Klaas Wilhelm Bollhoefer ist Chief Data Scientist bei The unbelievable Machine Company (*um), einem Full-Service Dienstleister für Cloud Computing und Big Data aus Berlin. Er übersetzt Business-Anforderungen in kundenspezifische Big Data Lösungen und agiert an der Schnittstelle von Business, IT, Künstlicher Intelligenz und Design. Er ist Community Manager diverser Fachgruppen sowie Mitglied in Beiräten und Jurys zahlreiche r internationaler Big Data Veranstaltungen. Vor seiner Tätigkeit als Chief Data Scientist hatte Herr Bollhöfer bei Pixelpark den Bereich “Beratung und Konzeption” aus der Taufe gehoben und über mehrere Jahre verantwortet, sowie selbständig als strategischer Berater gearbeitet. Er hat Medientechnik, Visual Communication und Philosophie in Köln und Melbourne studiert, hielt Lehraufträge zu Project Governance & Social Data an der TU Berlin, HTW Berlin, der Uni Siegen und der FH Köln inne und schreibt ab und an für diverse Fachpublikationen.
r internationaler Big Data Veranstaltungen. Vor seiner Tätigkeit als Chief Data Scientist hatte Herr Bollhöfer bei Pixelpark den Bereich “Beratung und Konzeption” aus der Taufe gehoben und über mehrere Jahre verantwortet, sowie selbständig als strategischer Berater gearbeitet. Er hat Medientechnik, Visual Communication und Philosophie in Köln und Melbourne studiert, hielt Lehraufträge zu Project Governance & Social Data an der TU Berlin, HTW Berlin, der Uni Siegen und der FH Köln inne und schreibt ab und an für diverse Fachpublikationen.
Data Science Blog: Herr Bollhoefer, welcher Weg hat Sie ins Data Science von The unbelievable Machine (*um) geführt?
Bollhoefer: Das war alles andere als eine gradlinige Geschichte. Ich kannte Ravin Mehta, Gründer und Geschäftsführer von *um noch von der Pixelpark AG, bei der ich von 2000 bis 2009 in verschiedenen Positionen tätig war. Das nächste was Ravin vorhatte, nachdem er in den Cloud-Markt mit *um sehr erfolgreich eingestiegen war, war Big Data. Als ich ihn fragte, was Big Data denn genau sei, meinte er, dass wüsste (damals) noch niemand so genau!
Das war vor etwa vier Jahren und es war die Chance für mich, in dieses neue Thema einzusteigen und zudem eine tolle Gelegenheit – denn eigentlich bin ich ja Ingenieur – für mich, Mathematik wieder aufzufrischen. Ich war der erste Mitarbeiter für Data Science bei *um, habe das Dienstleistungsportfolio maßgeblich mitaufgebaut und konnte mich daher als Chief Data Scientist positionieren. Ich bin allerdings kein Spezialist, sondern Generalist über alles, was man dem Data Science so zuschreiben kann.
Data Science Blog: Welche Branchen profitieren durch Big Data und Data Science gegenwärtig und in naher Zukunft am meisten?
Bollhoefer: Branchen, die schon seit längerer Zeit direkt von Big Data und Data Science profitieren, sind die sogenannten Digital Pure Player, also vorwiegend junge Unternehmen, deren Geschäftsmodelle rein auf digitaler Kommunikation aufbauen sowie eCommerce-Unternehmen. Unter den Fachbereichen profitieren vor allem das Marketing und unter den Geschäftsmodellen ganz besonders das Advertising von Big Data Analytics. Der Begriff Customer Analytics ist längst etabliert.
Zu den Newcomern gehören die Branchen, auf die Deutschland besonders stolz ist: Sowohl die OEMs, als auch die größeren Zulieferer der Automobilbranche setzen mittlerweile vermehrt auf Big Data Analytics, wobei das Supply Chain Management mit Blick auf Logistik und Warenwirtschaft aktuell ganz klar im Vordergrund steht. Es ist hier für uns bereits viel Bewegung spürbar, aber noch lange nicht das Maximum ausgeschöpft. Zumindest ist für viele dieser Unternehmen der Einstieg gefunden.
Auch aus der klassischen Produktion entsteht im Kontext von Industrie 4.0 gerade Nachfrage nach Data Science, wenn auch etwas langsamer als erhofft. Die Potenziale durch die Vernetzung von Produktionsmaschinen sind noch nicht annähernd ausgeschöpft.
Branchen, die meiner Erfahrung nach noch nicht genügend aktiv geworden sind, sind die Chemie- und Pharma-Industrie. Auch Banken und Versicherungen, die ja nicht mit realen Werten, sondern nur mit Daten arbeiten, stehen – abgesehen von einigen Ausnahmen – überraschenderweise noch nicht in den Startlöchern, trotz großer Potenziale.
Data Science Blog: Und welche Branchen sehen Sie durch diese neuen Methoden und Technologien bedroht?
Bollhoefer: Eigentlich mag ich keine Bedrohungsszenarien durch Big Data skizzieren, denn diese führen nur dazu, dass sich Entscheider noch mehr vor dem Thema verschließen und genau dieses Verschließen stellt die eigentliche Bedrohung dar.
Die Chance sollte im Fokus stehen. Die deutsche Industrie, der produzierende Mittelstand, hat mit Big Data und Analytics die Möglichkeit, Fertigungs- und Prozessketten sehr viel weiter zu flexibilisieren und zu optimieren. Die Industrie 4.0 Initiative der deutschen Bundesregierung setzt hier ein ganz wichtiges Zeichen.
Es ist aber auch vollkommen klar, dass die deutsche Automobilindustrie – so wie sie heute existiert – massiv durch Google und Apple und deren Bestrebungen zum vernetzten und autonomen Fahrzeug bedroht ist. Es wird in absehbarer Zeit neue Wettbewerber geben, die klassische Gesamtkonzepte hinterfragen, sie neu und auch anders denken, als wir es heute kennen. Mobilität ist eines dieser Gesamtkonzepte.
Wenn die Kunden darauf anspringen, wird es existenzbedrohend für deutsche Unternehmen. Das ist aber nicht nur durch Big Data getrieben, sondern generell durch immer zügigere Technologiesprünge wie beispielsweise mehr Rechenpower, Batteriekapazität und Vernetzungstechnik.
Data Science Blog: Trotz der vielen Einflüsse von Big Data auf unsere Gesellschaft und Wirtschaft scheint die Berufsbezeichnung Data Scientist nur wenigen ein Begriff zu sein. Wird Data Science als Disziplin in Deutschland noch unterschätzt?
Bollhoefer: Ich denke nicht, dass dieses Berufsbild noch so unbekannt ist. Es ist vollkommen klar, dass es kein Wald- und Wiesen-Job ist, aber großen Unternehmen und Start-Ups ist heute schon sehr bewusst, dass Data Science ein wichtiges Themenfeld ist, ohne das keine Wettbewerbsfähigkeit mehr möglich wäre. Auch sind Profile bereits gut definiert, was ein Data Scientist ist und was man als solcher können sollte.
Data Science Blog: Kleinere Mittelständler haben von Data Science allerdings noch nicht viel gehört, ist das Thema für solche Unternehmen überhaupt von Bedeutung?
Bollhoefer: Kleinere Mittelständler kennen es noch nicht, aber Data Science ist für viele Unternehmen auch kleinerer Größen interessant. Die Werkzeuge, mit denen Data Science betrieben werden kann, sind immer einfacher zu bedienen. Auch Cloud-Lösungen machen diese innovativen Analysen für kleine Unternehmen erschwinglich, so sinkt die Hürde, mit seinen Daten viele der möglichen Potenziale zu realisieren.
Je leistungsfähiger die Werkzeuge werden, desto eher können auch kleinere Unternehmen von diesem Trend profitieren. Die Entwicklung, die gerade stattfindet sorgt für keine Not im Mittelstand, die entsprechenden Entscheider und Geschäftsführer sollten sich jedoch laufend über aktuelle Technologien und Möglichkeiten informieren.
Das ist zumindest meine Einschätzung, die sich jedoch genauso wie die aktuellen Technologien hin und wieder der Situation anpassen muss.
Data Science Blog: Ihre Gruppe Data Science Germany auf Xing.com hat bereits 1.240 Mitglieder und als KeyNote-Speaker sind Sie ebenfalls einer der Frontmänner in Deutschland für Big Data. Was können wir in Deutschland tun, um nicht den Anschluss zu verlieren oder gar auf Augenhöhe des Silicon Valley zu kommen?
Bollhoefer: Nur irgendwelche Gruppen oder Meetups zu organisieren hilft dem Standort Deutschland nicht weiter, auch wenn die Kommunikation untereinander sehr wichtig ist.
In Anbetracht der neuen Möglichkeiten, die wir insbesondere mit Machine Learning eröffnet bekommen, mit den neuen mathematischen Modellen und Technologien, wird sich in Zukunft vieles ändern, das ist vielen Leuten aber noch weitgehend unbekannt. Wir müssen massiv dafür sorgen, dass Transparenz geschaffen wird durch Lehre und Ausbildung.
Es ist jetzt ein enorm wichtiger Zeitpunkt, bei dem sich jedes größere Unternehmen auf eine krasse Lernphase einlassen sollte. Was verbirgt sich hinter künstlicher Intelligenz? Wie funktioniert Machine Learning und Predictive Analytics? Erst wenn das richtig verstanden ist, dann kann die Projektion auf eigene Geschäftsmodelle erfolgen.
Bisher suchten alle nach einem Referenz-Use-Case in der eigenen Branche, den man dann einfach eins zu eins übernehmen kann. Es wird dabei vielfach vergessen, dass diejenigen, die die ersten Schritte bereits gemacht haben, dann schon sehr viel weiter sind als die Nachahmer. Die US-Amerikaner machen es uns vor, sie tun es einfach und lernen daraus. Sie tun es schnell, sie scheitern schnell, erlangen aber auch schnell Erfolge. Dank dieses Mentalitätsaspektes sind sie uns teilweise weit voraus.
Dieser Vorsprung ist nur sehr schwer aufzuholen, da es an der Mentalitätskultur liegt. Eine andere Lern- und Fehlerkultur würde uns sehr gut tun, die kann man aber nicht herbeireden, die muss man entwickeln durch Anreize von der Politik. Industrie 4.0 ist daher eine gute Initiative, denn daran hängen Förderprogramme und Forschungsmotivationen. Das nimmt die Unternehmer aber nicht aus der Verantwortung, in dieser Sache am Ball zu bleiben.
Data Science Blog: Wie sieht der Arbeitsalltag als Data Scientist nach dem morgendlichen Café bis zum Feierabend aus?
Bollhoefer: Höchst unterschiedlich, denn Data Science umfasst vielfältige Tätigkeiten.
Der Berufsalltag findet überwiegend am Computer statt, denn heutzutage heißt Data Science vor allem Programmieren. Als Data Scientist setzten wir mit Programmierung Use Cases um, dabei nutzen wir meistens Python oder R, es können aber auch andere Programmiersprachen eingesetzt werden.
Viele Tätigkeiten verlangen Kreativität, Stift und Zettel sowie viel Austausch mit Kollegen. Nur wenige Arbeitsschritte lassen sich fest planen, iteratives bzw. agiles Vorgehen ist notwendig.
Kernaufgabe und Höhepunkt unserer Arbeit sind die Messung von Qualitätskriterien sowie das Trainieren und Optimieren mathematischer Modelle. Das sogenannte Feature-Engineering, also das Herausarbeiten relevanter Features (individuelle messbare Eigenschaften eines Objektes oder eines Sachverhaltes) bildet die dafür notwendige Basis und macht in der Praxis häufig bis zu 80% unserer Arbeitszeit aus.
Data Science Blog: Data Science ist Analyse-Arbeit und es geht viel um Generierung und Vermittlung von Wissen. Sind gute Data Scientists Ihrer Erfahrung nach tendenziell eher kommunikative Beratertypen oder introvertierte Nerds?
Bollhoefer: Im Idealfall sollte ein Data Scientist in gewisser Weise beides sein, also fifty/fifty. Das ist zumindest das, was es eigentlich bräuchte, auch wenn solche Leute nur schwer zu finden sind.
Den idealen Data Scientist gibt es wohl eher nicht, dafür arbeiten wir in Teams. Data Science ist Teamsport. Am erfolgreichsten sind Teams mit eben diesen Mindsets der kommunikativen Beratertypen mit Überzeugungsfähigkeit und den autodidaktischen Nerds mit viel tiefgehendem Wissen in Mathematik und Informatik.
Data Science Blog: Für alle Studenten, die demnächst ihren Bachelor, beispielsweise in Informatik, Mathematik oder Wirtschaftslehre, abgeschlossen haben, was würden sie diesen jungen Damen und Herren raten, wie sie gute Data Scientists werden können?
Bollhoefer: Wer operativ schnell tätig werden möchte, sollte auf den Master verzichten, denn wie die Nachfrage nach Data Science in drei Jahren aussehen wird, weiß niemand. Es ist ganz wichtig, jetzt zu starten und nicht in drei Jahren.
Der Weg ist zurzeit über Kontakte am leichtesten. Wer die nicht hat, kann diese schnell aufbauen, dazu einfach ein paar der vielen Meetups besuchen, über Social Media in der Szene netzwerken, sich Vorträge anhören und dadurch auch gleichzeitig in Erfahrung bringen, wie Data Scientists denken, arbeiten und was das typische Jobprofil ausmacht. Um der Thematik, den Tools und Methoden näher zu kommen, gibt es Kurse bei Coursera, Udacity, Kaggle Competitions, so kann man selber mal praxisnahe Probleme lösen. Zwei oder drei Zertifikate von diesen Anlaufstellen helfen bei der Jobsuche weiter.


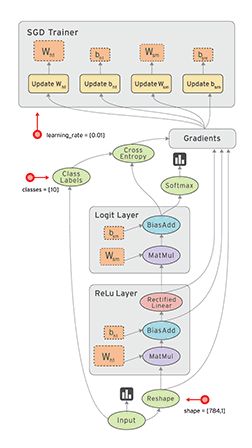 gif
gif









 (Theta) multipliziert und die Ergebnisse aufsummiert. Das Zwischenergebnis ist die Aktivierungsstärke z:
(Theta) multipliziert und die Ergebnisse aufsummiert. Das Zwischenergebnis ist die Aktivierungsstärke z:![\[ z = X_0 \cdot \theta_0 + X_1 \cdot \theta_1 + X_2 \cdot \theta_2 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-49288c71db69e864888f642613627b1b_l3.svg "Rendered by QuickLaTeX.com")

![\[ sigmoid(z) = \frac{1}{1+e^{-z}} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-d02636a1d3140b9e8e9dc48a1c5c395a_l3.svg "Rendered by QuickLaTeX.com")
![\[ Y = sigmoid(X\theta) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-924f70586a4f97cd4aa0dceea3f2b047_l3.svg "Rendered by QuickLaTeX.com")