Welche Rolle spielt Big Data in der Versicherungsbranche? Ist Data Science bereits Alltag in einer Versicherung? Wenn ja, welche Analysen werden bereits durchgeführt?
Hierzu haben wir den Datenarchitekt Norbert Schattner befragt und sehr interessante Antworten erhalten:
Norbert Schattner ist Informations- & Datenarchitekt bei der Helsana AG in der Schweiz. Die Helsana AG ist ein Versicherungskonzern mit Schwerpunkt auf Kranken- und Unfallversicherung. Der Konzern beschäftigt rund 3.500 Mitarbeiter und macht 5,5 Milliarden Franken Umsatz.
Data Science Blog: Herr Schattner, welcher Weg hat Sie in die Datenarchitektur und in das Data Warehouses bei Helsana geführt?
Schattner: Ich habe in meiner Berufslaufbahn kontinuierlich im Umfeld Business Intelligence und Data Warehousing gearbeitet und konnte mich zum Experten für unternehmensübergreifende Architektur von Daten- und Informationsflüssen weiter entwickeln.
Nachdem ich eine Zeit lang als Senior Consultant für eine Unternehmensberatung tätig war, bin ich zur UBS Bank nach Zürich gegangen und war für das Rollout Management im Data Warehouse Kontext tätig. Schlussendlich wechselte ich dann zur Helsana Versicherungsgruppe, denn dort konnte ich in ein Projekt einsteigen, bei dem ich die Datenarchitektur von Grund auf neu aufbauen durfte. Durch dieses Projekte hatte ich die Gelegenheit eine nachhaltige Datenarchitektur von Grund auf aufzubauen und in weiteren Grossprojekten mitwirken.
Data Science Blog: Die Medien überschlagen sich in letzter Zeit geradezu beim Thema Big Data, dabei scheint jede Branche diesen Begriff für sich selbst zu interpretieren. Was bedeutet Big Data für Sie? Wie sieht Big Data aus der Perspektive der Versicherungsbranche aus?
Schattner: Big Data ist sicherlich ein großes Schlagwort der IT geworden. In der Versicherungsbranche ist Big Data ein großes und sehr aktuelles Thema. Auch die Helsana spricht von Big Data und versteht darunter große und verteilte Mengen an strukturierten und unstrukturierten Daten.
Zum gegenwärtigen Zeitpunkt sind die wichtigsten und größten Datenbestände der Helsana in strukturierter Form vorliegend. Strukturierte Geschäftsdaten sind für uns der wichtigste Anteil vom Big Data Kuchen. Oftmals gehen in der Diskussion von Big Data die strukturierten Daten unter, obwohl auch diese eine enorme Menge und Vielfalt darstellen und somit zur Herausforderung werden können – ganz egal, was aktuelle Technologieanbieter hier versprechen mögen.
In der nahen Zukunft werden auch Social Media Daten wichtig, beispielsweise um die Kundenzufriedenheit besser zu erfassen. Erste Ansätze verfolgen wir zwar schon, dennoch muss ehrlicherweise gesagt werden, dass die Projekte noch in den Kinderschuhen stecken.
Data Science Blog: Welche Rolle spielt Data Science in der Versicherungsbranche?
Schattner: Data Science spielt eine große Rolle, auch wenn wir in unserer Versicherung das Wort Data Science nicht aktiv verwenden, denn auch unsere Analysen von unstrukturierten Daten und mit statistischen Modellen laufen bei uns unter dem Begriff Business Intelligence.
Daten sind der einzige „Rohstoff“, den Versicherungen haben und da wir uns mit den Themen Gesundheit und Unfällen beschäftigen, spielen wir auch für die Forschung eine wichtige Rolle. Einige Kennzahlen sind teilweise von öffentlichem Interesse, wie etwa der Krankenstand, und bei der Ermittlung gibt es aus Sicht der Datenerhebung und statistischen Auswertung sehr viele Aspekte zu berücksichtigen.
Data Science Blog: Arbeiten Data Scientist eher in eigenen abgekapselten Abteilungen oder in der IT-Abteilung oder in den Fachbereichen?
Schattner: Wir haben keine zentrale Data Science Abteilung, sondern trennen zwei Bereiche:
Das Data Warehouse ist in der IT angesiedelt und hat die Aufgabe, alle erfassten und erfassbaren Daten zu sammeln und den Fachbereichen zur Verfügung zu stellen. In der Regel werden vom Data Warehouse strukturierte Daten bereit gestellt, vermehrt werden jedoch auch unstrukturierte Daten, beispielsweise aus eingescannten Dokumenten, von den Fachbereichen angefordert.
Die gezielten Analysen finden dann weitgehend unabhängig voneinander in den einzelnen Fachbereichen statt, wobei einige Fachbereiche natürlich eigene Analyse-Teams aufgebaut haben.
Data Science Blog: Welche Tools werden für die Datenauswertung bei der Helsana überwiegend eingesetzt?
Schattner: Wir arbeiten überwiegend mit den Business Intelligence Lösungen IBM Cognos Suite, QilikTech QlikView und für statistische Analysen setzen wir vor allem auf SAS Analytics und zunehmend auch auf die Open Source Statistiksprache R ein.
Data Science Blog: Welche technischen Herausforderungen haben Sie ganz besonders im Blick in Sachen Big Data Analytics? Und auf welche Strategien zur Bewältigung setzen Sie?
Schattner: Es gibt nicht einige wenige besonders große Herausforderungen, sondern sehr viele kleinere über den gesamten Workflow hinweg. Big Data Analytics beginnt mit der Datenerhebung und ETL-Prozessen, umfasst weiter die Datenaufbereitung, statistische und visuelle Analyse und geht noch weiter bis hin zum Reporting mit Handlungsempfehlungen.
Zurzeit arbeiten wir sehr daran, den Umfang an Datenbeständen zu erweitern, Daten zu konsolidieren und die Datenqualität zu verbessern, denn die besten Analyseverfahren nützen wenig, wenn die Datenquellen nicht gut sind. Basierend auf den Datenquellen entwickeln wir für uns wichtige Informationsprodukte, mit denen wir unsere Leistungs- und Servicequalität erhöhen können, daher lohnt sich jede Investition in das Data Warehouse.
Wir verfolgen derzeit zwei Strategien parallel:
Auf dem Fast-Track stellen wir unternehmenskritische und für die dringende Einführung wichtige Informationen schnell zur Verfügung stellen. Dies läuft über einen agilen Ansatz, so dass wir hier schnell reagieren können und flexibel bleiben.
Dann verfolgen wir parallel dazu einen langfristigen Weg, gesicherte Datenflüsse nachhaltig aufzubauen, die viel besser administrierbar und erweiterbar sind.
Data Science Blog: Gerade in der Versicherungsbranche ist sicherlich der Datenschutz ein besonders wichtiges Thema, was können Sie dazu sagen?
Schattner: Die Informationen aus dem Data Warehouse unterliegen vielen Schutzauflagen, da unser Geschäft reich an Personen- und Diagnosedaten ist. Datenschutz und auch Datensicherheit haben höchste Priorität. Wir haben dabei auch Schutzmaßnahmen eingeführt, dass sich Mitarbeiter aus den Systemen heraus nicht über Diagnosen anderer Mitarbeiter informieren können.
Data Science Blog: Was für Analysen betreiben die Fachbereiche beispielsweise? Werden auch bereits unstrukturierte Daten systematisch analysiert?
Schattner: Wir unterstützen mit unseren statistischen Analysen die Forschung. Ein Beispiel aus der Gesundheitsökonomie ist die Ritalin-Forschung. Ritalin ist ein Medikament, das gegen die Aufmerksamkeitsstörung ADHS eingesetzt wird und die Konzentration betroffener Patienten steigert. Wir können basierend auf unseren Daten streng anonymisierte Analysen betreiben, ob in bestimmten Regionen mit ansonsten vergleichbaren Gesundheitsstrukturen unterschiedliche Häufigkeiten und Dosen auftreten. Finden wir sogenannte Hotspots, können kausale Zusammenhänge gesucht werden. Ursachen könnten beispielsweise Hypes unter lokalen Ärztegruppen sein oder schwierige soziale Verhältnisse unter Familienverbänden.
Ferner vergleichen wir Leistungserbringer und analysieren unterschiedliche Kostenverhältnisse unter Ärztestrukturen und Krankenhäusern.
Auch unstrukturierte Daten fließen in Form von Texten in manche unserer Analysen ein. Alle Dokumente zu Schadensfällen werden von unserer hausinternen Post eingescannt. Die Textinformationen aus den Schadensmeldungen speist unser Data Warehouse in BLOBs relationaler Datenbanken, auf die dann wieder der Fachbereich parsend zugreift.
Darüber hinaus stehen für uns Daten über unsere Leistungen und die Kundenzufriedenheit im Vordergrund, denn dadurch können wir uns als Unternehmen kontinuierlich verbessern.
Data Science Blog: Data Scientist gilt als Sexiest Job of the 21st Century. Welchen Rat würden Sie jungen Leuten geben, die Data Scientist bzw. Business Analyst werden möchten? Welche Kenntnisse setzen Sie voraus?
Schattner: Stellen wir uns einen Schieberegler vor, den wir nur in die eine oder andere verschieben könnten, sich dabei ganz links das Wissen über das Business stehen würde und ganz rechts sich das IT-Wissen befindet. Ich würde den Regler auf 80% auf die Business-Seite schieben. Es sollte natürlich auch Wissen über SQL, ETL und Programmierung vorhanden sein, aber alleinige IT- bzw. Tool-Experten helfen uns leider wenig. In der Versicherungsbranche ist vor allem ein Wissen über das Geschäft von Bedeutung. Heutzutage ermöglichen interaktive Tools recht einfach die Erstellung von Datenbankabfragen sowie eine multidimensionale und visuelle Datenanalyse.
Das verdeutlichen auch die zwei Architekturen: Zum einen haben wir die Datenarchitektur, die die Datenflüsse von den Datenquellen ausgehend beschreibt, und zum anderen haben wir eine Informationsarchitektur, die die Daten über Geschäftslogiken in Business Objects fasst, so werden aus Daten Informationen.
Folgende Metapher verwende ich hierzu auch gerne in meinen Vorträgen: Ein Tischler beherrscht sein Handwerk Möbel zu bauen, ein CNC-Fräser fertigt Maschinenwerkzeug.
Der Tischler merkt schnell, dass er mit einer elektrischen Säge schneller und genauer vorankommt, als mit einer Handsäge. Der Drehmaschinenarbeiter verfügt zwar über perfekt arbeitende und computergesteuerte Gerätschaften, ist jedoch nicht in der Lage, gute Holzmöbel zu bauen, weil er es niemals gelernt hat.
Genauso muss der Business Experte zwar erstmal lernen, bestimmte Tools zu bedienen, aber dafür hat er stets ein genaues Ziel im Kopf, was er damit erreichen will. Die Bedienbarkeit der Tools am Markt lässt sich heute leichter erlernen als früher.
Gute Data Scientists schauen, welche Nutzen aus Daten erzeugt werden könnten und welche Daten zur Verfügung stehen oder erfasst werden können, um bestimmte Resultate erzielen zu können.
Branchenwissen allein reicht jedoch auch nicht unbedingt aus, beispielsweise ist es beim Customer Analytics wichtig, branchenspezifische Vertriebsstrategien im Kopf zu haben und auch aus der Praxis zu kennen, denn nur so lassen sich die Informationen in praxisnahe Strategien umwandeln.
Data Science Blog: Wird die Nachfrage nach Data Science weiter steigen oder ist der Trend bald vorbei?
Schattner: Ich denke, dass dieser Hype noch nicht ganz erreicht ist. Irgendwann wird er aber erreicht sein und dann schlägt die Realität zu. Beispielsweise wird gerade viel über Predictive Analytics gesprochen, dabei betreiben einige Fachbereiche bereits seit mindestens einem Jahrhundert Vorhersagen. Im Controlling, aus dem ich komme, waren bereits recht komplexe Prognosen in Excel üblich, nur hätten wir das nicht Predictive Analytics oder Data Science genannt. Natürlich werden die Prognosen nun dank leistungsfähigerer Technologien immer besser und genauer, nur ist es nichts substanziell Neues. Der Trend verstärkt aber die Bemühungen im Bereich Business Intelligence und lockert auch Budgets für neue Analyseverfahren.
Die Redaktion sucht Interview-Partner aus Wirtschaft und Wissenschaft!
Sie sind Professor einer Hochschule, CEO, CIO oder Chief Data Scientist? Dann laden wir Sie herzlichst dazu ein, mit uns in Kontakt zu treten. Als erster deutscher Data Science Blog möchten wir die Bedeutung von Big Data und Data Science für die mitteleuropäische Wirtschaft an die Gesellschaft herantragen. Wenn Sie etwas zum Thema zu sagen haben, dann schreiben Sie uns eine Mail an redaktion@data-science-blog.com.


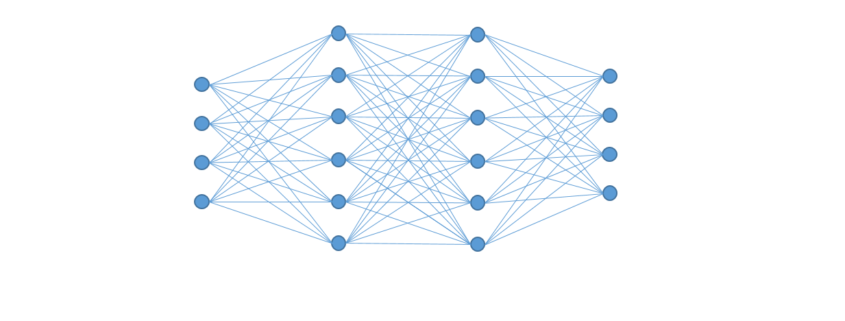


 (Theta) multipliziert und die Ergebnisse aufsummiert. Das Zwischenergebnis ist die Aktivierungsstärke z:
(Theta) multipliziert und die Ergebnisse aufsummiert. Das Zwischenergebnis ist die Aktivierungsstärke z:![\[ z = X_0 \cdot \theta_0 + X_1 \cdot \theta_1 + X_2 \cdot \theta_2 \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-49288c71db69e864888f642613627b1b_l3.svg "Rendered by QuickLaTeX.com")

![\[ sigmoid(z) = \frac{1}{1+e^{-z}} \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-d02636a1d3140b9e8e9dc48a1c5c395a_l3.svg "Rendered by QuickLaTeX.com")
![\[ Y = sigmoid(X\theta) \]](http://datasciencehack.com/wp-content/ql-cache/quicklatex.com-924f70586a4f97cd4aa0dceea3f2b047_l3.svg "Rendered by QuickLaTeX.com")