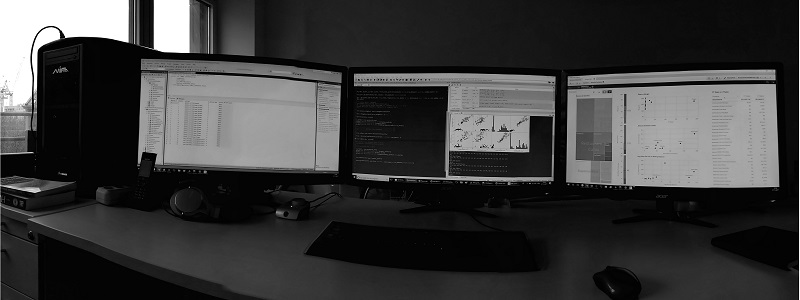
My Desk for Data Science
In my last post I anounced a blog parade about what a data scientist’s workplace might look like.
Here are some photos of my desk and my answers to the questions:
How many monitors do you use (or wish to have)?
I am mostly working at my desk in my office with a tower PC and three monitors.
I definitely need at least three monitors to work productively as a data scientist. Who does not know this: On the left monitor the data model is displayed, on the right monitor the data mapping and in the middle I do my work: programming the analysis scripts.
What hardware do you use? Apple? Dell? Lenovo? Others?
I am note an Apple guy. When I need to work mobile, I like to use ThinkPad notebooks. The ThinkPads are (in my experience) very robust and are therefore particularly good for mobile work. Besides, those notebooks look conservative and so I’m not sad if there comes a scratch on the notebook. However, I do not solve particularly challenging analysis tasks on a notebook, because I need my monitors for that.
Which OS do you use (or prefer)? MacOS, Linux, Windows? Virtual Machines?
As a data scientist, I have to be able to communicate well with my clients and they usually use Microsoft Windows as their operating system. I also use Windows as my main operating system. Of course, all our servers run on Linux Debian, but most of my tasks are done directly on Windows.
For some notebooks, I have set up a dual boot, because sometimes I need to start native Linux, for all other cases I work with virtual machines (Linux Ubuntu or Linux Mint).

What are your favorite databases, programming languages and tools?
I prefer the Microsoft SQL Server (T-SQL), C# and Python (pandas, numpy, scikit-learn). This is my world. But my customers are kings, therefore I am working with Postgre SQL, MongoDB, Neo4J, Tableau, Qlik Sense, Celonis and a lot more. I like to get used to new tools and technologies again and again. This is one of the benefits of being a data scientist.
Which data dou you analyze on your local hardware? Which in server clusters or clouds?
There have been few cases yet, where I analyzed really big data. In cases of analyzing big data we use horizontally scalable systems like Hadoop and Spark. But we also have customers analyzing middle-sized data (more than 10 TB but less than 100 TB) on one big server which is vertically scalable. Most of my customers just want to gather data to answer questions on not so big amounts of data. Everything less than 10TB we can do on a highend workstation.
If you use clouds, do you prefer Azure, AWS, Google oder others?
Microsoft Azure! I am used to tools provided by Microsoft and I think Azure is a well preconfigured cloud solution.
Where do you make your notes/memos/sketches. On paper or digital?
My calender is managed digital, because I just need to know everywhere what appointments I have. But my I prefer to wirte down my thoughts on paper and that´s why I have several paper-notebooks.

Now it is your turn: Join our Blog Parade!
So what does your workplace look like? Show your desk on your blog until 31/12/2017 and we will show a short introduction of your post here on the Data Science Blog!



