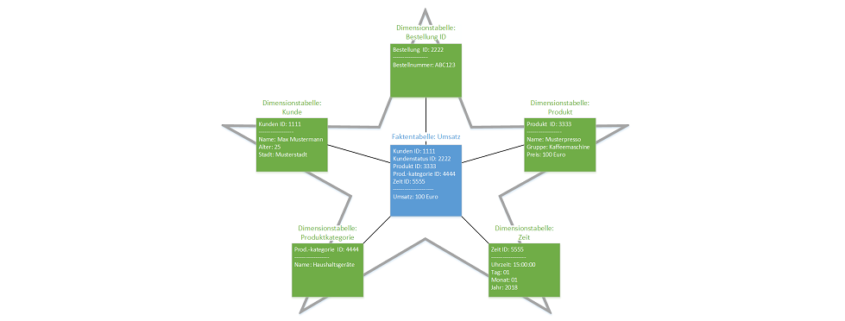
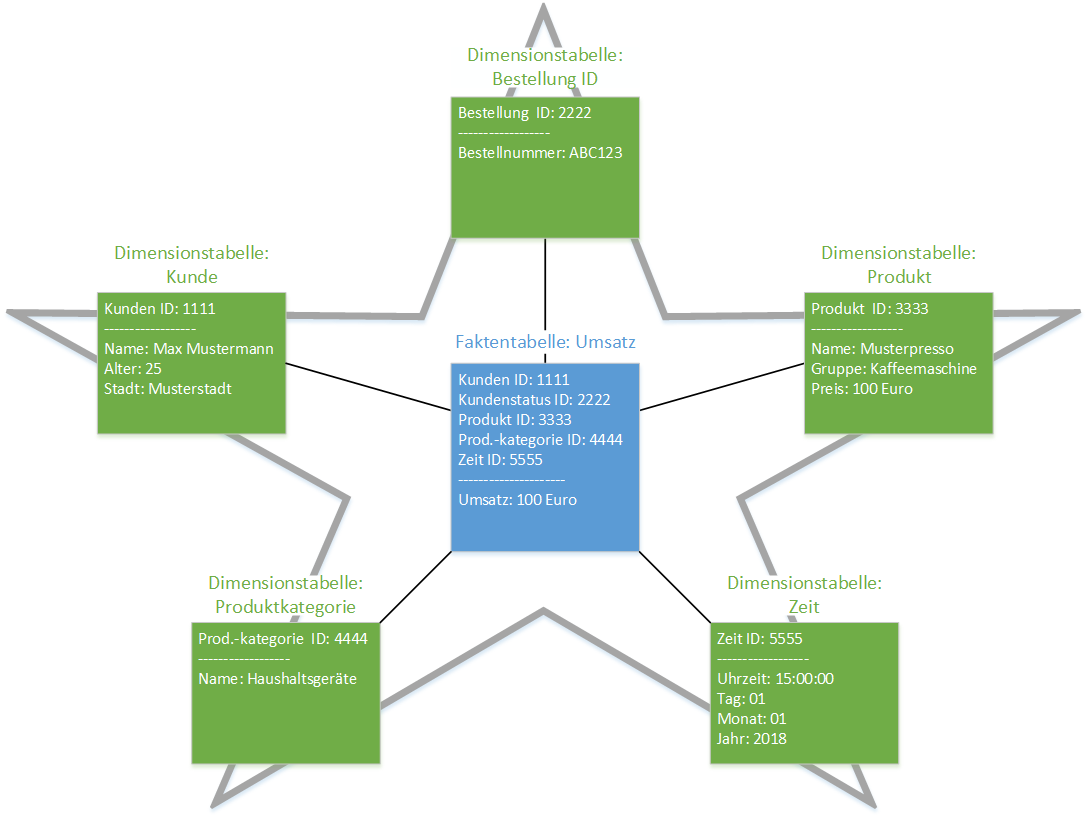
From BI to PI: The Next Step in the Evolution of Data-Driven Decisions
“Change is a constant.” “The pace of change is accelerating.” “The world is increasingly complex, and businesses have to keep up.” Organizations of all shapes and sizes have heard these ideas over and over—perhaps too often! However, the truth remains that adaptation is crucial to a successful business.
Of course, the only way to ensure that the decisions you make are evolving in the right way is to understand the underlying building blocks of your organization. You can think of it as DNA; the business processes that underpin the way you work and combine to create a single unified whole. Knowing how those processes operate, and where the opportunities for improvement lie, can be the difference between success and failure.
Businesses with an eye on their growth understand this already. In the past, Business Intelligence was seen as the solution to this challenge. In more recent times, forward-thinking organizations see the need for monitoring solutions that can keep up with today’s rate of change, at the same time as they recognize that increasing complexity within business processes means traditional methods are no longer sufficient.
Adapting to a changing environment? The challenges of BI
Business Intelligence itself is not necessarily defunct or obsolete. However, the tools and solutions that enable Business Intelligence face a range of challenges in a fast-paced and constantly changing world. Some of these issues may include:
- High data latency – Data latency refers to how long it takes for a business user to retrieve data from, for example, a business intelligence dashboard. In many cases, this can take more than 24 hours, a critical time period when businesses are attempting to take advantage of opportunities that may have a limited timeframe.
- Incomplete data sets – The broad approach of Business Intelligence means investigations may run wide but not deep. This increases the chances that data will be missed, especially in instances where the tools themselves make the parameters for investigations difficult to change.
- Discovery, not analysis – Business intelligence tools are primarily optimized for exploration, with a focus on actually finding data that may be useful to their users. Often, this is where the tools stop, offering no simple way for users to actually analyze the data, and therefore reducing the possibility of finding actionable insights.
- Limited scalability – In general, Business Intelligence remains an arena for specialists and experts, leaving a gap in understanding for operational staff. Without a wide appreciation for processes and their analysis within an organization, the opportunities to increase the application of a particular Business Intelligence tool will be limited.
- Unconnected metrics – Business Intelligence can be significantly restricted in its capacity to support positive change within a business through the use of metrics that are not connected to the business context. This makes it difficult for users to interpret and understand the results of an investigation, and apply these results to a useful purpose within their organization.
Process Intelligence: the next evolutionary step
To ensure companies can work efficiently and make the best decisions, a more effective method of process discovery is needed. Process Intelligence (PI) provides the critical background to answer questions that cannot be answered with Business Intelligence tools.
Process Intelligence offers visualization of end-to-end process sequences using raw data, and the right Process Intelligence tool means analysis of that raw data can be conducted straight away, so that processes are displayed accurately. The end-user is free to view and work with this accurate information as they please, without the need to do a preselection for the analysis.
By comparison, because Business Intelligence requires predefined analysis criteria, only once the criteria are defined can BI be truly useful. Organizations can avoid delayed analysis by using Process Intelligence to identify the root causes of process problems, then selecting the right criteria to determine the analysis framework.
Then, you can analyze your system processes and see the gaps and variants between the intended business process and what you actually have. And of course, the faster you discover what you have, the faster you can apply the changes that will make a difference in your business.
In short, Business Intelligence is suitable for gaining a broad understanding of the way a business usually functions. For some businesses, this will be sufficient. For others, an overview is not enough.
They understand that true insights lie in the detail, and are looking for a way of drilling down into exactly how each process within their organization actually works. Software that combines process discovery, process analysis, and conformance checking is the answer.
The right Process Intelligence tools means you will be able to automatically mine process models from the different IT systems operating within your business, as well as continuously monitor your end-to-end processes for insights into potential risks and ongoing improvement opportunities. All of this is in service of a collaborative approach to process improvement, which will lead to a game-changing understanding of how your business works, and how it can work better.
Early humans evolved from more primitive ancestors, and in the process, learned to use more and more sophisticated tools. For the modern human, working in a complex organization, the right tool is Process Intelligence.
Endless Potential with Signavio Process Intelligence
Signavio Process Intelligence allows you to unearth the truth about your processes and make better decisions based on true evidence found in your organization’s IT systems. Get a complete end-to-end perspective and understanding of exactly what is happening in your organization in a matter of weeks.
As part of Signavio Business Transformation Suite, Signavio Process Intelligence integrates perfectly with Signavio Process Manager and is accessible from the Signavio Collaboration Hub. As an entirely cloud-based process mining solution, the tool makes it easy to collaborate with colleagues from all over the world and harness the wisdom of the crowd.
Find out more about Signavio Process Intelligence, and see how it can help your organization generate more ideas, save time and money, and optimize processes.

 Ross Perez is the Senior Director, Marketing EMEA at
Ross Perez is the Senior Director, Marketing EMEA at 
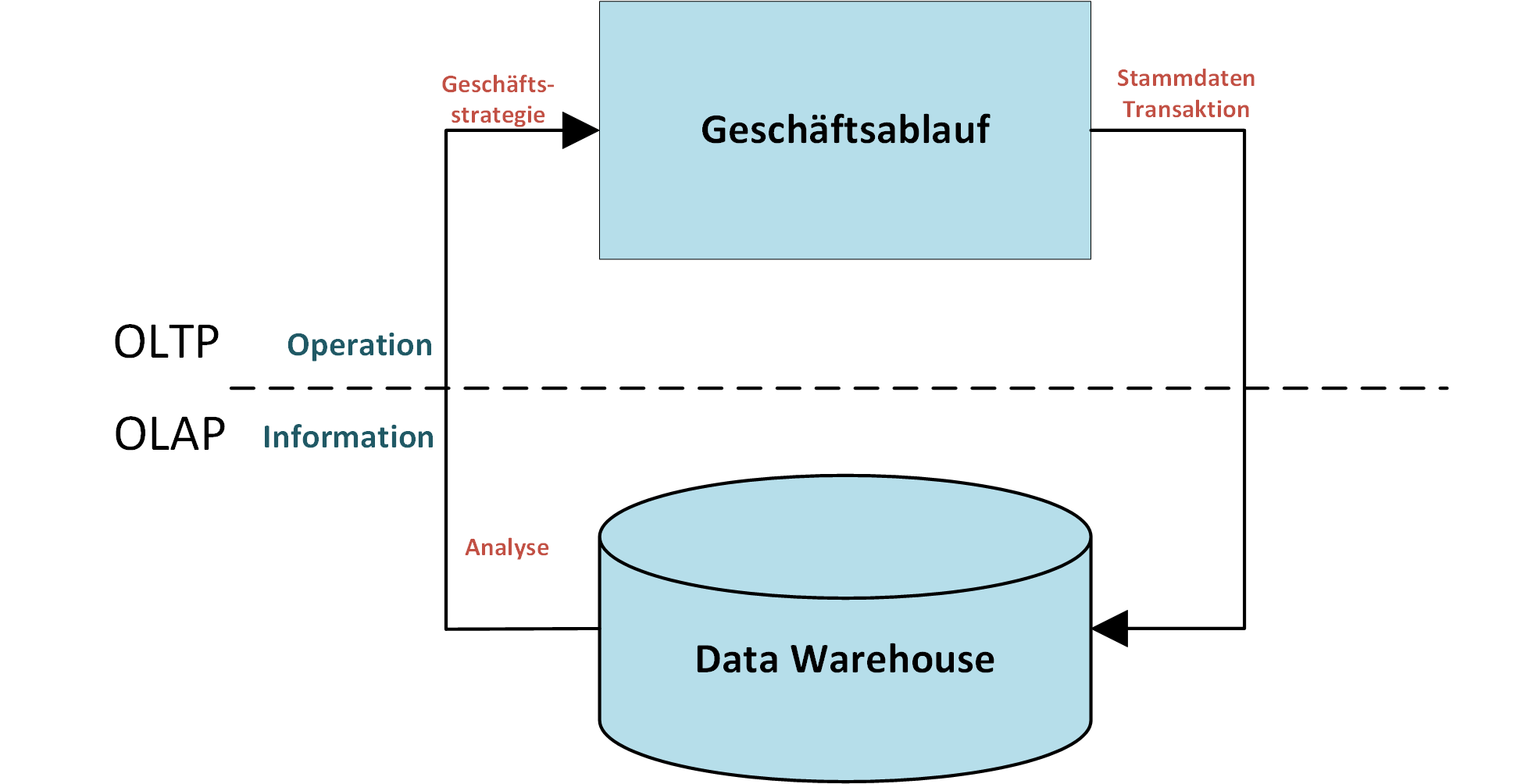

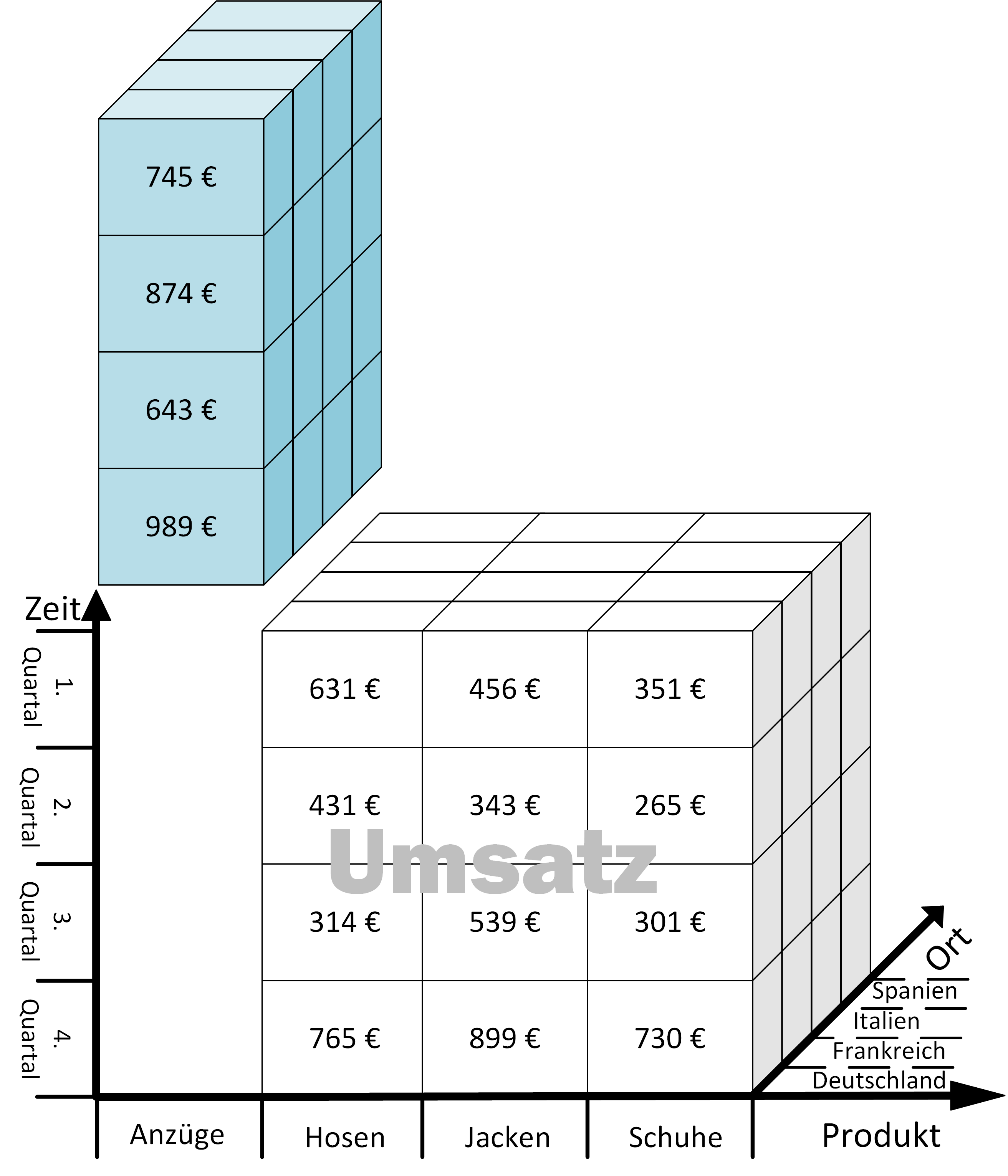
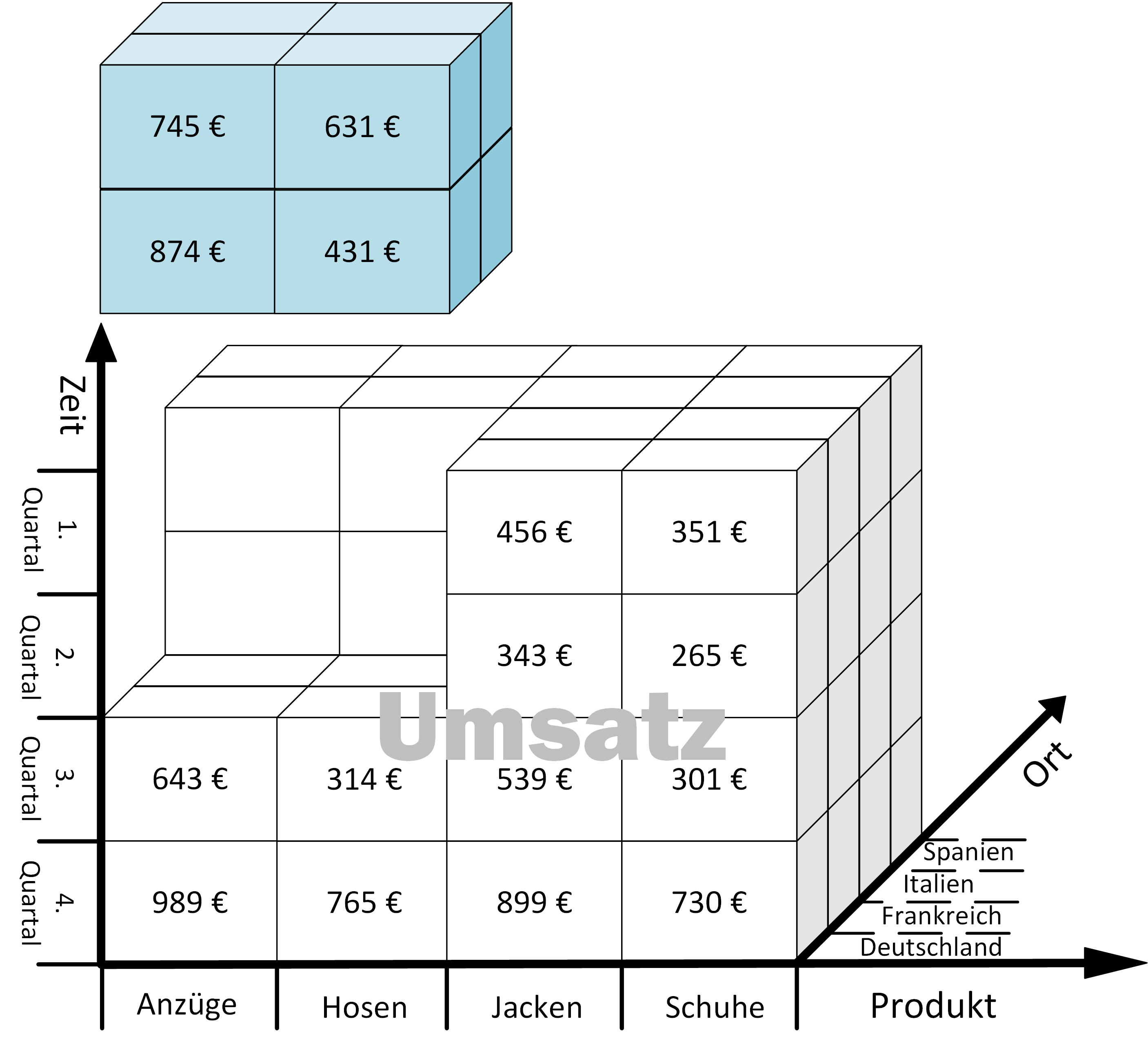
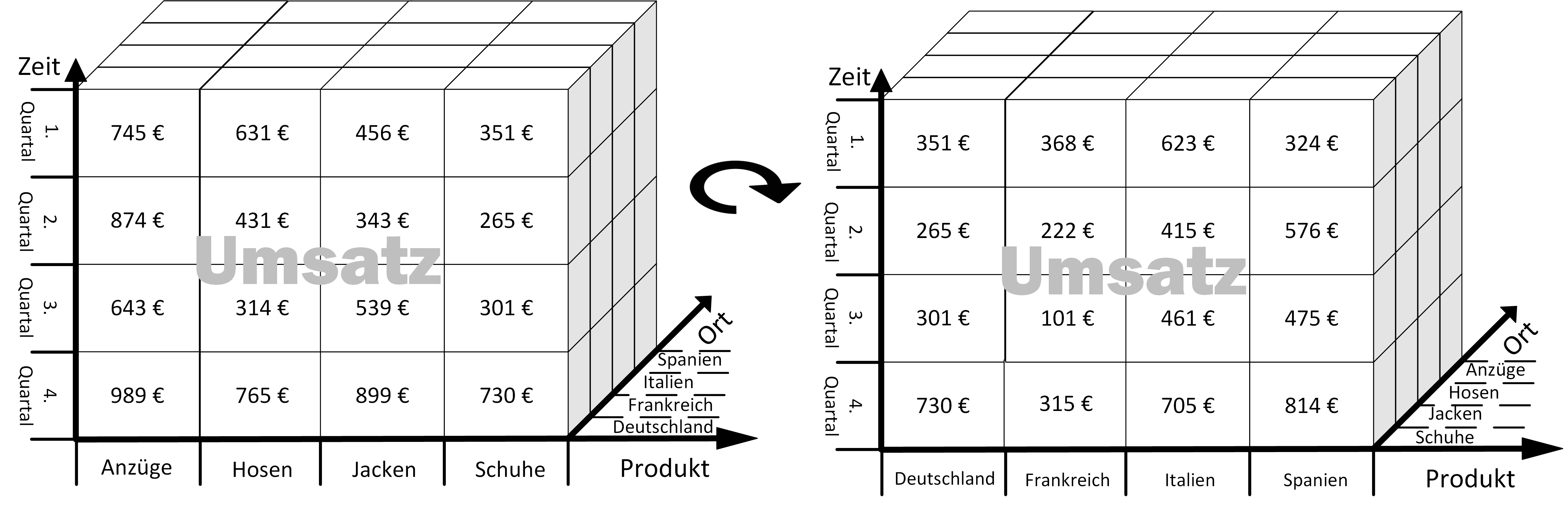
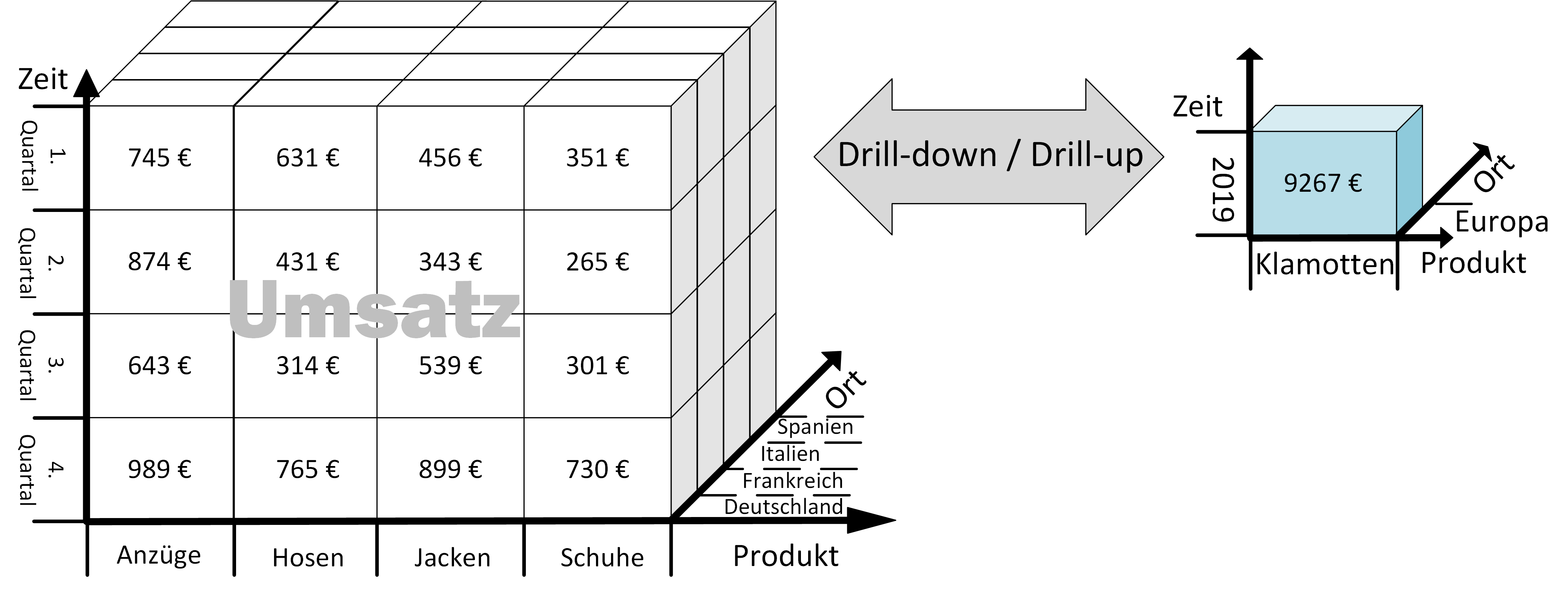
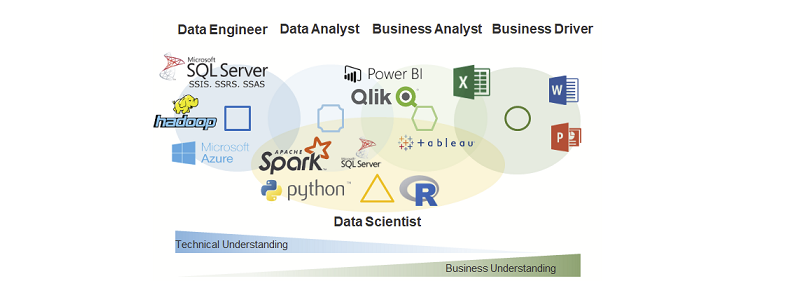

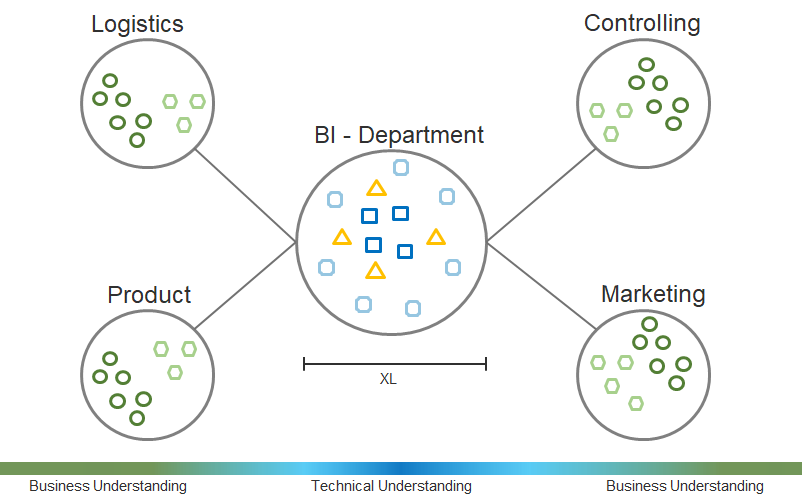
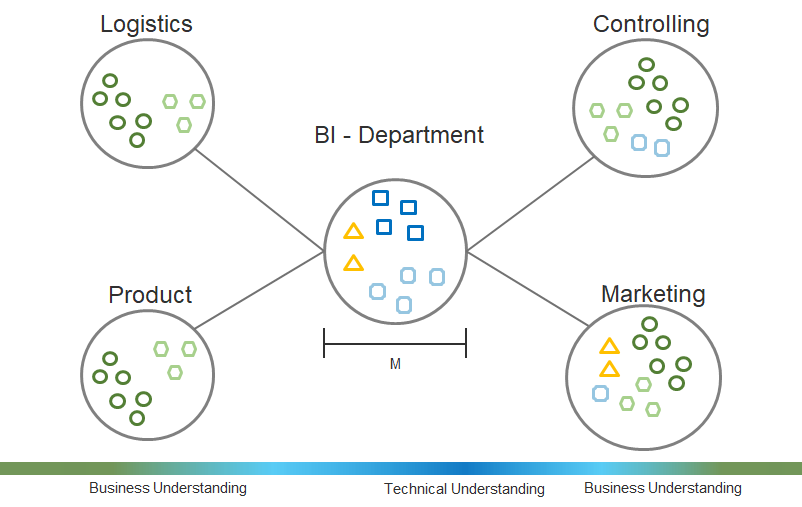





 Prof. Dr. Carsten Felden ist Vorsitzender des Vorstandes des TDWI e.V., der größten Community für Analytics und Buisness Intelligence.. Er ist selbst Experte und Consultant für Business Intelligence und für diesen Fachbereich Lehrstuhlinhaber an der TU Bergakademie Freiberg.
Prof. Dr. Carsten Felden ist Vorsitzender des Vorstandes des TDWI e.V., der größten Community für Analytics und Buisness Intelligence.. Er ist selbst Experte und Consultant für Business Intelligence und für diesen Fachbereich Lehrstuhlinhaber an der TU Bergakademie Freiberg.