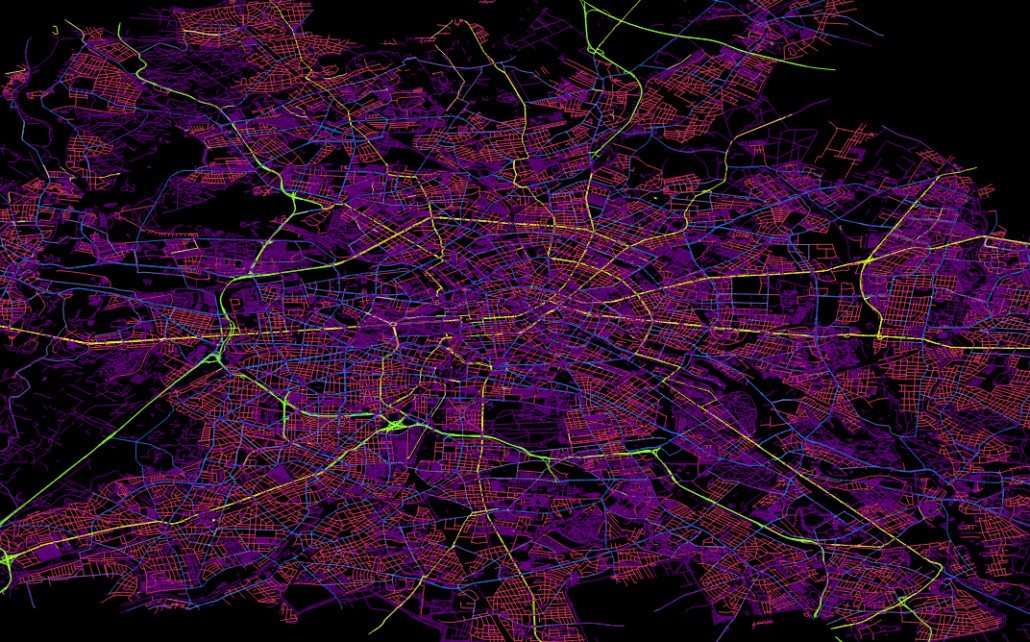
Allgemeines über Geodaten
Dieser Artikel ist der Auftakt in einer Artikelserie zum Thema “Geodatenanalyse”.
Von den vielen Arten an Datensätzen, die öffentlich im Internet verfügbar sind, bin ich in letzter Zeit vermehrt über eine besonders interessante Gruppe gestolpert, die sich gleich für mehrere Zwecke nutzen lassen: Geodaten.
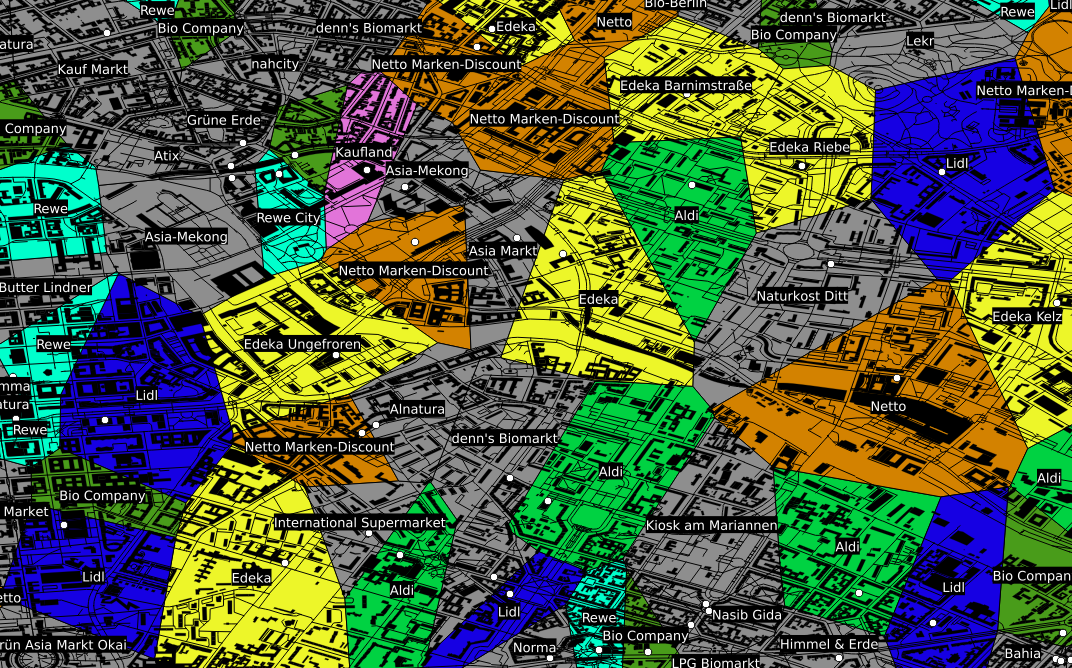
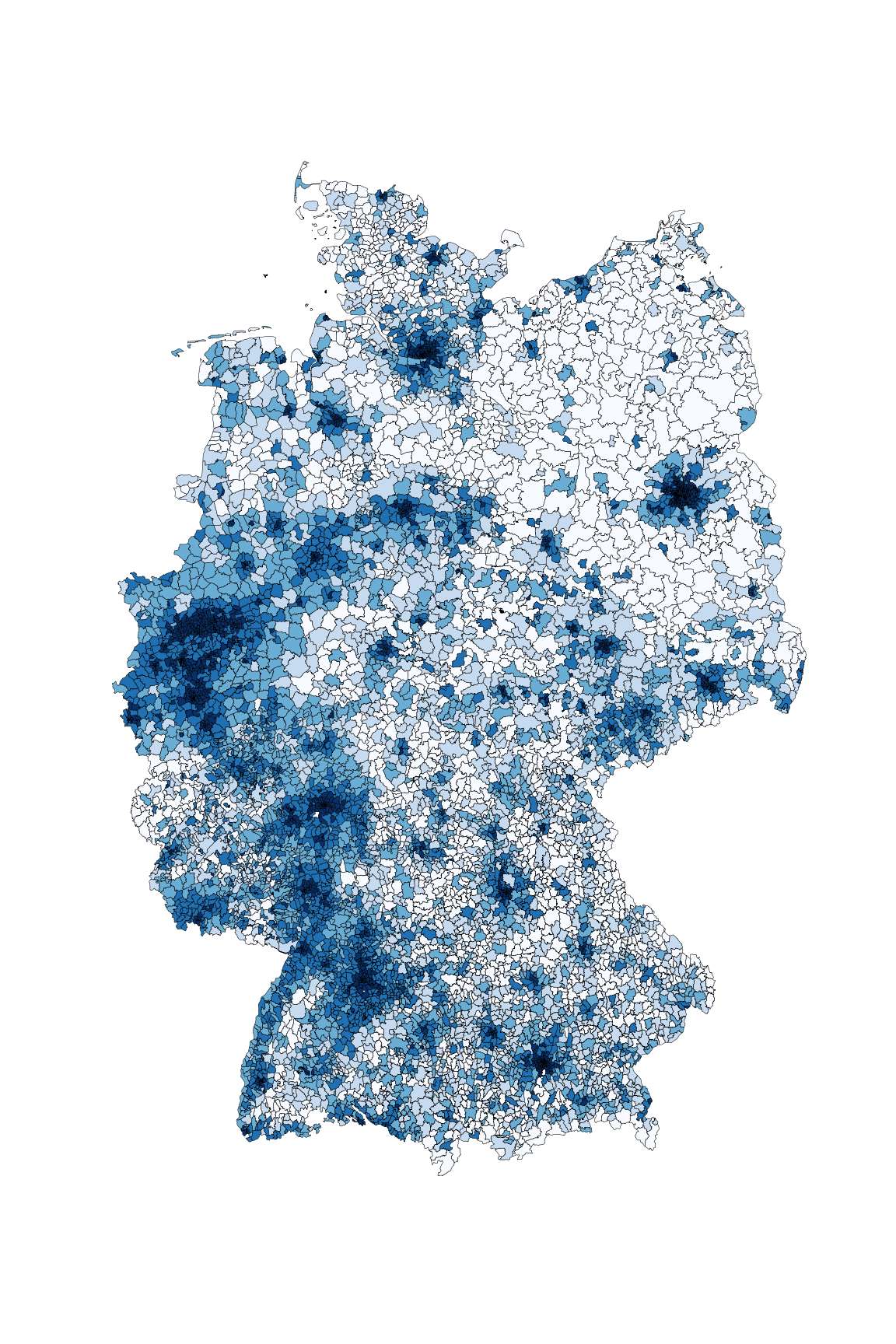
Ein anderes Beispiel, das für die Datenauswertung interessant ist, ist die kartographische Auswertung von Postleitzahlen. Diese sind in fast jedem Datensatz zu Kunden, Lieferanten, ect. vorhanden, bilden jedoch weder eine ordinale, noch eine sinnvolle kategorische Größe, da es viele tausend verschiedene gibt. Zudem ist auch eine einfache Gruppierung in gröbere Kategorien wie beispielsweise Postleitzahlen des Schemas 1xxxx oft kaum sinnvoll, da diese in aller Regel kein sinnvolles Mapping auf z. B. politische Gebiete – wie beispielsweise Bundesländer – zulassen. Ein Ausweg aus diesem Dilemma ist eine einfache kartographische Übersicht, welche die einzelnen Postleitzahlengebiete in einer Farbskala zeigt.
- Wer erst anfängt, sich mit Datenbanken zu beschäftigen, findet mit Straßen, Postleitzahlen und Ländern einen deutlich einfacheren und vor allem besser verständlichen Zugang zu SQL als mit abstrakten Größen und Nummern wie ProductID, CustomerID und AdressID. Zudem lassen sich Geodaten nebenbei bemerkt mittels so genannter GeoInformationSystems (*gis-Programme), erstaunlich einfach und ansprechend plotten.
- Wer sich mit SQL bereits ein wenig auskennt, kann mit den (beispielsweise von Spatialite oder PostGIS) bereitgestellten SQL-Funktionen eine ganze Menge über Datenbanken sowie deren Möglichkeiten – aber auch über deren Grenzen – erfahren.
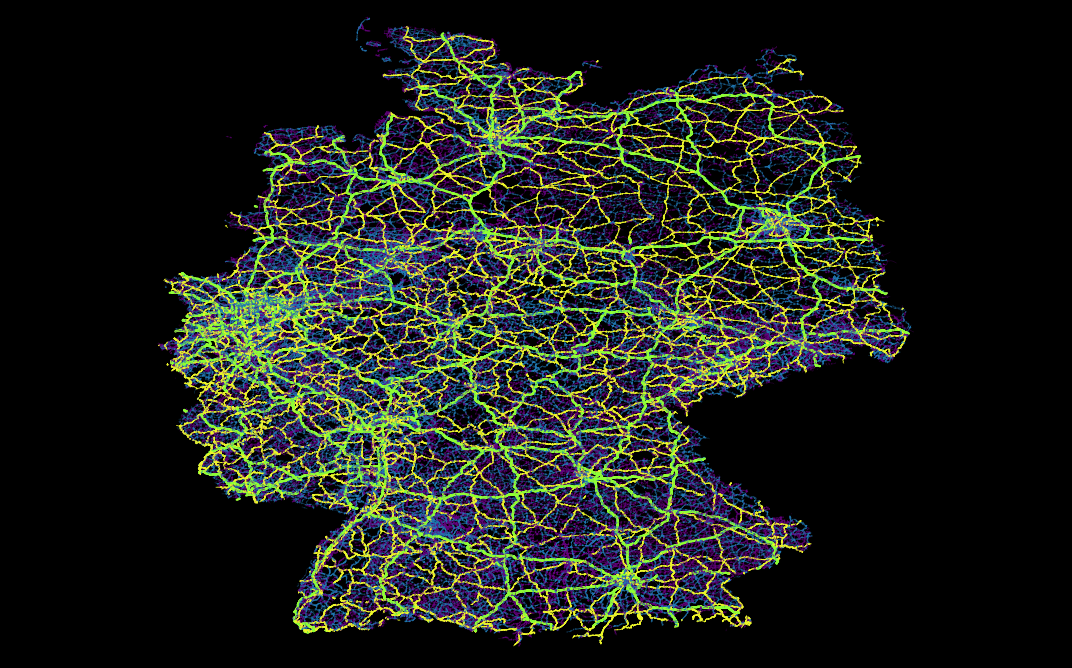
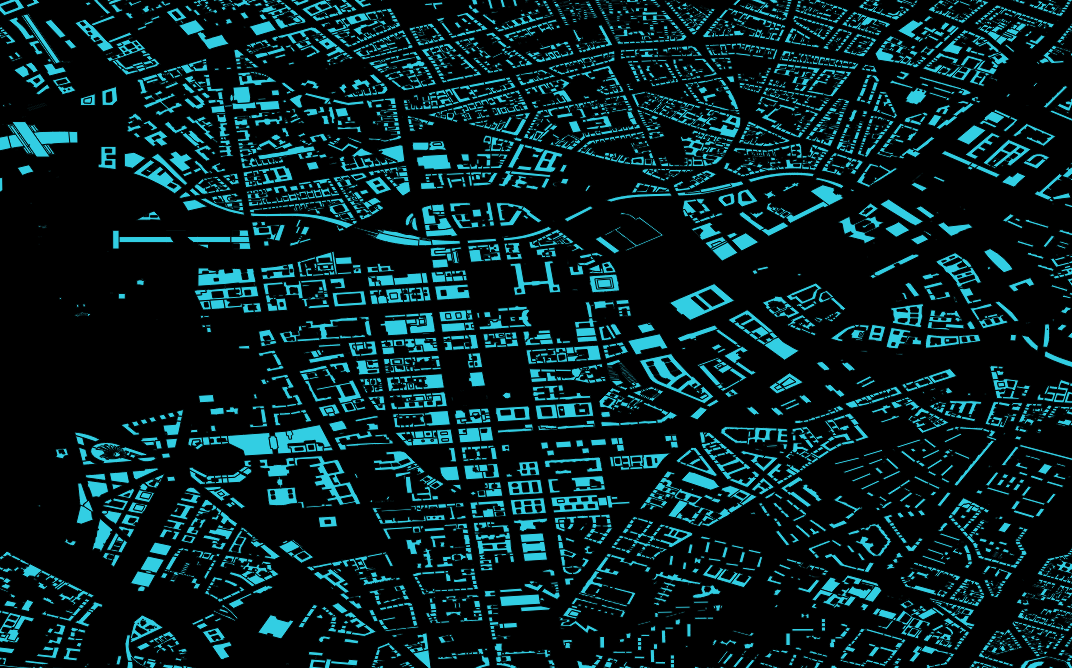
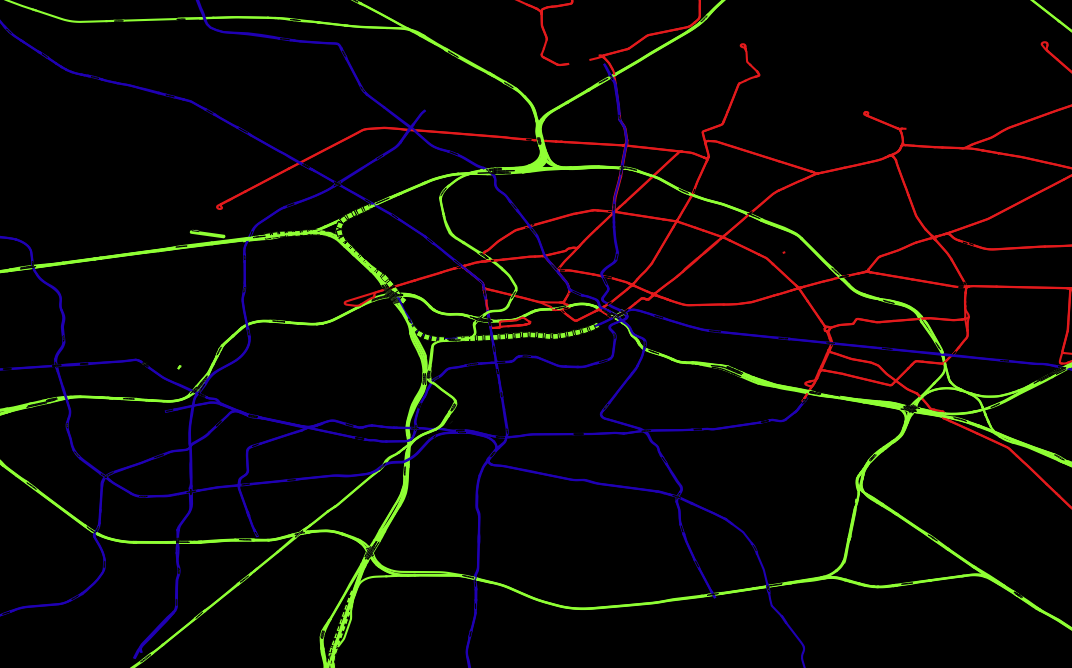
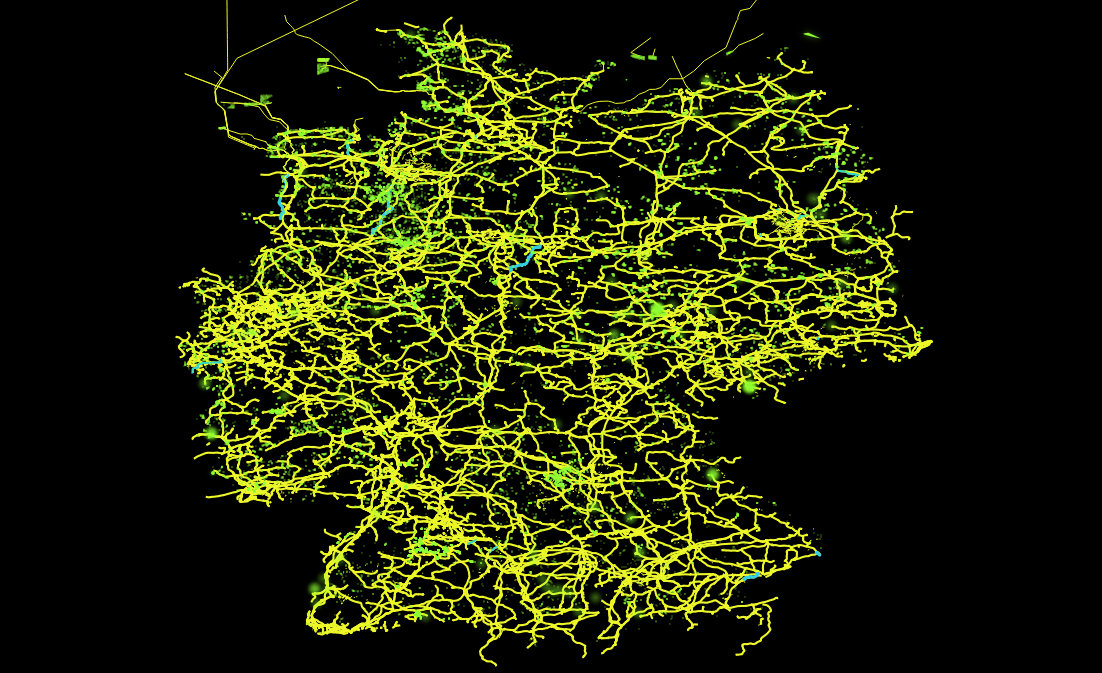
- Für wen relationale Datenbanken sowie deren Funktionen schon lange nichts Neues mehr darstellen, kann sich hier (selbst mit dem eigenen Notebook) erstaunlich einfach in das Thema “Bug Data” einarbeiten, da die Menge an öffentlich vorhandenen Geodaten z.B. des OpenStreetMaps-Projektes selbst in optimal gepackten Format vielen Dutzend GB entsprechen. Gerade die Möglichkeit, die viele *gis-Programme wie beispielsweise QGIS bieten, nämlich Straßen-, Schienen- und Stromnetze “on-the-fly” zu plotten, macht die Bedeutung von richtig oder falsch gesetzten Indices in verschiedenen Datenbanken allein anhand der Geschwindigkeit mit der sich die Plots aufbauen sehr eindrucksvoll deutlich.
Christopher Kipp
Christopher Kipp ist Data Scientist bei der DATANOMIQ GmbH. Der studierte Chemiker befasst sich intensiv mit programmatischen und statistischen Lösungen im Bereich Data Science und Data Engineering.







Leave a Reply
Want to join the discussion?Feel free to contribute!