Wie wurde aus Business Intelligence eigentlich Big Data? Aus Sicht der Unternehmen herrscht große Verwirrung darüber, welcher Begriff nun eigentlich was bedeutet und was dieser für das Unternehmen bedeutet.
Es stellt sic h die Frage, ob Business Intelligence nun veraltet ist und von Big Data Analytics ersetzt wird oder ob Big Data Analytics die Weiterführung von Business Intelligence darstellt. Darüber gibt es unterschiedliche Meinungen, aber die Evolution, die sich über das letzte Jahrzehnt von einfachen Reports zu den aktuellen Möglichkeiten im Bereich von Big Data Analytics erstreckt, können wir uns recht deutlich vor Augen führen.
h die Frage, ob Business Intelligence nun veraltet ist und von Big Data Analytics ersetzt wird oder ob Big Data Analytics die Weiterführung von Business Intelligence darstellt. Darüber gibt es unterschiedliche Meinungen, aber die Evolution, die sich über das letzte Jahrzehnt von einfachen Reports zu den aktuellen Möglichkeiten im Bereich von Big Data Analytics erstreckt, können wir uns recht deutlich vor Augen führen.
Raw Data
Rohdaten stellen das “Material” da, welches die Grundlage für jegliche Analysen bildet. Auch wenn Rohdaten erstmal nicht besonders erwähnenswert klingen, so existiert viel Wissenschaft und Business rund um Rohdaten, denn deren Speicherung kann durchaus sehr komplex sein. Abhängig von Art und Struktur der Daten kommen hier unterschiedliche relationale und nicht-relationale (NoSQL) Datenbanken zum Einsatz. Aktueller Trend ist ferner die InMemory-Datenhaltung, die unabhängig von der eigentlichen Datenbankstruktur möglich ist.
Das Angebot an kostenpflichtigen und kostenfreien Datenbanken ist bereits beinahe unüberschaubar groß. Beispielsweise können die relationalen Datenbanken MariaDB, Oracle DB oder PostgreeSQL genannt werden. Neo4J (graphenorientiert), MongoDB (dokumentenorientiert), Apache Cassandra und SAP HANA (beide spaltenorientiert) sowie Redis (Key-Value-Datenbank) sind hingegen Beispiele für sogenannte NoSQL-Datenbanken.
Clean Data
Bereinigte Daten sollte heutzutage eine Selbstverständlichkeit sein? Weit gefehlt! Aus Erfahrung kann ich sagen, dass eine wirklich saubere Datenbasis die Ausnahme darstellt. Die Regel sind Inkonsistenzen zwischen relationalen Daten, Formatfehler, leere Datenfelder (die nicht leer sein dürften) usw. Mit der Bereinigung der Daten haben zurzeit noch alle Unternehmen und Institute zu kämpfen, sofern sie sich diesen Kampf überhaupt stellen.
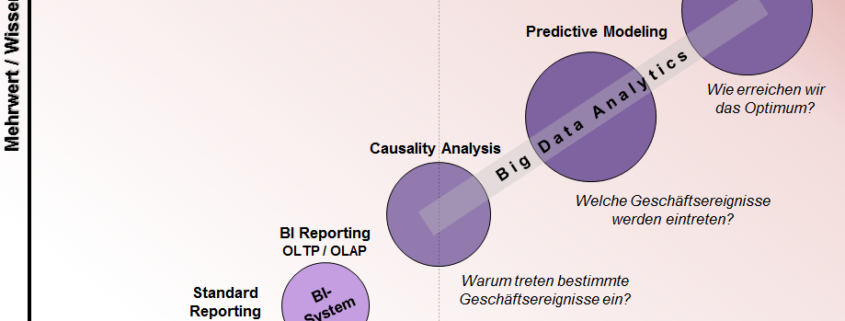
Standard-Reporting
Reporting in Excel gibt es nun schon mindestens zwei Jahrzehnte und wird auch heute noch (mehr) betrieben. Mit der Etablierung von ERP-Systemen, beispielsweise Microsoft Dynamics NAV oder SAP ERP, fand auch das automatisierte Reporting Einzug in die deutschen Unternehmen. Heute bieten alle ERP-Systeme (bzw. CRM-, SRM-, PLM-Systeme) zumindest grundlegende Reporting-Funktionen in Form von Tabellen, Balken- und Kuchendiagrammen. Diese Reports sind allerdings in der Regel wenig anpassbar durch die Anwender.
Business Intelligence
Kurz nach dem Einsetzen des Wachstums auf dem Markt der ERP-Systeme lebte auch das Business Intelligence mit den schönen grafischen Dashboards auf. BI bedient sich dabei überwiegend aus den Daten des ERP-Systems. Ferner werden noch weitere – vorwiegend unternehmensinterne – Daten hinzugezogen, z. B. aus Excel-Dateien. Der Erfolg von Business Intelligence kam insbesondere mit den Dashboards und einer einfachen Bedienbarkeit, denn BI wurde für ERP-Anwender gemacht.
Im Bereich BI hatte QlikTech mit der Software QlikView einen Volltreffer gelandet, denn diese hat den Weg in viele Unternehmen als BI-Lösung gefunden.
(Big) Data Analytics – Causality Analytics
Data Analytics geht einen Schritt weiter als BI, denn hier geht es nicht nur darum zu analysieren, welche Ereignisse eingetreten sind, sondern auch warum. Data Analytics ist sehr viel flexibler als BI und wird tendenziell eher programmiert als zusammengeklickt. Hier spielen Daten aus externen Datenquellen (z. B. dem Internet) oftmals eine wichtige Rolle und machen daraus Big Data. Zudem kommt vermehrt Statistik und Machine Learning zum Einsatz um Kausalitäten aus den vielfältigen Datenmengen
Gearbeitet wird beispielsweise mit den Programmiersprachen R und Python, aber auch mit IBM SPSS oder SAS Advanced Analytics.
Predictive Modeling
Prädiktive Analysemodelle gehen noch einen Schritt weiter, denn nach der Frage nach dem Warum stellt sich für viele Geschäftszwecke die Frage, wann es wieder geschehen wird. Predictive Analytics gilt als eine Königsdisziplin, arbeitet mit induktiver Statistik und scheint mit der Einbindung von Big Data beinahe unbegrenzte Möglichkeiten der Vorhersage z. B. von Umsätzen, Lagerbeständen und Maschinenabnutzung zu bieten.
Optimierung
Der letzte Schritt in der Evolution ist die Simulation von allen Stellschrauben mit dem Ziel zur Optimierung des Systems (z. B. das Geschäft, die Fabrik oder die Maschine). Was in der Industriebetriebswirtschaft schon lange als Operations Research bekannt ist, wird mit Big Data Analytics einen neuen Aufschwung erfahren, denn hier werden immer mehr relevante Stellschrauben identifiziert und berücksichtigt werden können.
 gif
gif