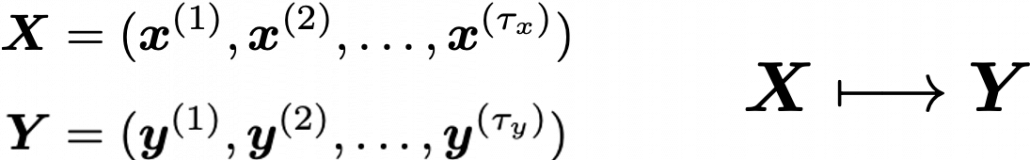
Understanding LSTM forward propagation in two ways
*This article is only for the sake of understanding the equations in the second page of the paper named “LSTM: A Search Space Odyssey”. If you have no trouble understanding the equations of LSTM forward propagation, I recommend you to skip this article and go the the next article.
1. Preface
I heard that in Western culture, smart people write textbooks so that other normal people can understand difficult stuff, and that is why textbooks in Western countries tend to be bulky, but also they are not so difficult as they look. On the other hand in Asian culture, smart people write puzzling texts on esoteric topics, and normal people have to struggle to understand what noble people wanted to say. Publishers also require the authors to keep the texts as short as possible, so even though the textbooks are thin, usually students have to repeat reading the textbooks several times because usually they are too abstract.
Both styles have cons and pros, and usually I prefer Japanese textbooks because they are concise, and sometimes it is annoying to read Western style long texts with concrete straightforward examples to reach one conclusion. But a problem is that when it comes to explaining LSTM, almost all the text books are like Asian style ones. Every study material seems to skip the proper steps necessary for “normal people” to understand its algorithms. But after actually making concrete slides on mathematics on LSTM, I understood why: if you write down all the equations on LSTM forward/back propagation, that is going to be massive, and actually I had to make 100-page PowerPoint animated slides to make it understandable to people like me.
I already had a feeling that “Does it help to understand only LSTM with this precision? I should do more practical codings.” For example François Chollet, the developer of Keras, in his book, said as below.
For me that sounds like “We have already implemented RNNs for you, so just shut up and use Tensorflow/Keras.” Indeed, I have never cared about the architecture of my Mac Book Air, but I just use it every day, so I think he is to the point. To make matters worse, for me, a promising algorithm called Transformer seems to be replacing the position of LSTM in natural language processing. But in this article series and in my PowerPoint slides, I tried to explain as much as possible, contrary to his advice.
But I think, or rather hope, it is still meaningful to understand this 23-year-old algorithm, which is as old as me. I think LSTM did build a generation of algorithms for sequence data, and actually Sepp Hochreiter, the inventor of LSTM, has received Neural Network Pioneer Award 2021 for his work.
I hope those who study sequence data processing in the future would come to this article series, and study basics of RNN just as I also study classical machine learning algorithms.
*In this article “Densely Connected Layers” is written as “DCL,” and “Convolutional Neural Network” as “CNN.”
2. Why LSTM?
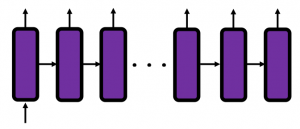
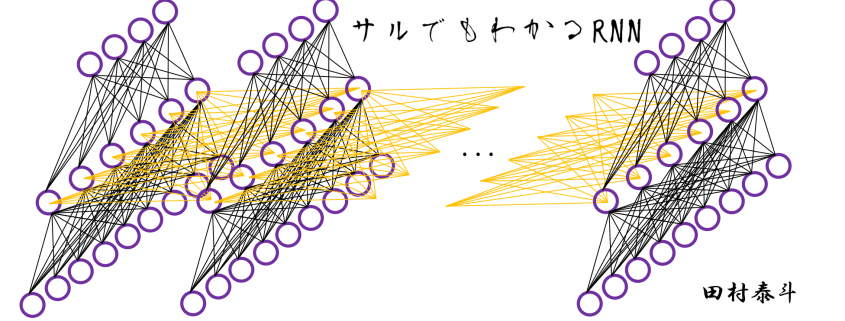
First of all, let’s take a brief look at what I said about the structures of RNNs, in the first and the second article. A simple RNN is basically densely connected network with a few layers. But the RNN gets an input every time step, and it gives out an output at the time step. Part of information in the middle layer are succeeded to the next time step, and in the next time step, the RNN also gets an input and gives out an output. Therefore, virtually a simple RNN behaves almost the same way as densely connected layers with many layers during forward/back propagation if you focus on its recurrent connections.
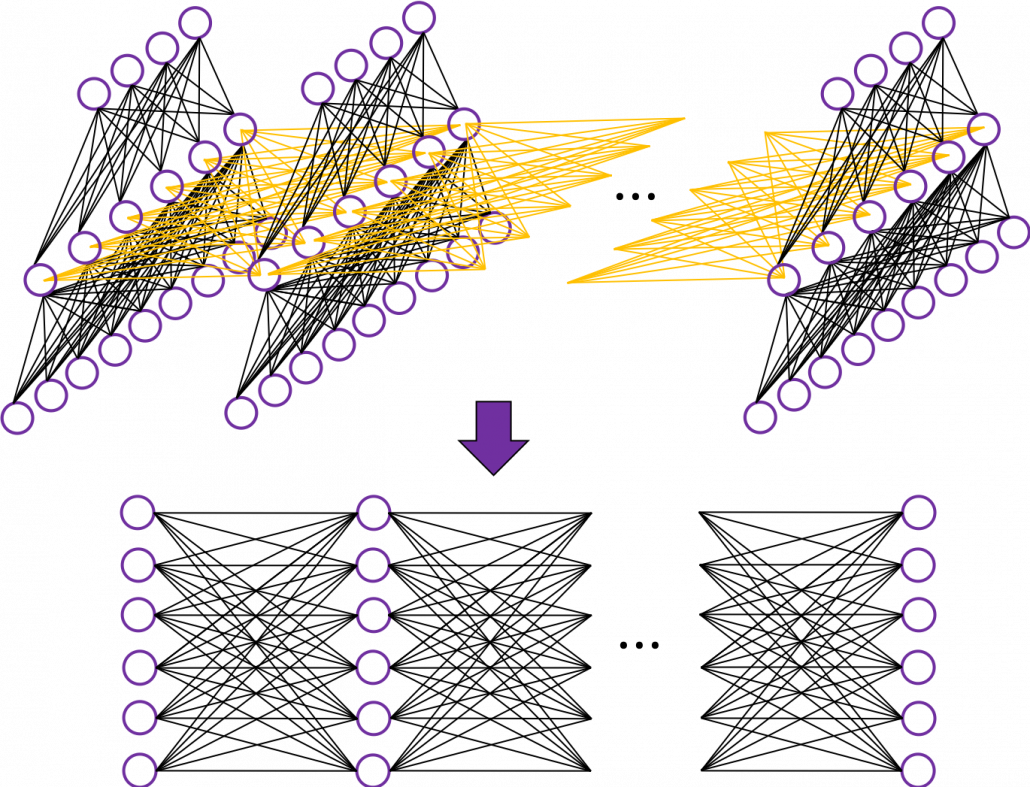
That is why simple RNNs suffer from vanishing/exploding gradient problems, where the information exponentially vanishes or explodes when its gradients are multiplied many times through many layers during back propagation. To be exact, I think you need to consider this problem precisely like you can see in this paper. But for now, please at least keep it in mind that when you calculate a gradient of an error function with respect to parameters of simple neural networks, you have to multiply parameters many times like below, and this type of calculation usually leads to vanishing/exploding gradient problem. 
LSTM was invented as a way to tackle such problems as I mentioned in the last article.
3. How to display LSTM
I would like you to just go to image search on Google, Bing, or Yahoo!, and type in “LSTM.” I think you will find many figures, but basically LSTM charts are roughly classified into two types: in this article I call them “Space Odyssey type” and “electronic circuit type”, and in conclusion, I highly recommend you to understand LSTM as the “electronic circuit type.”
*I just randomly came up with the terms “Space Odyssey type” and “electronic circuit type” because the former one is used in the paper I mentioned, and the latter one looks like an electronic circuit to me. You do not have to take how I call them seriously.
However, not that all the well-made explanations on LSTM use the “electronic circuit type,” and I am sure you sometimes have to understand LSTM as the “space odyssey type.” And the paper “LSTM: A Search Space Odyssey,” which I learned a lot about LSTM from, also adopts the “Space Odyssey type.”
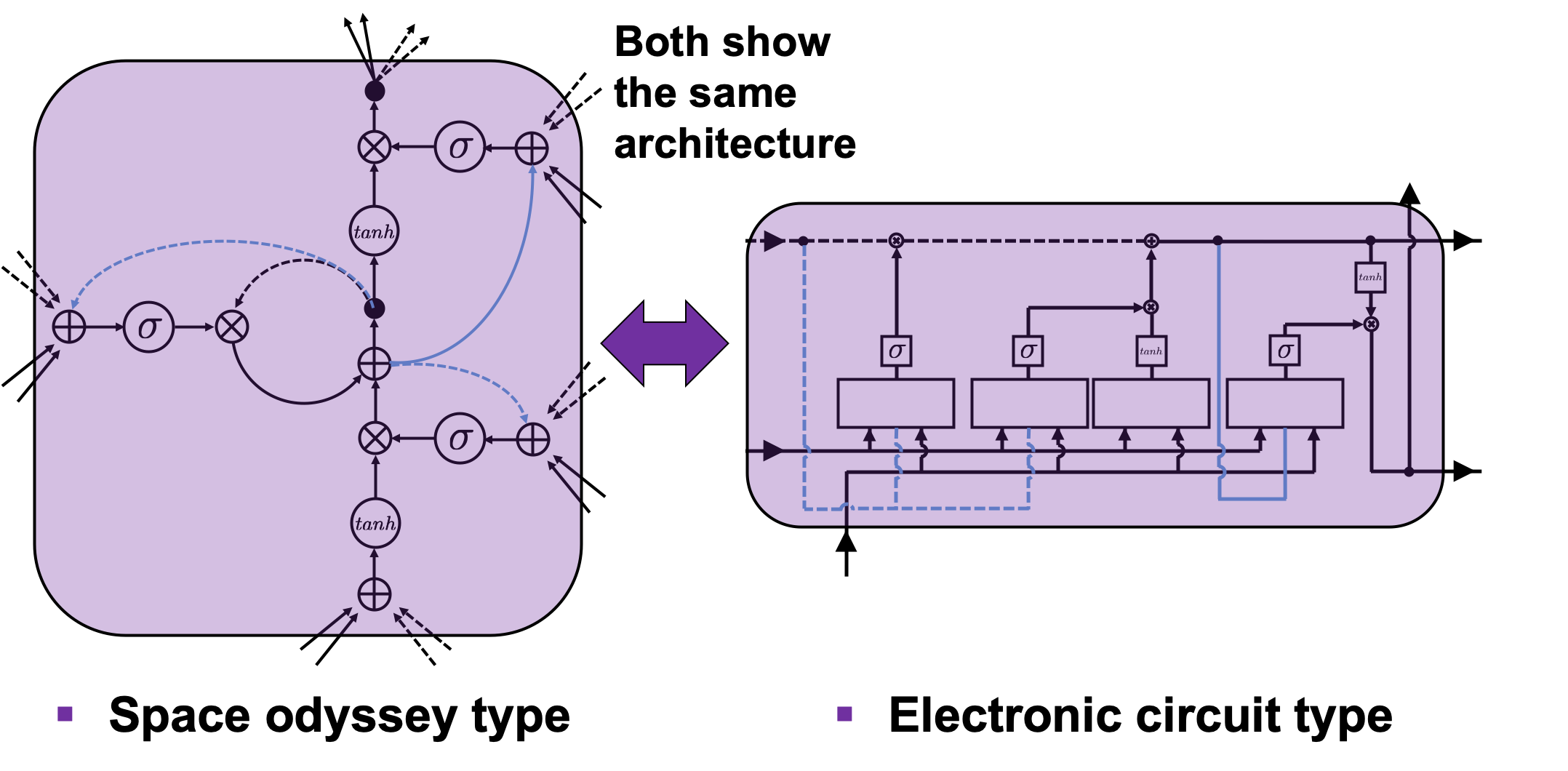
The main reason why I recommend the “electronic circuit type” is that its behaviors look closer to that of simple RNNs, which you would have seen if you read my former articles.
*Behaviors of both of them look different, but of course they are doing the same things.
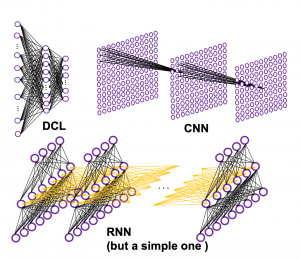
If you have some understanding on DCL, I think it was not so hard to understand how simple RNNs work because simple RNNs are mainly composed of linear connections of neurons and weights, whose structures are the same almost everywhere. And basically they had only straightforward linear connections as you can see below.

But from now on, I would like you to give up the ideas that LSTM is composed of connections of neurons like the head image of this article series. If you do that, I think that would be chaotic and I do not want to make a figure of it on Power Point. In short, sooner or later you have to understand equations of LSTM.
4. Forward propagation of LSTM in “electronic circuit type”
*For further understanding of mathematics of LSTM forward/back propagation, I recommend you to download my slides.
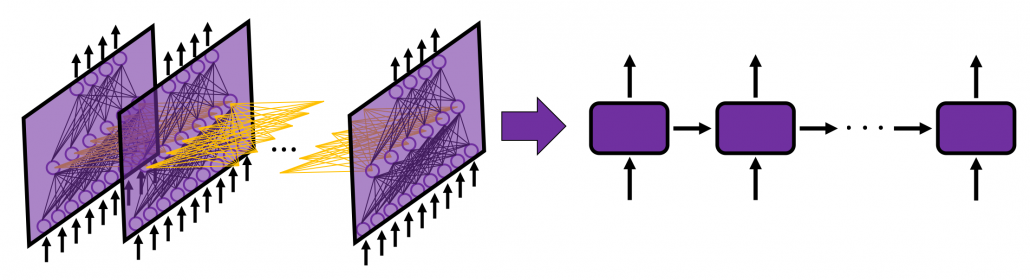
The behaviors of an LSTM block is quite similar to that of a simple RNN block: an RNN block gets an input every time step and gets information from the RNN block of the last time step, via recurrent connections. And the block succeeds information to the next block.
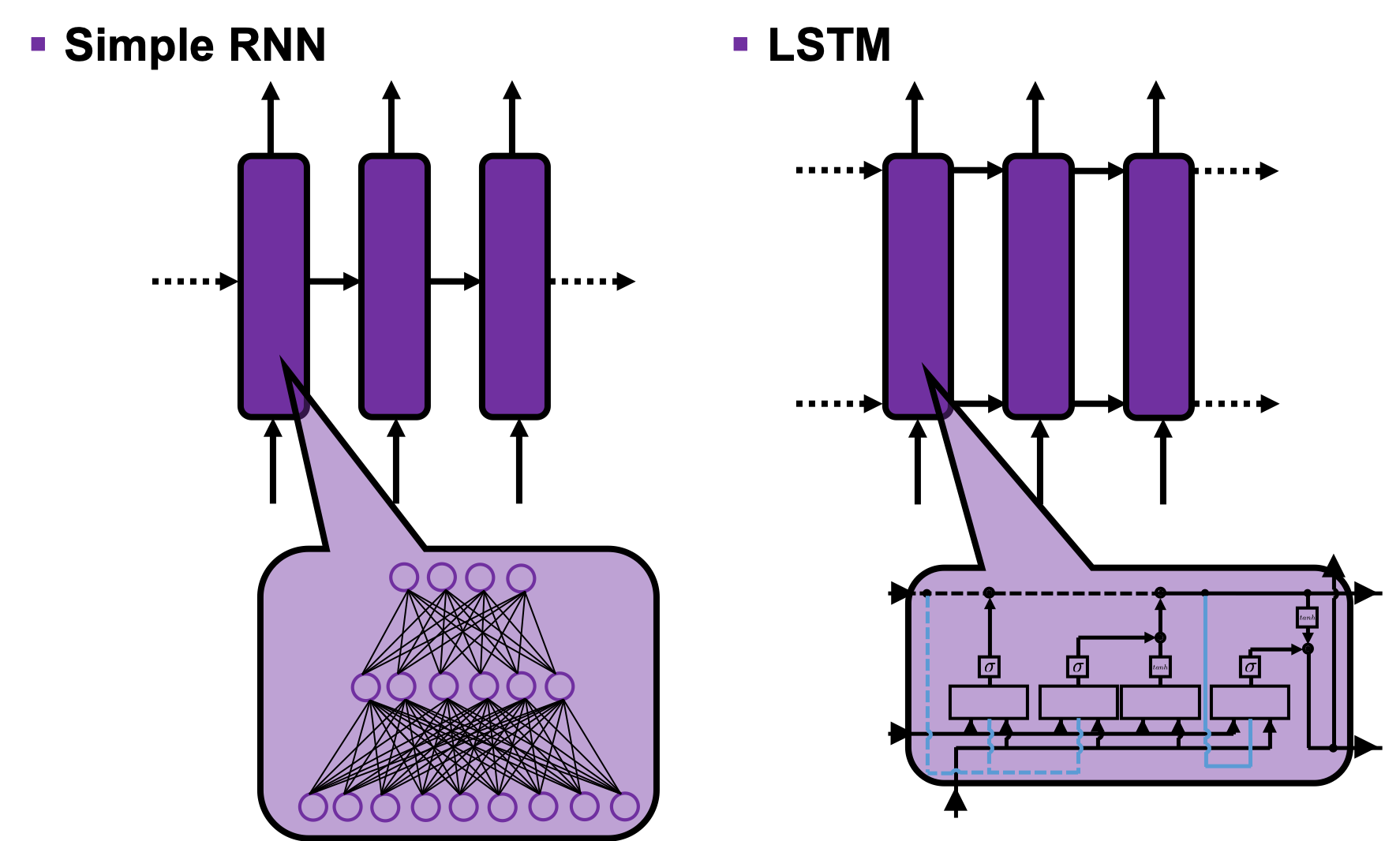
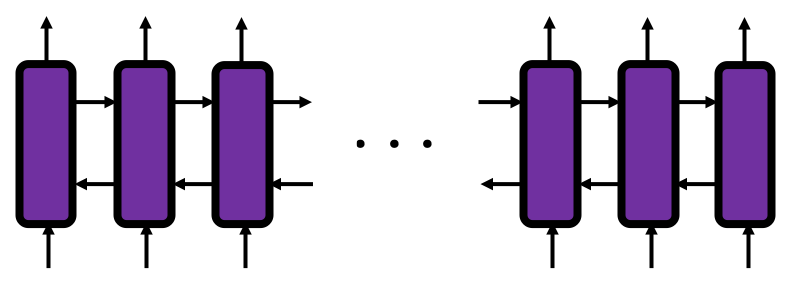
Let’s look at the simplified architecture of an LSTM block. First of all, you should keep it in mind that LSTM have two streams of information: the one going through all the gates, and the one going through cell connections, the “highway” of LSTM block. For simplicity, we will see the architecture of an LSTM block without peephole connections, the lines in blue. The flow of information through cell connections is relatively uninterrupted. This helps LSTMs to retain information for a long time.

In a LSTM block, the input and the output of the former time step separately go through sections named “gates”: input gate, forget gate, output gate, and block input. The outputs of the forget gate, the input gate, and the block input join the highway of cell connections to renew the value of the cell.
*The small two dots on the cell connections are the “on-ramp” of cell conection highway.
*You would see the terms “input gate,” “forget gate,” “output gate” almost everywhere, but how to call the “block gate” depends on textbooks.
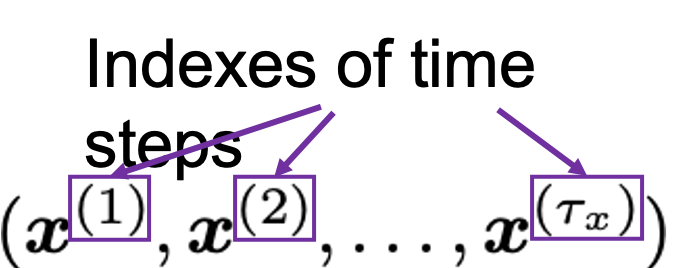
Let’s look at the structure of an LSTM block a bit more concretely. An LSTM block at the time step  gets
gets  , the output at the last time step, and
, the output at the last time step, and  , the information of the cell at the time step
, the information of the cell at the time step  , via recurrent connections. The block at time step gets the input
, via recurrent connections. The block at time step gets the input  , and it separately goes through each gate, together with . After some calculations and activation, each gate gives out an output. The outputs of the forget gate, the input gate, the block input, and the output gate are respectively
, and it separately goes through each gate, together with . After some calculations and activation, each gate gives out an output. The outputs of the forget gate, the input gate, the block input, and the output gate are respectively  . The outputs of the gates are mixed with and the LSTM block gives out an output
. The outputs of the gates are mixed with and the LSTM block gives out an output  , and gives and
, and gives and  to the next LSTM block via recurrent connections.
to the next LSTM block via recurrent connections.
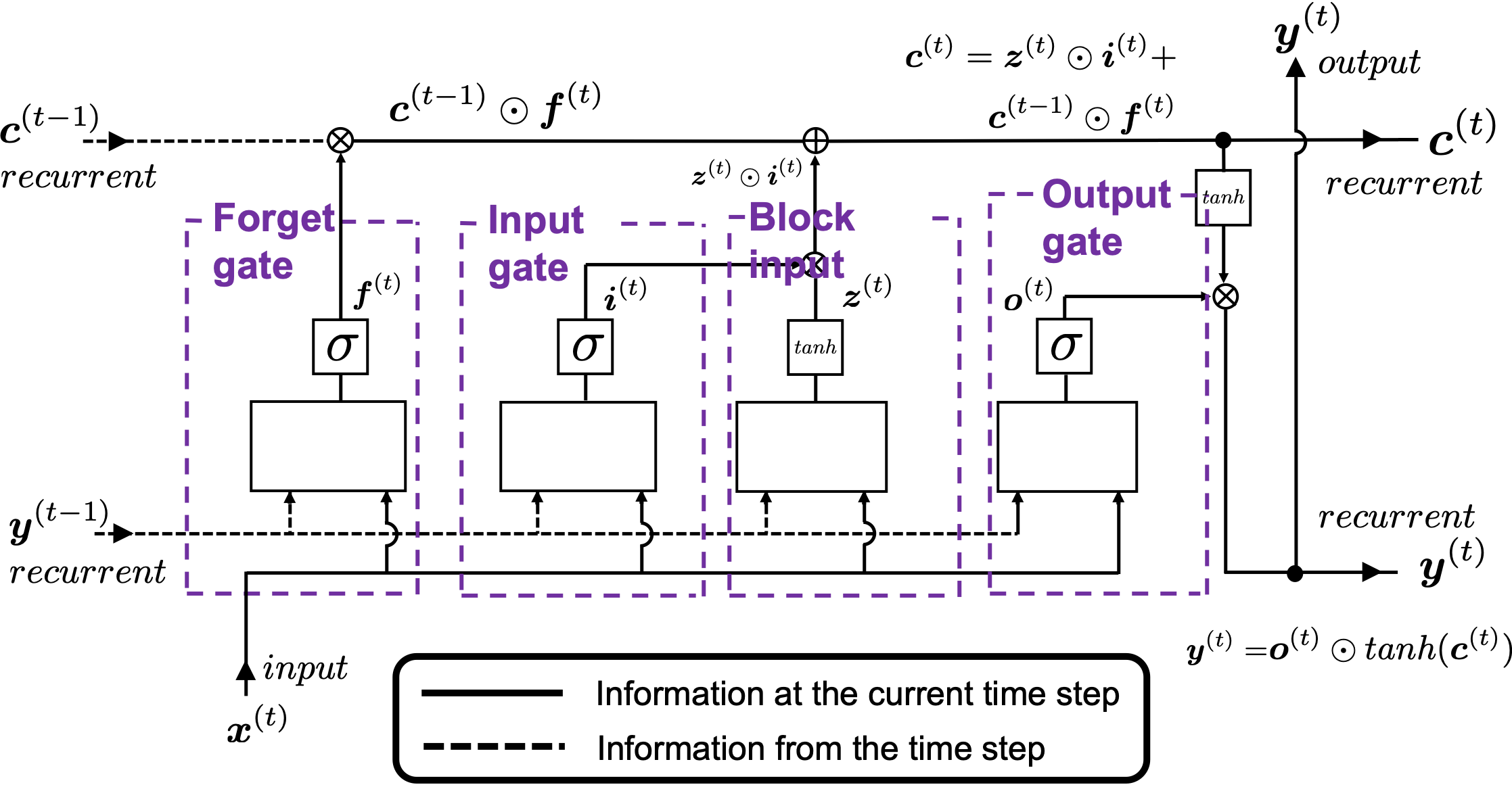
You calculate as below.




*You have to keep it in mind that the equations above do not include peephole connections, which I am going to show with blue lines in the end.
The equations above are quite straightforward if you understand forward propagation of simple neural networks. You add linear products of and with different weights in each gate. What makes LSTMs different from simple RNNs is how to mix the outputs of the gates with the cell connections. In order to explain that, I need to introduce a mathematical operator called Hadamard product, which you denote as  . This is a very simple operator. This operator produces an elementwise product of two vectors or matrices with identical shape.
. This is a very simple operator. This operator produces an elementwise product of two vectors or matrices with identical shape.
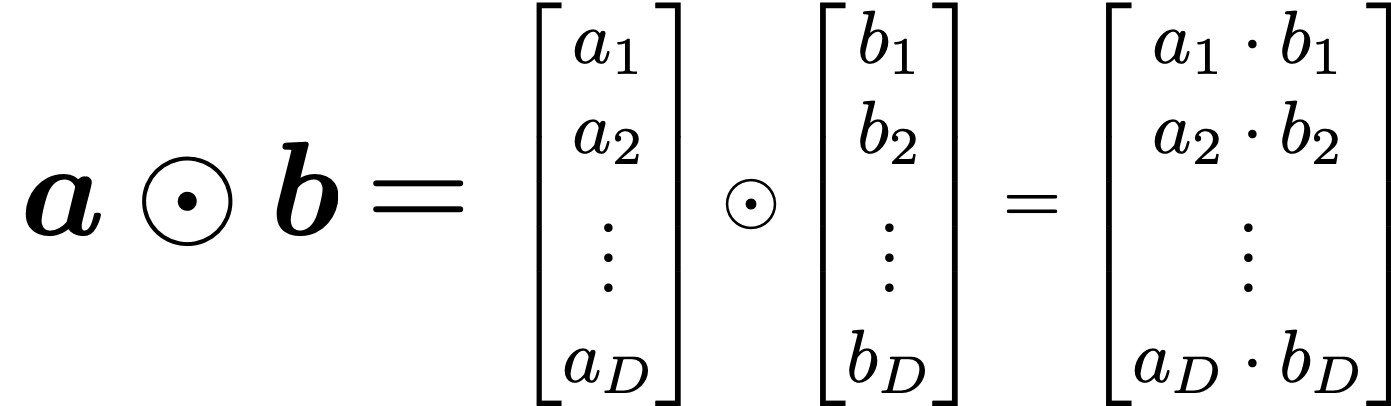
With this Hadamar product operator, the renewed cell and the output are calculated as below.


The values of are compressed into the range of ![[0, 1]](http://datasciencehack.com/en/wp-content/ql-cache/quicklatex.com-caffaae885a1287e3dfc31bfb1cd0694_l3.svg "Rendered by QuickLaTeX.com") or
or ![[-1, 1]](http://datasciencehack.com/en/wp-content/ql-cache/quicklatex.com-96395345c57f8928c42918c656dd1364_l3.svg "Rendered by QuickLaTeX.com") with activation functions. You can see that the input gate and the block input give new information to the cell. The part
with activation functions. You can see that the input gate and the block input give new information to the cell. The part  means that the output of the forget gate “forgets” the cell of the last time step by multiplying the values from 0 to 1 elementwise. And the cell is activated with
means that the output of the forget gate “forgets” the cell of the last time step by multiplying the values from 0 to 1 elementwise. And the cell is activated with  and the output of the output gate “suppress” the activated value of . In other words, the output gatedecides how much information to give out as an output of the LSTM block. The output of every gate depends on the input , and the recurrent connection . That means an LSTM block learns to forget the cell of the last time step, to renew the cell, and to suppress the output. To describe in an extreme manner, if all the outputs of every gate are always
and the output of the output gate “suppress” the activated value of . In other words, the output gatedecides how much information to give out as an output of the LSTM block. The output of every gate depends on the input , and the recurrent connection . That means an LSTM block learns to forget the cell of the last time step, to renew the cell, and to suppress the output. To describe in an extreme manner, if all the outputs of every gate are always  , LSTMs forget nothing, retain information of inputs at every time step, and gives out everything. And if all the outputs of every gate are always
, LSTMs forget nothing, retain information of inputs at every time step, and gives out everything. And if all the outputs of every gate are always  , LSTMs forget everything, receive no inputs, and give out nothing.
, LSTMs forget everything, receive no inputs, and give out nothing.
This model has one problem: the outputs of each gate do not directly depend on the information in the cell. To solve this problem, some LSTM models introduce some flows of information from the cell to each gate, which are shown as lines in blue in the figure below.
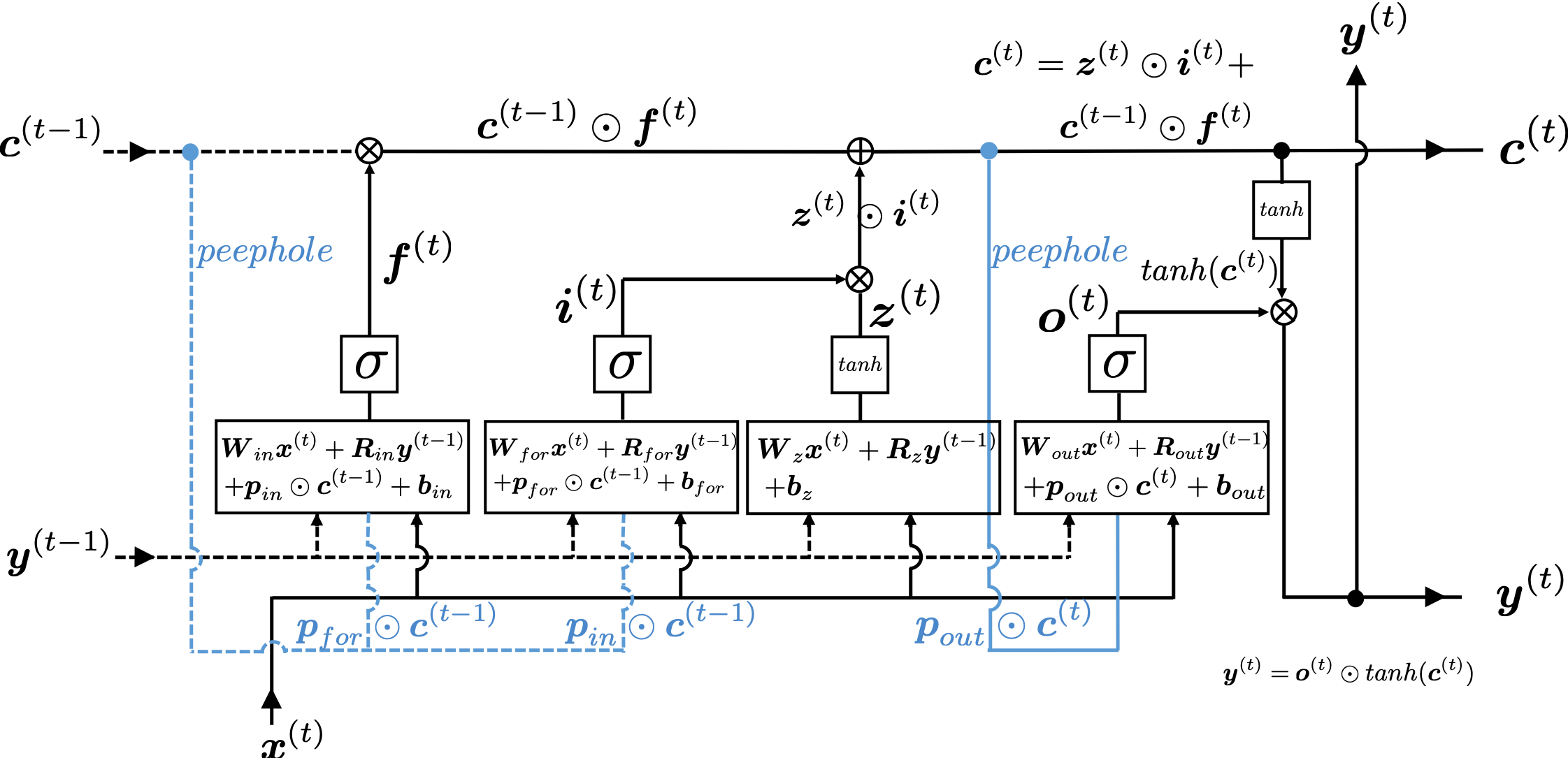
LSTM models, for example the one with or without peephole connection, depend on the library you use, and the model I have showed is one of standard LSTM structure. However no matter how complicated structure of an LSTM block looks, you usually cover it with a black box as below and show its behavior in a very simplified way.

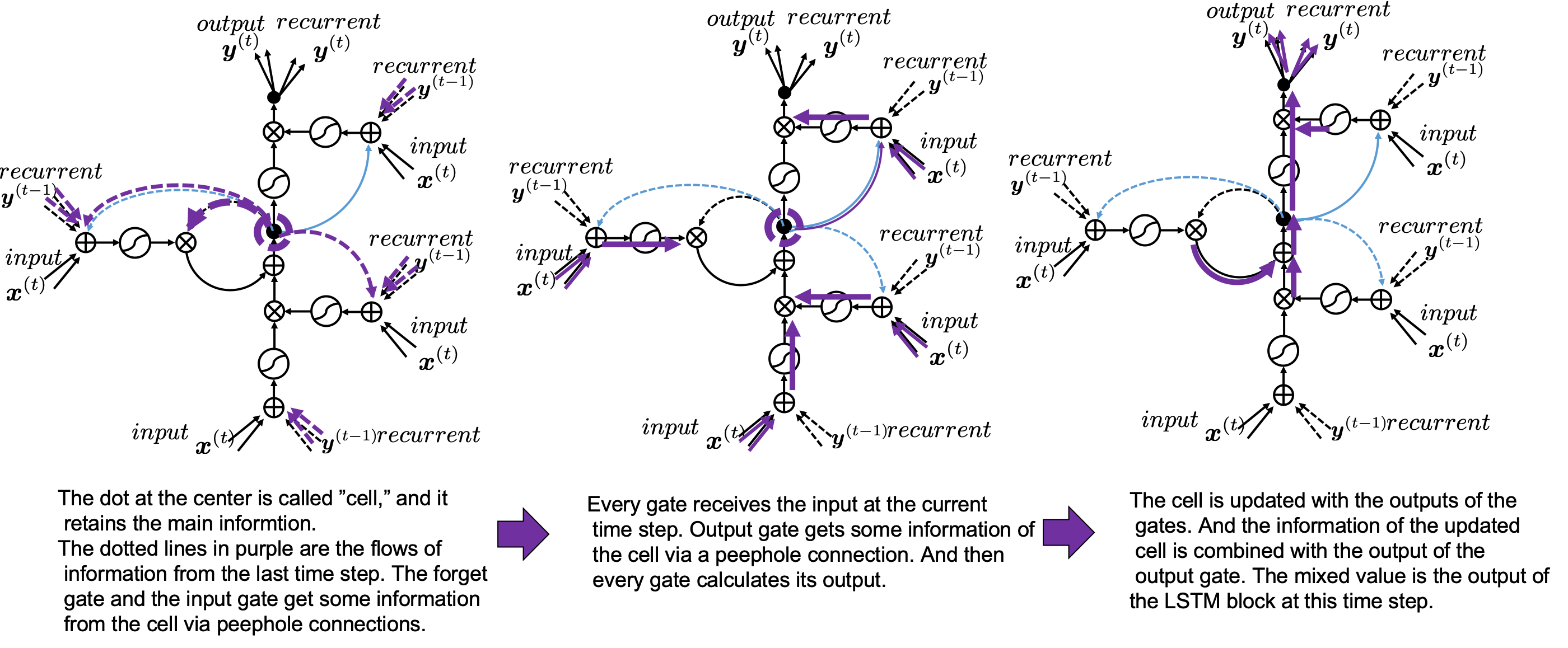
5. Space Odyssey type
I personally think there is no advantages of understanding how LSTMs work with this Space Odyssey type chart, but in several cases you would have to use this type of chart. So I will briefly explain how to look at that type of chart, based on understandings of LSTMs you have gained through this article.
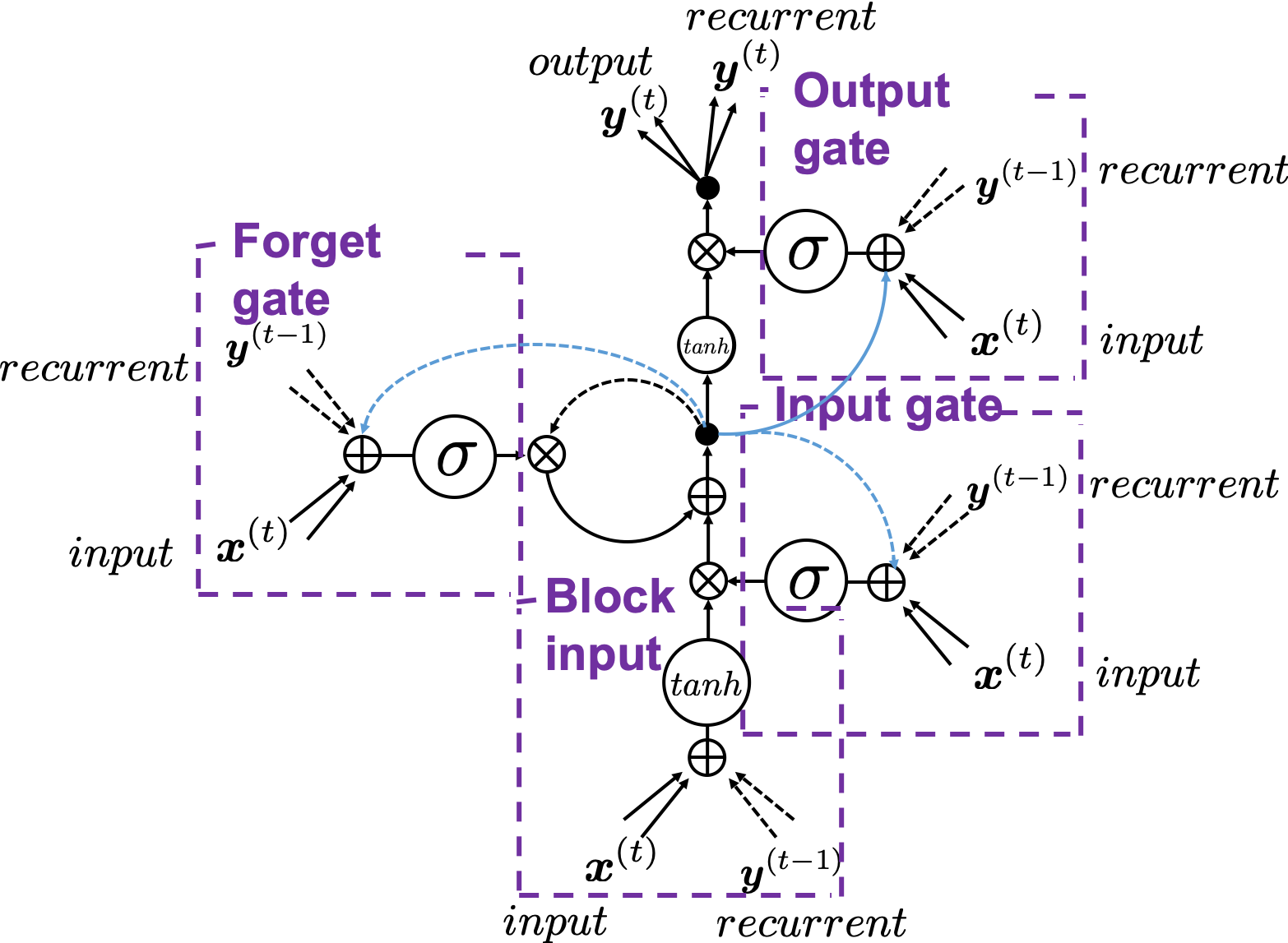
In Space Odyssey type of LSTM chart, at the center is a cell. Electronic circuit type of chart, which shows the flow of information of the cell as an uninterrupted “highway” in an LSTM block. On the other hand, in a Spacey Odyssey type of chart, the information of the cell rotate at the center. And each gate gets the information of the cell through peephole connections, , the input at the time step , sand , the output at the last time step , which came through recurrent connections. In Space Odyssey type of chart, you can more clearly see that the information of the cell go to each gate through the peephole connections in blue. Each gate calculates its output.
Just as the charts you have seen, the dotted line denote the information from the past. First, the information of the cell at the time step goes to the forget gate and get mixed with the output of the forget cell In this process the cell is partly “forgotten.” Next, the input gate and the block input are mixed to generate part of new value of the the cell at time step . And the partly “forgotten” goes back to the center of the block and it is mixed with the output of the input gate and the block input. That is how is renewed. And the value of new cell flow to the top of the chart, being mixed with the output of the output gate. Or you can also say the information of new cell is “suppressed” with the output gate.
I have finished the first four articles of this article series, and finally I am gong to write about back propagation of LSTM in the next article. I have to say what I have written so far is all for the next article, and my long long Power Point slides.
[References]
[1] Klaus Greff, Rupesh Kumar Srivastava, Jan Koutník, Bas R. Steunebrink, Jürgen Schmidhuber, “LSTM: A Search Space Odyssey,” (2017)
[2] Francois Chollet, Deep Learning with Python,(2018), Manning , pp. 202-204
[3] “Sepp Hochreiter receives IEEE CIS Neural Networks Pioneer Award 2021”, Institute of advanced research in artificial intelligence, (2020)
URL: https://www.iarai.ac.at/news/sepp-hochreiter-receives-ieee-cis-neural-networks-pioneer-award-2021/?fbclid=IwAR27cwT5MfCw4Tqzs3MX_W9eahYDcIFuoGymATDR1A-gbtVmDpb8ExfQ87A
[4] Oketani Takayuki, “Machine Learning Professional Series: Deep Learning,” (2015), pp. 120-125
岡谷貴之 著, 「機械学習プロフェッショナルシリーズ 深層学習」, (2015), pp. 120-125
[5] Harada Tatsuya, “Machine Learning Professional Series: Image Recognition,” (2017), pp. 252-257
原田達也 著, 「機械学習プロフェッショナルシリーズ 画像認識」, (2017), pp. 252-257
[6] “Understandable LSTM ~ With the Current Trends,” Qiita, (2015)
「わかるLSTM ~ 最近の動向と共に」, Qiita, (2015)
URL: https://qiita.com/t_Signull/items/21b82be280b46f467d1b

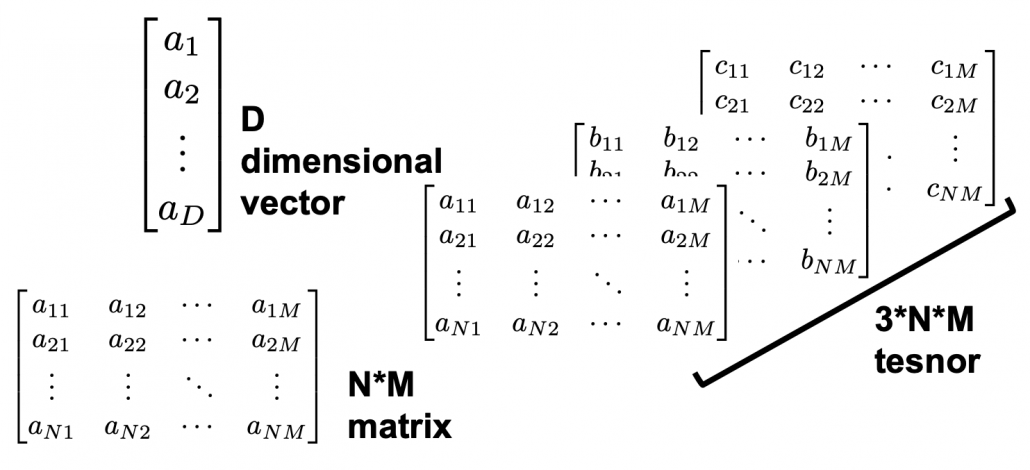
 , which most people would have seen in compulsory education, is a part of mapping. If you get a value x, you get a value y corresponding to the x.
, which most people would have seen in compulsory education, is a part of mapping. If you get a value x, you get a value y corresponding to the x. . If you have never studied linear algebra , imagine that a vector is a column of Excel data (only one column), a matrix is a sheet of Excel data (with some rows and columns), and a tensor is some sheets of Excel data (each sheet does not necessarily contain only one column.)
. If you have never studied linear algebra , imagine that a vector is a column of Excel data (only one column), a matrix is a sheet of Excel data (with some rows and columns), and a tensor is some sheets of Excel data (each sheet does not necessarily contain only one column.)