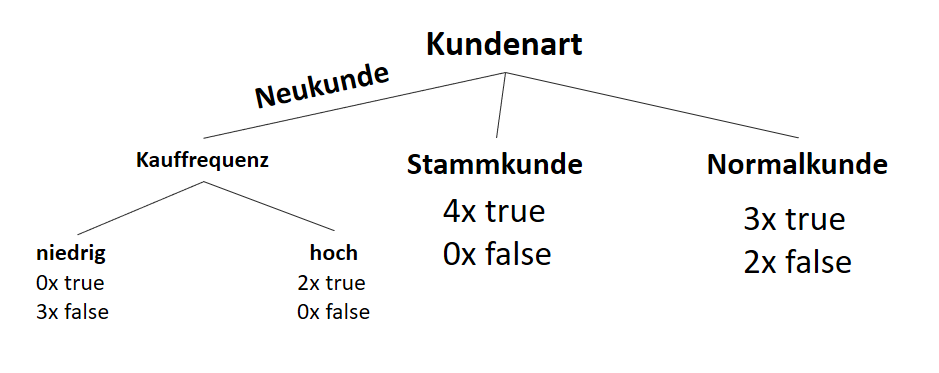
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

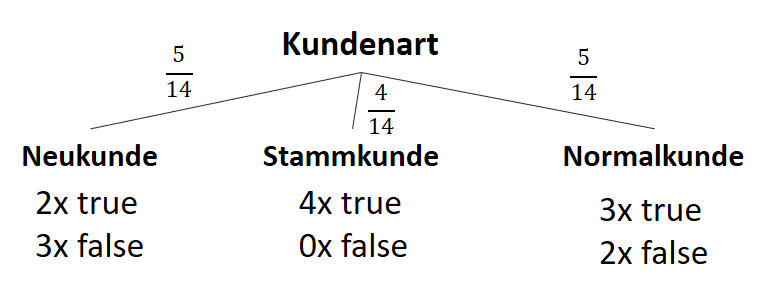



![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.svg "Rendered by QuickLaTeX.com")
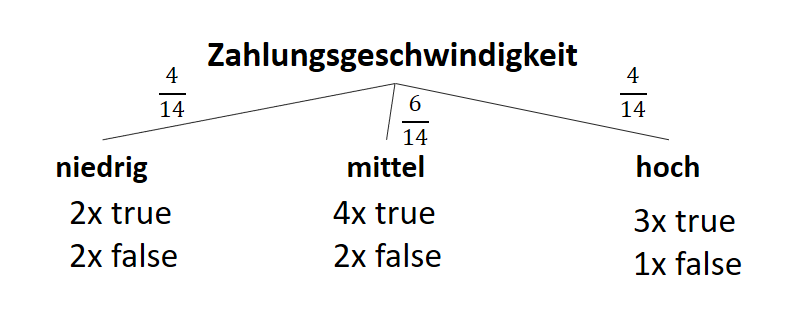



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.svg "Rendered by QuickLaTeX.com")
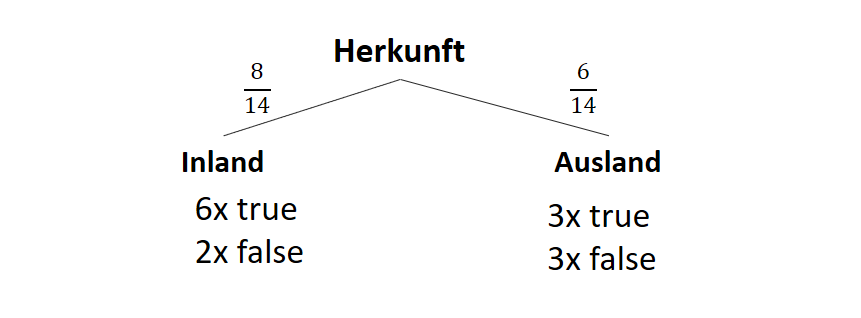


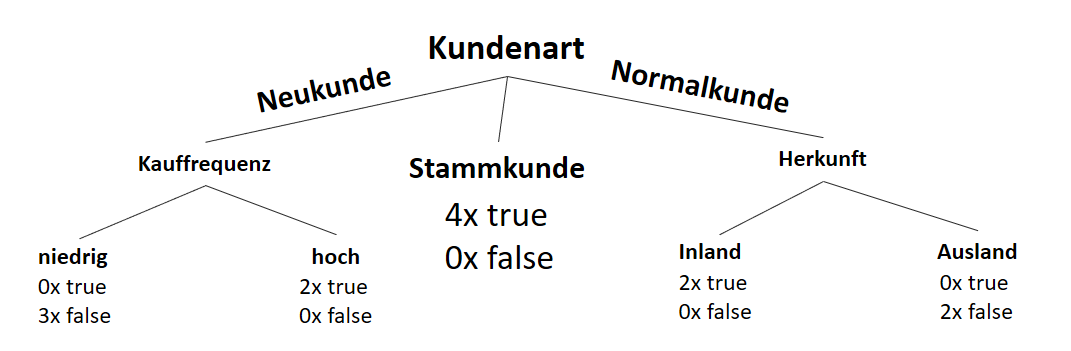
![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.svg "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.svg "Rendered by QuickLaTeX.com")
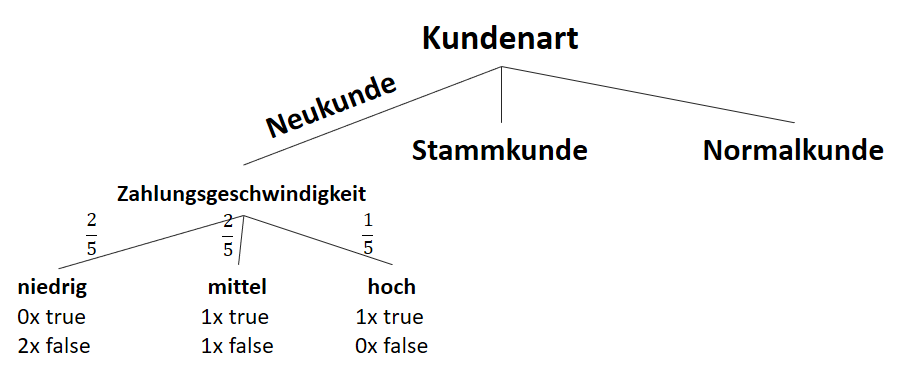



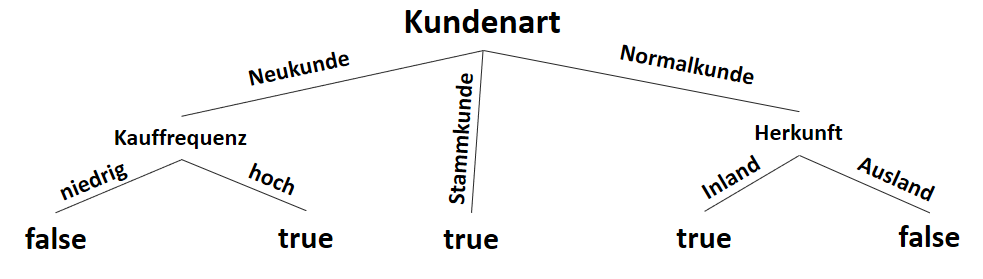
![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.svg "Rendered by QuickLaTeX.com")
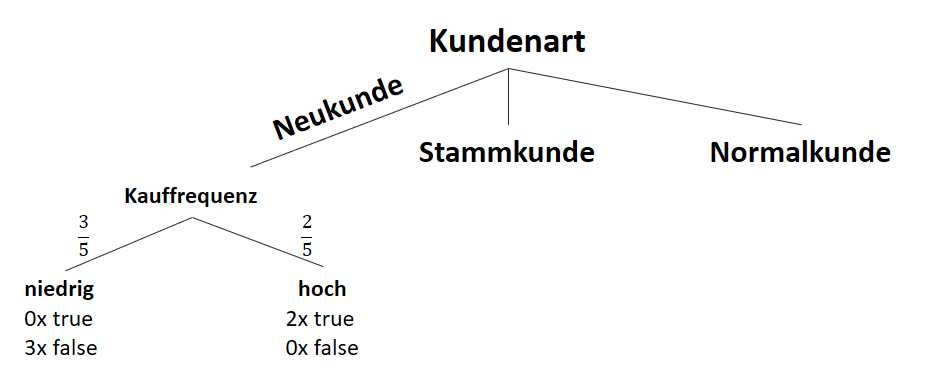
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.svg "Rendered by QuickLaTeX.com")



![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.svg "Rendered by QuickLaTeX.com")