
Glorious career paths of a Big Data Professional
Are you wondering about the career profiles you may get to fill if you get into Big Data industry? If yes, then Bingo! This is the post that will inform you just about that. Big data is just an umbrella term. There are a lot of profiles and career paths that are covered under this umbrella term. Let us have a look at some of these profiles.
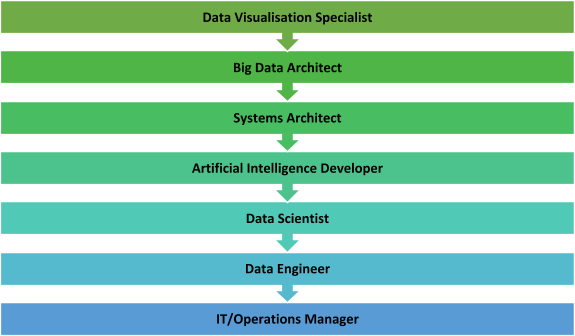
Data Visualisation Specialist
The process of visualizing data is turning out to be critical in guaranteeing information-driven representatives get the upfront investment required to actualize goal-oriented and significant Big Data extends in their organization. Making your data to tell a story and the craft of envisioning information convincingly has turned into a significant piece of the Big Data world and progressively associations need to have these capacities in-house. Besides, as a rule, these experts are relied upon to realize how to picture in different instruments, for example, Spotfire, D3, Carto, and Tableau – among numerous others. Information Visualization Specialists should be versatile and inquisitive to guarantee they stay aware of most recent patterns and answers for a recount to their information stories in the most intriguing manner conceivable with regards to the board room.
Big Data Architect
This is the place the Hadoop specialists come in. Ordinarily, a Big Data planner tends to explicit information issues and necessities, having the option to portray the structure and conduct of a Big Data arrangement utilizing the innovation wherein they practice – which is, as a rule, mostly Hadoop.
These representatives go about as a significant connection between the association (and its specific needs) and Data Scientists and Engineers. Any organization that needs to assemble a Big Data condition will require a Big Data modeler who can serenely deal with the total lifecycle of a Hadoop arrangement – including necessity investigation, stage determination, specialized engineering structure, application plan, and advancement, testing the much-dreaded task of deploying lastly.
Systems Architect
This Big data professional is in charge of how your enormous information frameworks are architected and interconnected. Their essential incentive to your group lies in their capacity to use their product building foundation and involvement with huge scale circulated handling frameworks to deal with your innovation decisions and execution forms. You’ll need this individual to construct an information design that lines up with the business, alongside abnormal state anticipating the improvement. The person in question will consider different limitations, adherence to gauges, and varying needs over the business.
Here are some responsibilities that they play:
-
- Determine auxiliary prerequisites of databases by investigating customer tasks, applications, and programming; audit targets with customers and assess current frameworks.
- Develop database arrangements by planning proposed framework; characterize physical database structure and utilitarian abilities, security, back-up and recuperation particulars.
- Install database frameworks by creating flowcharts; apply ideal access methods, arrange establishment activities, and record activities.
- Maintain database execution by distinguishing and settling generation and application advancement issues, figuring ideal qualities for parameters; assessing, incorporating, and putting in new discharges, finishing support and responding to client questions.
- Provide database support by coding utilities, reacting to client questions, and settling issues.
Artificial Intelligence Developer
The certain promotion around Artificial Intelligence is additionally set to quicken the number of jobs publicized for masters who truly see how to apply AI, Machine Learning, and Deep Learning strategies in the business world. Selection representatives will request designers with broad learning of a wide exhibit of programming dialects which loan well to AI improvement, for example, Lisp, Prolog, C/C++, Java, and Python.
All said and done; many people estimate that this popular demand for AI specialists could cause a something like what we call a “Brain Drain” organizations poaching talented individuals away from the universe of the scholarly world. A month ago in the Financial Times, profound learning pioneer and specialist Yoshua Bengio, of the University of Montreal expressed: “The industry has been selecting a ton of ability — so now there’s a lack in the scholarly world, which is fine for those organizations. However, it’s not extraordinary for the scholarly world.” It ; howeverusiasm to perceive how this contention among the scholarly world and business is rotated in the following couple of years.
Data Scientist
The move of Big Data from tech publicity to business reality may have quickened, yet the move away from enrolling top Data Scientists isn’t set to change in 2020. An ongoing Deloitte report featured that the universe of business will require three million Data Scientists by 2021, so if their expectations are right, there’s a major ability hole in the market. This multidisciplinary profile requires specialized logical aptitudes, specialized software engineering abilities just as solid gentler abilities, for example, correspondence, business keenness, and scholarly interest.
Data Engineer
Clean and quality data is crucial in the accomplishment of Big Data ventures. Consequently, we hope to see a lot of opening in 2020 for Data Engineers who have a predictable and awesome way to deal with information transformation and treatment. Organizations will search for these special data masters to have broad involvement in controlling data with SQL, T-SQL, R, Hadoop, Hive, Python and Spark. Much like Data Scientists. They are likewise expected to be innovative with regards to contrasting information with clashing information types with have the option to determine issues. They additionally frequently need to make arrangements which enable organizations to catch existing information in increasingly usable information groups – just as performing information demonstrations and their modeling.
IT/Operations Manager Job Description
In Big data industry, the IT/Operations Manager is a profitable expansion to your group and will essentially be in charge of sending, overseeing, and checking your enormous information frameworks. You’ll depend on this colleague to plan and execute new hardware and administrations. The person in question will work with business partners to comprehend the best innovation ventures to address their procedures and concerns—interpreting business necessities to innovation plans. They’ll likewise work with venture chiefs to actualize innovation and be in charge of effective progress and general activities.
Here are some responsibilities that they play:
- Manage and be proactive in announcing, settling and raising issues where required
- Lead and co-ordinate issue the executive’s exercises, notwithstanding ceaseless procedure improvement activities
- Proactively deal with our IT framework
- Supervise and oversee IT staffing, including enrollment, supervision, planning, advancement, and assessment
- Verify existing business apparatuses and procedures remain ideally practical and worth included
- Benchmark, dissect, report on and make suggestions for the improvement and development of the IT framework and IT frameworks
- Advance and keep up a corporate SLA structure
Conclusion
These are some of the best career paths that big data professionals can play after entering the industry. Honesty and hard work can always take you to the zenith of any field that you choose to be in. Also, keep upgrading your skills by taking newer certifications and technologies. Good Luck










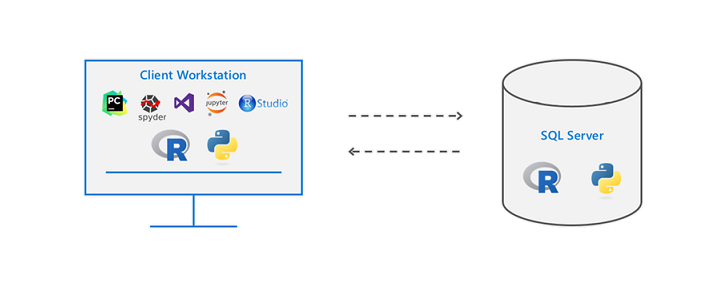
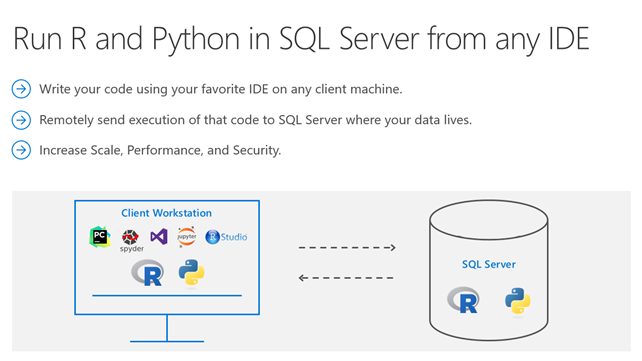
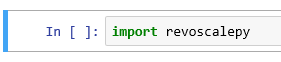

 Alice Albrecht ist Research Engineer bei
Alice Albrecht ist Research Engineer bei 


