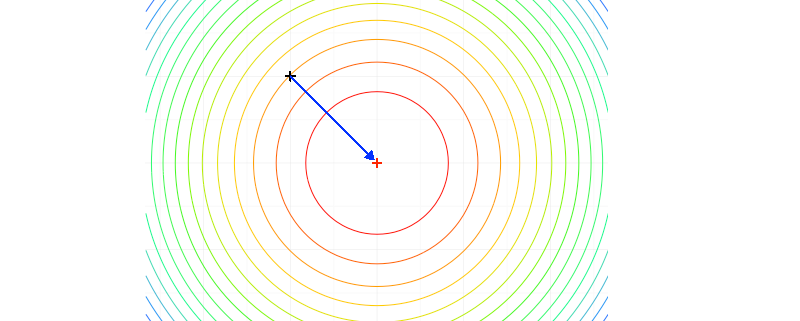
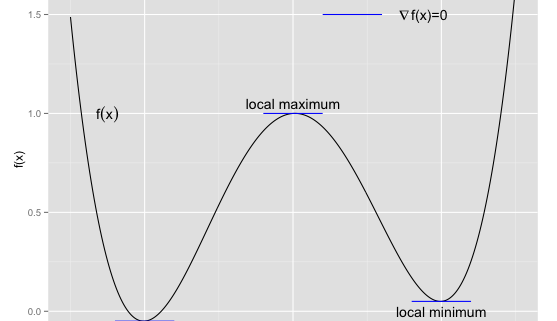
Machine Learning ist eines der am häufigsten verwendeten Buzzwords im Data-Science- und Big-Data-Bereich. Aber lernen Maschinen eigentlich und wenn ja, wie? In den meisten Fällen lautet die Antwort: Maschinen lernen nicht, sie optimieren. Fällt der Begriff Machine Learning oder Maschinelles Lernen, so denken viele sicherlich zuerst an bekannte “Lern”-Algorithmen wie Lineare Regression, Logistische Regression, Neuronale Netze oder Support Vector Machines. Die meisten dieser Algorithmen – wir beschränken uns hier vorerst auf den Bereich des Supervised Learning – sind aber nur Anwendungen einer anderen, grundlegenderen Theorie – der mathematischen Optimierung. Alle hier angesprochenen Algorithmen stellen dem Anwender eine bestimmte Ziel- oder Kostenfunktion zur Verfügung, aus der sich i.a. der Name der Methode ableitet und für die im Rahmen des Lernens ein Minimum oder Optimum gefunden werden soll. Ein großer Teil des Geheimnisses und die eigentliche Stärke der Machine-Learning-Algorithmen liegt nun darin, dass dieser Minimierungsprozess effizient durchgeführt werden kann. Wir wollen im Folgenden kurz erklären, wie dies in etwa funktioniert. In einem späteren Blogpost gehen wir dann genauer auf das Thema der Effizienz eingehen. Read more