Man redet gerne über Daten, genutzt werden sie nicht
Der Big Data Hype ist vorbei und auf dem Anstieg zum „ Plateau of Productivity“. Doch bereits in dieser Phase klafft die Einschätzung von Analysten mit der Verbreitung von Big Data Predictive Analytics/Data Mining noch weit von der Realität in Deutschland auseinander. Dies belegt u.a. eine Studie der T-Systems Multimedia Solutions, zu welcher in der FAZ* der Artikel Man redet gerne über Daten, genutzt werden sie nicht, erschienen ist. Mich überrascht diese Studie nicht, sondern bestätigt meine langjährige Markterfahrung.
Die Gründe sind vielfältig: keine Zeit, keine Priorität, keine Kompetenz, kein Data Scientist, keine Zuständigkeit, Software zu komplex – Daten und Use-Cases sind aber vorhanden.
Im folgenden Artikel wird die Datenanalyse- und Data-Mining Software der Synop Systems vorgestellt, welche „out-of-the-box“ alle Funktionen bereitstellt, um Daten zu verknüpfen, zu strukturieren, zu verstehen, Zusammenhänge zu entdecken, Muster in Daten zu lernen und Prognose-Modelle zu entwickeln.
Anforderung an „Advanced-Data-Analytics“-Software
Um Advanced-Data-Analytics-Software zu einer hohen Verbreitung zu bringen, sind folgende Aspekte zu beachten:
- Einfachheit in der Nutzung der Software
- Schnelligkeit in der Bearbeitung von Daten
- Analyse von großen Datenmengen
- Große Auswahl an vorgefertigten Analyse-Methoden für unterschiedliche Fragestellungen
- Nutzung (fast) ohne IT-Projekt
- Offene Architektur für Data-Automation und Integration in operative Prozesse
Synop Analyzer – Pionier der In-Memory Analyse
Um diese Anforderungen zu erfüllen, entstand der Synop Analyzer, welcher seit 2013 von der Synop Systems in den Markt eingeführt wird. Im Einsatz ist die Software bei einem DAX-Konzern bereits seit 2010 und zählt somit zum Pionier einer In-Memory-basierenden Data-Mining Software in Deutschland. Synop Analyzer hat besondere Funktionen für technische Daten. Anwender der Software sind aber in vielen Branchen zu finden: Automotive, Elektronik, Maschinenbau, Payment Service Provider, Handel, Versandhandel, Marktforschung.
Die wesentlichen Kernfunktionen des Synop Analyzer sind:
a. Eigene In-Memory-Datenhaltung:
Optimiert für große Datenmengen und analytische Fragestellungen. Ablauffähig auf jedem Standard-Rechner können Dank der spaltenbasierenden Datenhaltung und der Komprimierung große Datenmengen sehr schnell analysiert werden. Das Einlesen der Daten erfolgt direkt aus Datenbanktabellen der Quellsysteme oder per Excel, CSV, Json oder XML. Unterschiedliche Daten können verknüpf und synchronisiert werden. Hohe Investitionen für Big-Data-Datenbanken entfallen somit. Eine Suche von Mustern von diagnostic error codes (dtc), welche mind. 300 Mal (Muster) innerhalb 100 Mio. Datenzeilen vorkommen, dauert auf einem I5-Proz. ca. 1200 Sek., inkl. Ausgabe der Liste der Muster. Ein Prognosemodel mittels Naive-Bayes für das Produkt „Kreditkarte“ auf 800 Tsd. Datensätzen wird in ca. 3 Sek. berechnet.
b. Vielzahl an Analyse-Methoden
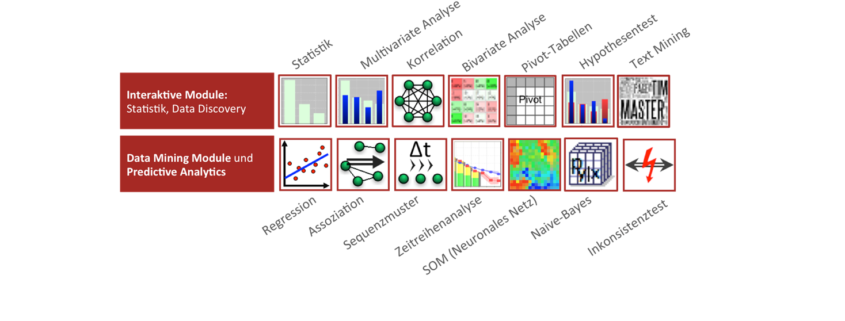
Um eine hohe Anzahl an Fragestellungen zu beantworten, hat der Synop Analyzer eine Vielzahl an vorkonfigurierten Analyse- und Data-Mining-Verfahren (siehe Grafik) implementiert. Daten zu verstehen wird durch Datenvisualisierung stark vereinfacht. Die multivariate Analyse ist quasi interaktives Data-Mining, welches auch von Fachanwendern schnell genutzt wird. Ad hoc Fragen werden unmittelbar beantwortet – es entstehen aber auch neue Fragen dank der interaktiven Visualisierungen. Data-Mining-Modelle errechnen und deren Modellgüte durch eine Testgruppe zu validieren ist in wenigen Minuten möglich. Dank der Performance der In-Memory-Analyse können lange Zeitreihen und alle sinnvollen Datenmerkmale in die Berechnungen einfließen. Dadurch werden mehr Einflussgrößen erkannt und bessere Modelle errechnet. Mustererkennung ist kein Hokuspokus, sondern Dank der exzellenten Trennschärfe werden nachvollziehbare, signifikante Muster gefunden. Dateninkonsistenzen werden quasi per Knopfdruck identifiziert.

c. Interaktives User Interface
Sämtliche Analyse-Module sind interaktiv und ohne Programmierung zu nutzen. Direkt nach dem Einlesen werden Grafiken automatisiert, ohne Datenmodellierung, erstellt. Schulung ist kaum oder minimal notwendig und Anwender können erstmals fundierte statistische Analysen und Data-Mining in wenigen Schritten umsetzen. Data-Miner und Data Scientisten ersparen sich viel Zeit und können sich mehr auf die Interpretation und Ableitung von Handlungsmaßnahmen fokussieren.
d. Einfacher Einstieg – modular und mitwachsend
Der Synop Analyzer ist in unterschiedlichen Versionen verfügbar:
– Desktop-Version: in dieser Version sind alle Kernfunktionen in einer Installation kombiniert. In wenigen Minuten mit den Standard-Betriebssystemen MS-Windows, Apple Mac, Linux installiert. Außer Java-Runtime ist keine weitere Software notwendig. Somit fast, je nach Rechte am PC, ohne IT-Abt. installierbar. Ideal zum Einstieg und Testen, für Data Labs, Abteilungen und für kleine Unternehmen.
– Client/Server-Version: In dieser Version befinden die Analyse-Engines und die Datenhaltung auf dem Server. Das User-Interface ist auf dem Rechner des Anwenders installiert. Eine Cloud-Version ist demnächst verfügbar. Für größere Teams von Analysten mit definierten Zielen.
– Sandbox-Version: entspricht der C/S-Server Version, doch das User-Interface wird spezifisch auf einen Anwenderkreis oder einen Anwendungsfall bereitgestellt. Ein typischer Anwendungsfall ist, dass gewisse Fachbereiche oder Data Science-Teams eine Daten-Sandbox erhalten. In dieser Sandbox werden frei von klassischen BI-Systemen, Ad-hoc Fragen beantwortet und proaktive Analysen erstellt. Die Daten werden per In-Memory-Instanzen bereitgestellt.
Fazit: Mit dem Synop Analyzer erhalten Unternehmen die Möglichkeit Daten sofort zu analysieren. Aus vorhandenen Daten wird neues Wissen mit bestehenden Ressourcen gewonnen! Der Aufwand für die Einführung ist minimal. Der Preis für die Software liegt ja nach Ausstattung zw. 2.500 Euro und 9.500 Euro. Welche Ausrede soll es jetzt noch geben?
Nur wer früh beginnt, lernt die Hürden und den Nutzen von Datenanalyse und Data-Mining kennen. Zu Beginn wird der Reifegrad klein sein: Datenqualität ist mäßig, Datenzugriffe sind schwierig. Wie in anderen Disziplinen gilt auch hier: Übung macht den Meister und ein Meister ist noch nie von Himmel gefallen.