Toolkits & Services für Semantische Textanalysen
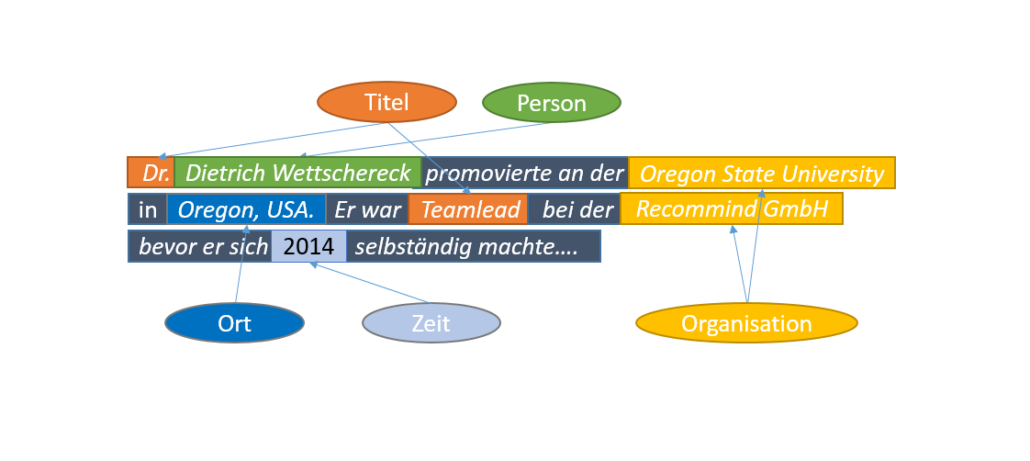
Named Entity Recognition ist ein Teilgebiet von Information Extraction. Ziel von Information Extraction ist die Gewinnung semantischer Informationen aus Texten (im Gegensatz zum verwandten Gebiet des Information Retrieval, bei dem es um das möglichst intelligente Finden von Informationen, die u.U. vorab mit Information Extraction gewonnen wurden, geht). Named Entity Recognition (kurz NER) bezeichnet die Erkennung von Entitäten wie z.B. Personen, Organisationen oder Orten in Texten.
[box]Beispiel:
“Albert Einstein war ein theoretischer Physiker, der am 14. März 1879 in Ulm geboren wurde. Er erhielt 1921 den Nobelpreis für Physik. Isaac Newton, Einstein und Stephen Hawking werden oft als die größten Physiker seit der Antike bezeichnet.”[/box]
Die Disambiguierung von Entitäten ist ein weiterer wichtiger Schritt auf dem Weg zu einem semantischen Verständnis von Texten. Wenn man so in obigem Text erkennen kann, dass “Albert Einstein“, “Er” und “Einstein” die gleiche Person bezeichnen, so kann ein Analyseverfahren z.B. daraus schließen, dass in diesem Text Einstein eine wichtigere Rolle spielt, als Newton, der nur einmal erwähnt wurde. Die Hyperlinks hinter den jeweiligen Entitäten zeigen eine Möglichkeit der semantischen Anreicherung von Texten an – in diesem Fall wurden die Entitäten mit entsprechenden Einträgen bei DBpedia automatisch verlinkt.
Named Entity Recognition dient vorrangig zwei Zwecken:
- Anreicherung von Texten mit Metadaten
- Abstraktion von Texten zur besseren Erkennung von Mustern
Punkt 1 dient direkt dem Information Retrieval. Anwender können so z.B. gezielt nach bestimmten Personen suchen, ohne alle möglichen Schreibweisen oder Berufsbezeichnungen auflisten zu müssen.
Punkt 2 dient der Vorverarbeitung von Texten als Input für Machine Learning Verfahren. So ist es (je nach Anwendung!) oft nicht von Bedeutung, welche Person, welcher Ort oder auch welche Uhrzeit in einem Text steht sondern nur die Tatsache, dass Personen, Orte oder Zeiten erwähnt wurden.
Sirrus Shakeri veranschaulicht die zentrale Bedeutung semantischer Analyse in seinem Beitrag From Big Data to Intelligent Applications:

Abbildung 1: Von Big Data zu Intelligent Applications von Cirrus Shakeri
Sein “Semantic Graph” setzt voraus, dass Entitäten mittels “Natural Language Processing” erkannt und zueinander in Beziehung gesetzt wurden.
Es ist interessant zu vermerken, dass Natural Language Processing und Data Mining / Machine Learning über viele Jahre als Alternativen zueinander und nicht als Ergänzungen voneinander gesehen wurden. In der Tat springen die meisten Vorgehensmodelle heutzutage von “Data Preparation” zu “Machine Reasoning”. Wir argumentieren, dass sich in vielen Anwendungen, die auf unstrukturierten Daten basieren, signifikante Qualitätsverbesserungen erzielen lassen, wenn man zumindest NER (inklusive Disambiguierung) in die Pipeline mit einbezieht.
Toolkits und Services für NER
Es existiert eine Vielzahl von Toolkits für Natural Language Processing, die Sie mehr oder weniger direkt in Ihre Programme einbinden können. Exemplarisch seien drei Toolkits für Java, Python und R erwähnt:
- Der Stanford Named Entity Recognizer (Java) ist Teil eines mächtigen NLP Toolkits, das an der Stanford University entwickelt wurde. Es gibt neben anderen Sprachen auch vortrainierte Modelle für Deutsch.
- Das Natural Language Toolkit (Python) ist ein typisches Open Source Community Projekt mit hunderten von Erweiterungen und Modellen für NLP.
- Auch für R-User gibt es entsprechende Packages z.B. die R NLP Package (siehe auch https://rpubs.com/lmullen/nlp-chapter für weitere Hinweise)
Diese Toolkits enthalten Modelle, die auf Korpora für die jeweils unterstützten Sprachen trainiert wurden. Sie haben den Vorteil, dass sie auch vollkommen neue Entitäten erkennen können (wie z.B. neue Politiker oder Fernsehstars, die zur Trainingszeit noch unbekannt waren). Je nach Einstellung haben diese Systeme aber auch eine relativ hohe Falsch-Positiv-Rate.
Wer NER nur ausprobieren möchte oder lediglich gelegentlich kleinere Texte zu annotieren hat, sei auf die folgenden Web Services verwiesen, die auch jeweils eine REST-Schnittstelle anbieten.
DBpedia
Das DBpedia Projekt nutzt die strukturierten Informationen der verschieden-sprachigen Wikipedia Sites für den Spotlight Service. Im Unterschied zu den reinen Toolkits nutzen die nun genannten Werkzeuge zusätzlich zu den trainierten Modellen eine Wissensbasis zur Verringerung der Falsch-Positiv-Rate. Die mehrsprachige Version unter http://dbpedia-spotlight.github.io/demo zeigt die Möglichkeiten des Systems auf. Wählen Sie unter “Language” “German“) und dann über “SELECT TYPES…” die zu annotierenden Entitätstypen. Ein Beispieltext wird automatisch eingefügt. Sie können ihn natürlich durch beliebige andere Texte ersetzen. Im folgenden Beispiel wurden “Organisation”, “Person”, und “Place“ ausgewählt:

Abbildung 2: DBpedia Demo (de.dbpedia.org)
Die erkannten Entitäten werden direkt mit ihren DBpedia Datenbankeinträgen verlinkt. Im Beispiel wurden die Orte Berlin, Brandenburg und Preußen sowie die Organisationen Deutsches Reich, Deutsche Demokratische Republik, Deutscher Bundestag und Bundesrat erkannt. Personen wurden in dem Beispieltext nicht erkannt. Die Frage, ob man “Sitz des Bundespräsidenten” als Ort (Sitz), Organisation (das Amt des Bundespräsidenten) und / oder Person (der Bundespräsident) bezeichnen sollte, hängt durchaus vom Anwendungsszenario ab.
OpeNER
Das OpeNER Projekt ist das Ergebnis eines europäischen Forschungsprojekts und erweitert die Funktionalität von DBpedia Spotlight mit weiteren semantischen Analysen. Die Demo unter http://demo2-opener.rhcloud.com/welcome.action (Tab “Live Analysis Demo“, “Named Entity Recognition and Classification” und “Named Entity Linking” auswählen und “Analyse” drücken, dann auf der rechten Seite das Tab “NERC” anwählen) ergibt für den gleichen Beispieltext:

Abbildung 3: OpeNER Projekt (opener-project.eu)
Organisationen sind blau hinterlegt, während Orte orange markiert werden. Auch hier werden erkannte Entitäten mit ihren DBpedia Datenbankeinträgen verknüpft. Die Bedeutung dieser Verknüpfung erkennt man wenn man auf das Tab “Map” wechselt. Berlin wurde als Ort erkannt und über die Geo-Koordinaten (geo:long = 13.4083, geo.lat = 52.5186) im DBpedia Eintrag von Berlin konnte das Wort “Berlin” aus obigem Text automatisch auf der Weltkarte referenziert werden.
Es gibt eine Vielzahl weiterer Services für NLP wie z.B. OpenCalais. Einige dieser Services bieten bestimmte Funktionalitäten (wie z.B. Sentiment Analysis) oder andere Sprachen neben Englisch nur gegen eine Gebühr an.
Listen Tagger
Der Vollständigkeit halber sei noch erwähnt, dass in den meisten Anwendungsszenarien die oben genannten Werkzeuge durch sogenannte Listen-Tagger (englisch Dictionary Tagger) ergänzt werden. Diese Tagger verwenden Listen von Personen, Organisationen oder auch Marken, Bauteilen, Produktbezeichnern oder beliebigen anderen Gruppen von Entitäten. Listen-Tagger arbeiten entweder unabhängig von den oben genannten statistischen Taggern (wie z.B. dem Standford Tagger) oder nachgeschaltet. Im ersten Fall markieren diese Tagger alle Vorkommen bestimmter Worte im Text (z.B. „Zalando“ kann so direkt als Modemarke erkannt werden). Im zweiten Fall werden die Listen genutzt, um die statistisch erkannten Entitäten zu verifizieren. So könnte z.B. der Vorschlag des statistischen Taggers automatisch akzeptiert werden wenn die vorgeschlagene Person auch in der Liste gefunden wird. Ist die Person jedoch noch nicht in der Liste enthalten, dann könnte ein Mitarbeiter gebeten werden, diesen Vorschlag zu bestätigen oder zu verwerfen. Im Falle einer Bestätigung wird die neu erkannte Person dann in die Personenliste aufgenommen während sie im Falle einer Ablehnung in eine Negativliste übernommen werden könnte damit dieser Vorschlag in Zukunft automatisch unterdrückt wird.
Regular Expression Tagger
Manche Entitätstypen folgen klaren Mustern und können mit hoher Zuverlässigkeit durch reguläre Ausdrücke erkannt werden. Hierzu zählen z.B. Kreditkarten- oder Telefon- oder Versicherungsnummern aber auch in vielen Fällen Bauteilbezeichner oder andere firmeninterne Identifikatoren.
Fazit
Natural Language Processing und insbesondere Named Entity Recognition und Disambiguierung sollte Teil der Werkzeugkiste eines jeden Anwenders bei der Analyse von unstrukturierten Daten sein. Es existieren mehrere mächtige Toolkits und Services, die allerdings je nach Anwendungsgebiet kombiniert und verfeinert werden müssen. So erkennt DBpedia Spotlight nur Entitäten, die auch einen Wikipedia Eintrag haben, kann für diese aber reichhaltige Metadaten liefern. Der Stanford Tagger hingegen kann auch vollkommen unbekannte Personennamen aus dem textuellen Kontext erkennen, hat aber bei manchen Texten eine relativ hohe Falsch-Positiv-Rate. Eine Kombination der beiden Technologien und anwendungsspezifischen Listen von Entitäten kann daher zu qualitativ sehr hochwertigen Ergebnissen führen.
Dr. Dietrich Wettschereck
Dietrich Wettschereck (PhD) ist seit 30 Jahren als Forscher, Unternehmer, Programmierer und Berater in den Bereichen KI und Machine Learning tätig. Seine wissenschaftliche Karriere beendete er 1997 mit über 20 Publikationen (u.a. im Machine Learning Journal, der NIPS und dem Artificial Intelligence Review Journal). Seitdem hat er eine Vielzahl von innovativen Analyse- und Entwicklungsprojekten sowohl für Konzerne als auch Start-Ups erfolgreich umgesetzt. Seit 2018 ist Dietrich Wettschereck Head of AI bei der tarent solutions GmbH, einer Technologieagentur mit Sitz in Bonn, Köln, Berlin und Bukarest.








Leave a Reply
Want to join the discussion?Feel free to contribute!