Customer Journey Mapping: The data-driven approach to understanding your users
Businesses across the globe are on a mission to know their customers inside out – something commonly referred to as customer-centricity. It’s an attempt to better understand the needs and wants of customers in order to provide them with a better overall experience.
But while this sounds promising in theory, it’s much harder to achieve in practice. To really know your customer you must not only understand what they want, but you also need to hone in on how they want it, when they want it and how often as well.
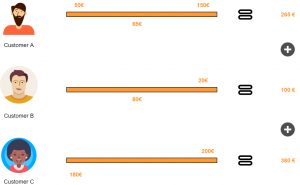
In essence, your business should use customer journey mapping. It allows you to visualise customer feelings and behaviours through the different stages of their journey – from the first interaction, right up until the point of purchase and beyond.
The Data-Driven Approach
To ensure your customer journey mapping is successful, you must conduct some extensive research on your customers. You can’t afford to make decisions based on feelings and emotions alone. There are two types of research that you should use for customer journey mapping – quantitative and qualitative research.
Quantitative data is best for analysing the behaviour of your customers as it identifies their habits over time. It’s also extremely useful for confirming any hypotheses you may have developed. That being so, relying solely upon quantitative data can present one major issue – it doesn’t provide you with the specific reason behind those behaviours.
That’s where qualitative data comes to the rescue. Through data collection methods like surveys, interviews and focus groups, you can figure out the reasoning behind some of your quantitative data trends. The obvious downside to qualitative data is its lack of evidence and its tendency to be subjective. Therefore, a combination of both quantitative and qualitative research is most effective.
Creating A Customer Persona
A customer persona is designed to help businesses understand the key traits of specific groups of people. For example, those defined by their age range or geographic location. A customer persona can help improve your customer journey map by providing more insight into the behavioural trends of your “ideal” customer.
The one downside to using customer personas is that they can be over-generalised at times. Just because a group of people shares a similar age, for example, it does not mean they all share the same beliefs and interests. Nevertheless, creating a customer persona is still beneficial to customer journey mapping – especially if used in combination with the correct customer journey analytics tools.
All Roads Lead To Customer-centricity
To achieve customer-centricity, businesses must consider using a data-driven approach to customer journey mapping. First, it requires that you achieve a balance between both quantitative and qualitative research. Quantitative research will provide you with definitive trends while qualitative data gives you the reasoning behind those trends.
To further increase the effectiveness of your customer journey map, consider creating customer personas. They will give you further insight into the behavioural trends within specific groups.
This article was written by TAP London. Experts in the Adobe Experience Cloud, TAP London help brands organise data to provide meaningful insight and memorable customer experiences. Find out more at wearetaplondon.com.