
Process Paradise by the Dashboard Light
The right questions drive business success. Questions like, “How can I make sure my product is the best of its kind?” “How can I get the edge over my competitors?” and “How can I keep growing my organization?” Modern businesses take their questions further, focusing on the details of how they actually function. At this level, the questions become, “How can I make my business as efficient as possible?” “How can I improve the way my company does business?” and even, “Why aren’t my company’s processes working as they should?”
Mit Dashboards zur Prozessoptimierung
To discover the answers to these questions (and many others!), more and more businesses are turning to process mining. Process mining helps organizations unlock hidden value by automatically collecting information on process models from across the different IT systems operating within a business. This allows for continuous monitoring of an organization’s end-to-end process landscape, meaning managers and staff gain specific operational insights into potential risks—as well as ongoing improvement opportunities.
However, process mining is not a silver bullet that turns data into insights at the push of a button. Process mining software is simply a tool that produces information, which then must be analyzed and acted upon by real people. For this to happen, the information produced must be available to decision-makers in an understandable format.
For most process mining tools, the emphasis remains on the sophistication of analysis capabilities, with the resulting data needing to be interpreted by a select group of experts or specialists within an organization. This necessarily creates a delay between the data being produced, the analysis completed, and actions taken in response.
Process mining software that supports a more collaborative approach by reducing the need for specific expertise can help bridge this gap. Only if hypotheses, analysis, and discoveries are shared, discussed, and agreed upon with a wide range of people can really meaningful insights be generated.
Of course, process mining software is currently capable of generating standardized reports and readouts, but in a business environment where the pace of change is constantly increasing, this may not be sufficient for very much longer. For truly effective process mining, the secret to success will be anticipating challenges and opportunities, then dealing with them as they arise in real time.
Dashboards of the future
To think about how process mining could improve, let’s consider an analog example. Technology evolves to make things easier—think of the difference between keeping track of expenditure using a written ledger vs. an electronic spreadsheet. Now imagine the spreadsheet could tell you exactly when you needed to read it, and where to start, as well as alerting you to errors and omissions before you were even aware you’d made them.
Advances in process mining make this sort of enhanced assistance possible for businesses seeking to improve the way they work. With the right process mining software, companies can build tailored operational cockpits that unite real-time operational data with process management. This allows for the usual continuous monitoring of individual processes and outcomes, but it also offers even clearer insights into an organization’s overall process health.
Combining process mining with an organization’s existing process models in the right way turns these models from static representations of the way a particular process operates, into dynamic dashboards that inform, guide and warn managers and staff about problems in real time. And remember, dynamic doesn’t have to mean distracting—the right process mining software cuts into your processes to reveal an all-new analytical layer of process transparency, making things easier to understand, not harder.
As a result, business transformation initiatives and other improvement plans and can be adapted and restructured on the go, while decision-makers can create automated messages to immediately be advised of problems and guided to where the issues are occurring, allowing corrective action to be completed faster than ever. This rapid evaluation and response across any process inefficiencies will help organizations save time and money by improving wasted cycle times, locating bottlenecks, and uncovering non-compliance across their entire process landscape.
Dynamic dashboards with Signavio
To see for yourself how the most modern and advanced process mining software can help you reveal actionable insights into the way your business works, give Signavio Process Intelligence a try. With Signavio’s Live Insights, all your process information can be visualized in one place, represented through a traffic light system. Simply decide which processes and which activities within them you want to monitor or understand, place the indicators, choose the thresholds, and let Signavio Process Intelligence connect your process models to the data.
Banish multiple tabs and confusing layouts, amaze your colleagues and managers with fact-based insights to support your business transformation, and reduce the time it takes to deliver value from your process management initiatives. To find out more about Signavio Process Intelligence, or sign up for a free 30-day trial, visit www.signavio.com/try.
Process mining is a powerful analysis tool, giving you the visibility, quantifiable numbers, and information you need to improve your business processes. Would you like to read more? With this guide to managing successful process mining initiatives, you will learn that how to get started, how to get the right people on board, and the right project approach.


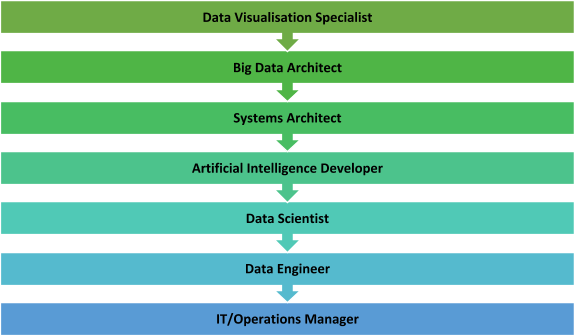
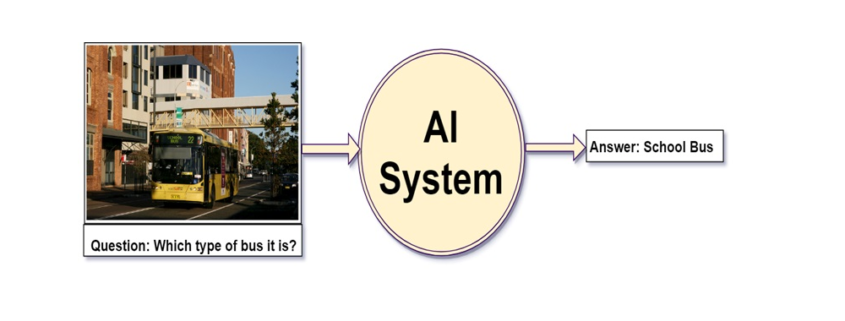


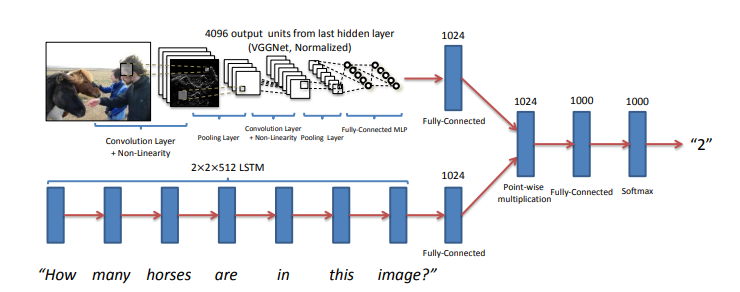
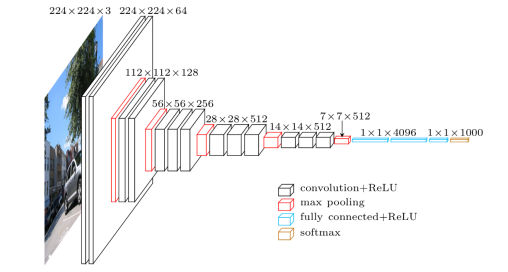






 David M. Raab is as a consultant specialized in marketing software and service vendor selection, marketing analytics and marketing technology assessment. Furthermore he is the founder of the Customer Data Platform Institute which is a vendor-neutral educational project to help marketers build a unified customer view that is available to all of their company systems.
David M. Raab is as a consultant specialized in marketing software and service vendor selection, marketing analytics and marketing technology assessment. Furthermore he is the founder of the Customer Data Platform Institute which is a vendor-neutral educational project to help marketers build a unified customer view that is available to all of their company systems.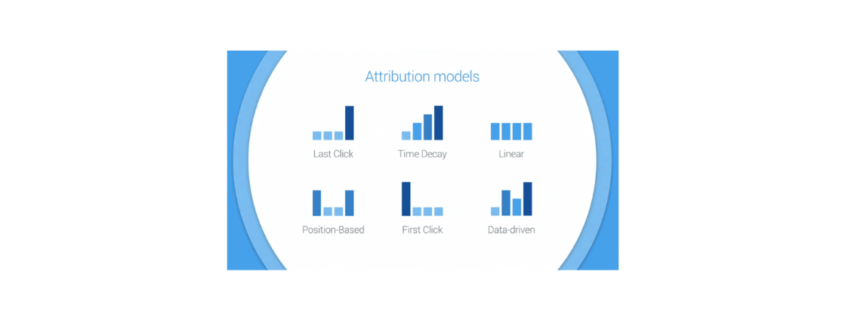
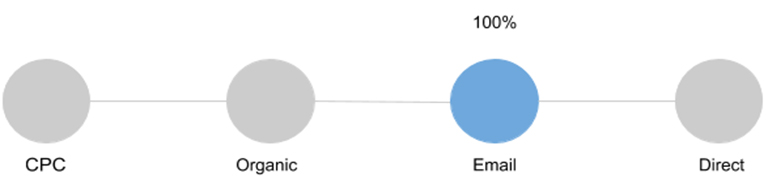
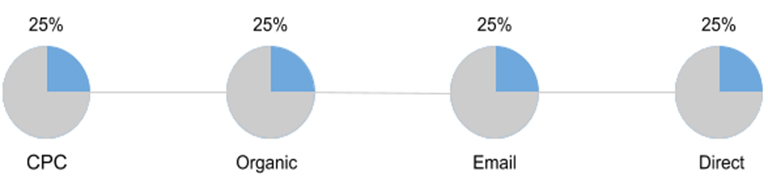
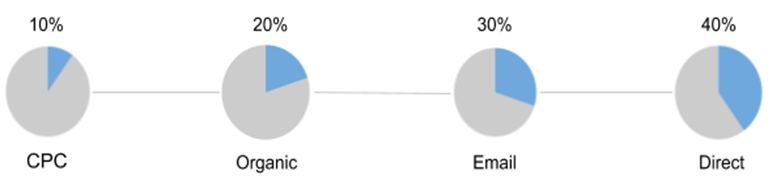
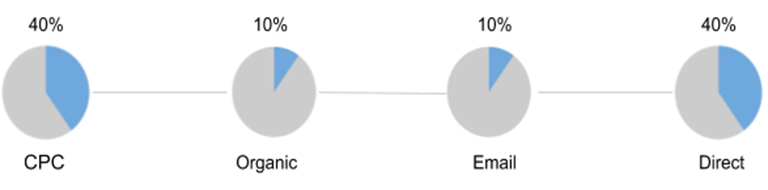
 gif
gif